方法和初始化器
当你身处舞池,就只有跳舞。
翁贝托·艾柯,《洛安娜女王的神秘火焰》
现在是时候让我们的虚拟机用行为来赋予它新生的对象生命了。这意味着方法和方法调用。并且,由于它们是特殊类型的方法,所以初始化器也是如此。
这一切在我们之前的 jlox 解释器中都很熟悉。这次旅行的新内容是我们将在其中实施的一个重要的优化,它将使方法调用速度比我们的基线性能快七倍以上。但在我们开始玩乐之前,我们必须让基本的东西运行起来。
28 . 1方法声明
在我们拥有方法调用之前,我们无法优化方法调用,而没有方法可调用,我们就无法调用方法,所以我们将从声明开始。
28 . 1 . 1表示方法
我们通常从编译器开始,但这次让我们先敲定对象模型。clox 中方法的运行时表示与 jlox 中的类似。每个类都存储一个方法的哈希表。键是方法名,每个值都是方法主体对应的 ObjClosure。
typedef struct {
Obj obj;
ObjString* name;
在 struct ObjClass 中
Table methods;
} ObjClass;
一个全新的类从一个空方法表开始。
klass->name = name;
在 newClass() 中
initTable(&klass->methods);
return klass;
ObjClass 结构体拥有此表的空间,因此当内存管理器释放类时,表也应该被释放。
case OBJ_CLASS: {
在 freeObject() 中
ObjClass* klass = (ObjClass*)object; freeTable(&klass->methods);
FREE(ObjClass, object);
说到内存管理器,GC 需要通过类跟踪到方法表。如果一个类仍然可访问(很可能是通过某个实例),那么它所有的方法肯定也需要保留。
markObject((Obj*)klass->name);
在 blackenObject() 中
markTable(&klass->methods);
break;
我们使用现有的 markTable() 函数,它会跟踪每个表条目中的键字符串和值。
存储类的所有方法与 jlox 中的方法非常相似。不同之处在于该表是如何填充的。我们之前的解释器可以访问类声明的整个 AST 节点及其包含的所有方法。在运行时,解释器只需遍历该声明列表。
现在编译器想要传递给运行时的所有信息都必须通过一系列扁平的字节码指令的接口挤进来。我们如何将一个类声明(它可以包含任意数量的方法)表示为字节码?让我们跳到编译器去看看。
28 . 1 . 2编译方法声明
上一章让我们得到了一个解析类但只允许空主体的编译器。现在我们插入一点代码来编译大括号之间的一系列方法声明。
consume(TOKEN_LEFT_BRACE, "Expect '{' before class body.");
在 classDeclaration() 中
while (!check(TOKEN_RIGHT_BRACE) && !check(TOKEN_EOF)) { method(); }
consume(TOKEN_RIGHT_BRACE, "Expect '}' after class body.");
Lox 没有字段声明,因此类主体末尾的闭合大括号之前的任何东西都必须是方法。当我们遇到最终的 curly 或者到达文件末尾时,我们停止编译方法。后一种检查确保我们的编译器在用户不小心忘记闭合大括号的情况下不会陷入无限循环。
编译类声明的棘手之处在于一个类可以声明任意数量的方法。无论如何,运行时都需要查找并绑定所有这些方法。如果要将所有这些内容打包到单个 OP_CLASS 指令中,那将是一件很麻烦的事情。相反,我们为类声明生成的字节码将把该过程拆分为一个系列指令。编译器已经发出了一个 OP_CLASS 指令,它会创建一个新的空 ObjClass 对象。然后它发出指令将该类存储在一个带有其名称的变量中。
现在,对于每个方法声明,我们发出一个新的 OP_METHOD 指令,它会将一个方法添加到该类中。当所有 OP_METHOD 指令都执行完毕后,我们将得到一个完整的类。虽然用户将类声明视为一个原子操作,但 VM 将其实现为一系列变异。
为了定义一个新的方法,VM 需要三样东西
-
方法的名称。
-
方法体对应的闭包。
-
要将方法绑定到的类。
我们将逐步编写编译器代码来了解它们是如何传递到运行时的,从这里开始
在 function() 之后添加
static void method() { consume(TOKEN_IDENTIFIER, "Expect method name."); uint8_t constant = identifierConstant(&parser.previous); emitBytes(OP_METHOD, constant); }
就像 OP_GET_PROPERTY 和其他在运行时需要名称的指令一样,编译器将方法名称标记的词素添加到常量表中,并获得一个表索引。然后我们发出一个 OP_METHOD 指令,该指令以该索引作为操作数。那就是名称。接下来是方法体
uint8_t constant = identifierConstant(&parser.previous);
在 method() 中
FunctionType type = TYPE_FUNCTION; function(type);
emitBytes(OP_METHOD, constant);
我们使用与编译函数声明时编写的相同的 function() 辅助函数。该实用函数会编译后续的参数列表和函数体。然后它发出代码来创建 ObjClosure 并将其留在堆栈顶部。在运行时,VM 会在那里找到闭包。
最后是绑定方法的类。VM 在哪里可以找到它?不幸的是,当我们到达 OP_METHOD 指令时,我们不知道它在哪里。它可能在堆栈上,如果用户在局部范围内声明了该类。但是,顶层类声明最终会将 ObjClass 放入全局变量表中。
不要害怕。编译器确实知道类的名称。我们可以在消费其标记之后立即捕获它。
consume(TOKEN_IDENTIFIER, "Expect class name.");
在 classDeclaration() 中
Token className = parser.previous;
uint8_t nameConstant = identifierConstant(&parser.previous);
而且我们知道没有其他具有相同名称的声明可能隐藏该类。所以我们采取了简单的解决方法。在开始绑定方法之前,我们发出将该类重新加载到堆栈顶部的任何必要代码。
defineVariable(nameConstant);
在 classDeclaration() 中
namedVariable(className, false);
consume(TOKEN_LEFT_BRACE, "Expect '{' before class body.");
在编译类主体之前,我们调用 namedVariable()。该辅助函数生成代码以将具有给定名称的变量加载到堆栈中。然后我们编译方法。
这意味着,当我们执行每个 OP_METHOD 指令时,堆栈上最上面是方法的闭包,在它的下面是类。一旦我们到达方法的末尾,我们就不再需要该类,并告诉 VM 将其从堆栈中弹出。
consume(TOKEN_RIGHT_BRACE, "Expect '}' after class body.");
在 classDeclaration() 中
emitByte(OP_POP);
}
将所有这些放在一起,这里有一个要扔给编译器的示例类声明
class Brunch { bacon() {} eggs() {} }
鉴于此,以下是编译器生成的代码以及这些指令如何在运行时影响堆栈
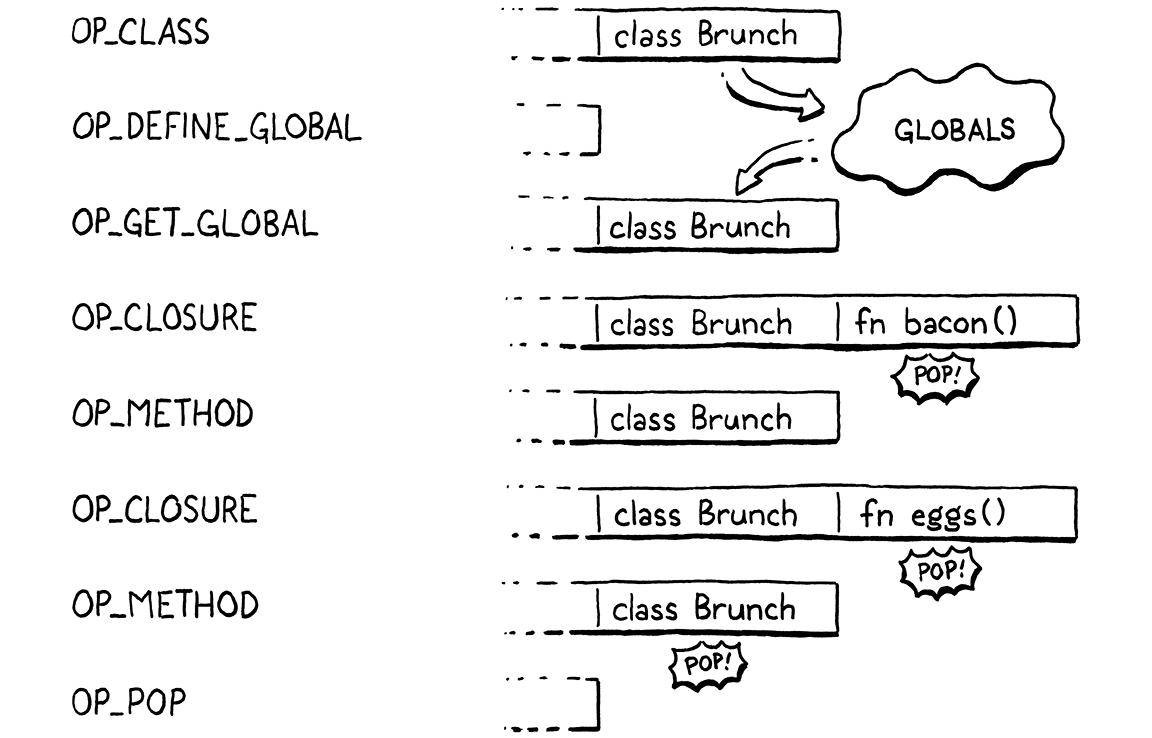
剩下要做的就是实现该新 OP_METHOD 指令的运行时。
28 . 1 . 3执行方法声明
首先,我们定义操作码。
OP_CLASS,
在 enum OpCode 中
OP_METHOD
} OpCode;
我们像其他具有字符串常量操作数的指令一样对其进行反汇编。
case OP_CLASS:
return constantInstruction("OP_CLASS", chunk, offset);
在 disassembleInstruction() 中
case OP_METHOD: return constantInstruction("OP_METHOD", chunk, offset);
default:
在解释器中,我们也添加一个新案例。
break;
在 run() 中
case OP_METHOD: defineMethod(READ_STRING()); break;
}
在那里,我们从常量表中读取方法名并将其传递到这里
在 closeUpvalues() 之后添加
static void defineMethod(ObjString* name) { Value method = peek(0); ObjClass* klass = AS_CLASS(peek(1)); tableSet(&klass->methods, name, method); pop(); }
方法闭包位于堆栈顶部,在它上面是将要绑定它的类。我们读取这两个堆栈槽并将闭包存储在类的 method 表中。然后我们将闭包弹出,因为我们已经完成了它。
请注意,我们没有对闭包或类对象进行任何运行时类型检查。AS_CLASS() 调用是安全的,因为编译器本身生成了导致类出现在该堆栈槽中的代码。VM 信任 自己的编译器。
在完成一系列 OP_METHOD 指令之后,OP_POP 弹出该类,我们将得到一个带有完美填充的方法表的类,它已经准备开始工作。下一步是将这些方法拉回来并使用它们。
28 . 2方法引用
大多数情况下,方法会被访问并立即调用,从而导致以下熟悉的语法
instance.method(argument);
但请记住,在 Lox 和一些其他语言中,这两个步骤是不同的,可以分开进行。
var closure = instance.method; closure(argument);
由于用户可以分离操作,因此我们必须分别实现它们。第一步是使用我们现有的点状属性语法访问在实例的类上定义的方法。这应该返回某种对象,用户可以像函数一样调用它。
显而易见的方法是在类的 method 表中查找方法并返回与该名称关联的 ObjClosure。但是我们还需要记住,当你访问一个方法时,this 会绑定到访问该方法的实例。以下是我们在 jlox 中添加方法时的示例
class Person { sayName() { print this.name; } } var jane = Person(); jane.name = "Jane"; var method = jane.sayName; method(); // ?
这应该打印“Jane”,因此 .sayName 返回的对象在稍后被调用时,需要以某种方式记住它被访问的实例。在 jlox 中,我们使用解释器现有的堆分配的 Environment 类来实现这种“记忆”,该类处理所有变量存储。
我们的字节码虚拟机在存储状态方面有更复杂的架构。 局部变量和临时变量 存储在栈上, 全局变量 存储在哈希表中,而闭包中的变量使用 upvalues。 因此,在 clox 中跟踪方法接收器需要一个更复杂的解决方案,并需要一种新的运行时类型。
28 . 2 . 1绑定方法
当用户执行方法访问时,我们会找到该方法的闭包,并将其包装在一个新的 “绑定方法” 对象中,该对象跟踪访问该方法的实例。 稍后可以像函数一样调用此绑定对象。 当调用时,VM 将做一些事情来连接 this 以指向方法主体内部的接收器。
以下是新的对象类型
} ObjInstance;
在 struct ObjInstance 之后添加
typedef struct { Obj obj; Value receiver; ObjClosure* method; } ObjBoundMethod;
ObjClass* newClass(ObjString* name);
它将接收器和方法闭包包装在一起。 接收器的类型是 Value,即使方法只能在 ObjInstances 上调用。 由于 VM 无需关心接收器的类型,使用 Value 意味着我们不必在将指针传递给更通用的函数时将其转换回 Value。
新结构意味着您现在已经习惯了通常的样板文件。 对象类型枚举中出现了一个新情况
typedef enum {
在枚举 ObjType 中
OBJ_BOUND_METHOD,
OBJ_CLASS,
一个用于检查值类型的宏
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
#define IS_BOUND_METHOD(value) isObjType(value, OBJ_BOUND_METHOD)
#define IS_CLASS(value) isObjType(value, OBJ_CLASS)
另一个宏用于将值转换为 ObjBoundMethod 指针
#define IS_STRING(value) isObjType(value, OBJ_STRING)
#define AS_BOUND_METHOD(value) ((ObjBoundMethod*)AS_OBJ(value))
#define AS_CLASS(value) ((ObjClass*)AS_OBJ(value))
一个用于创建新的 ObjBoundMethod 的函数
} ObjBoundMethod;
在 struct ObjBoundMethod 之后添加
ObjBoundMethod* newBoundMethod(Value receiver, ObjClosure* method);
ObjClass* newClass(ObjString* name);
这里有一个该函数的实现
在 allocateObject() 之后添加
ObjBoundMethod* newBoundMethod(Value receiver, ObjClosure* method) { ObjBoundMethod* bound = ALLOCATE_OBJ(ObjBoundMethod, OBJ_BOUND_METHOD); bound->receiver = receiver; bound->method = method; return bound; }
类似构造函数的函数只是存储给定的闭包和接收器。 当不再需要绑定方法时,我们会将其释放。
switch (object->type) {
在 freeObject() 中
case OBJ_BOUND_METHOD: FREE(ObjBoundMethod, object); break;
case OBJ_CLASS: {
绑定方法有几个引用,但它不拥有它们,所以它只释放自身。 但是,这些引用确实会被垃圾收集器跟踪。
switch (object->type) {
在 blackenObject() 中
case OBJ_BOUND_METHOD: { ObjBoundMethod* bound = (ObjBoundMethod*)object; markValue(bound->receiver); markObject((Obj*)bound->method); break; }
case OBJ_CLASS: {
这 确保 方法的句柄将接收器保留在内存中,以便当您稍后调用句柄时,this 仍然可以找到该对象。 我们还跟踪方法闭包。
所有对象支持的最后一个操作是打印。
switch (OBJ_TYPE(value)) {
在 printObject() 中
case OBJ_BOUND_METHOD: printFunction(AS_BOUND_METHOD(value)->method->function); break;
case OBJ_CLASS:
绑定方法的打印方式与函数完全相同。 从用户的角度来看,绑定方法是一个函数。 它是一个可以调用的对象。 我们不会公开 VM 使用不同的对象类型来实现绑定方法。
戴上你的 派对 帽子,因为我们刚刚到达了一个小小的里程碑。 ObjBoundMethod 是添加到 clox 的最后一个运行时类型。 您已经编写了最后一个 IS_ 和 AS_ 宏。 我们离本书结束只有几章了,我们正在接近一个完整的 VM。
28 . 2 . 2访问方法
让我们让我们的新对象类型做些事情。 使用上一章中实现的相同的“点”属性语法来访问方法。 编译器已经解析了正确的表达式并为它们发出了 OP_GET_PROPERTY 指令。 我们需要做的唯一更改是在运行时。
当属性访问指令执行时,实例位于栈顶。 该指令的工作是找到具有给定名称的字段或方法,并用访问的属性替换栈顶。
解释器已经处理了字段,因此我们只需用另一部分扩展 OP_GET_PROPERTY 案例。
pop(); // Instance.
push(value);
break;
}
在 run() 中
替换 2 行
if (!bindMethod(instance->klass, name)) { return INTERPRET_RUNTIME_ERROR; } break;
}
我们将其插入在查找接收器实例上的字段的代码之后。 字段优先于方法并覆盖方法,因此我们首先查找字段。 如果实例没有具有给定属性名称的字段,则该名称可能指的是方法。
我们获取实例的类并将其传递给新的 bindMethod() 帮助程序。 如果该函数找到一个方法,它会将该方法放在栈上并返回 true。 否则,它返回 false 以指示找不到具有该名称的方法。 由于该名称也不是字段,这意味着我们有一个运行时错误,它会中止解释器。
以下是重点内容
在 callValue() 之后添加
static bool bindMethod(ObjClass* klass, ObjString* name) { Value method; if (!tableGet(&klass->methods, name, &method)) { runtimeError("Undefined property '%s'.", name->chars); return false; } ObjBoundMethod* bound = newBoundMethod(peek(0), AS_CLOSURE(method)); pop(); push(OBJ_VAL(bound)); return true; }
首先,我们在类的 method 表中查找具有给定名称的方法。 如果我们没有找到它,我们会报告运行时错误并退出。 否则,我们会获取该方法并将其包装在一个新的 ObjBoundMethod 中。 我们从其在栈顶的家获取接收器。 最后,我们将实例弹出并用绑定方法替换栈顶。
例如
class Brunch { eggs() {} } var brunch = Brunch(); var eggs = brunch.eggs;
以下是 VM 为 brunch.eggs 表达式执行 bindMethod() 调用时发生的情况
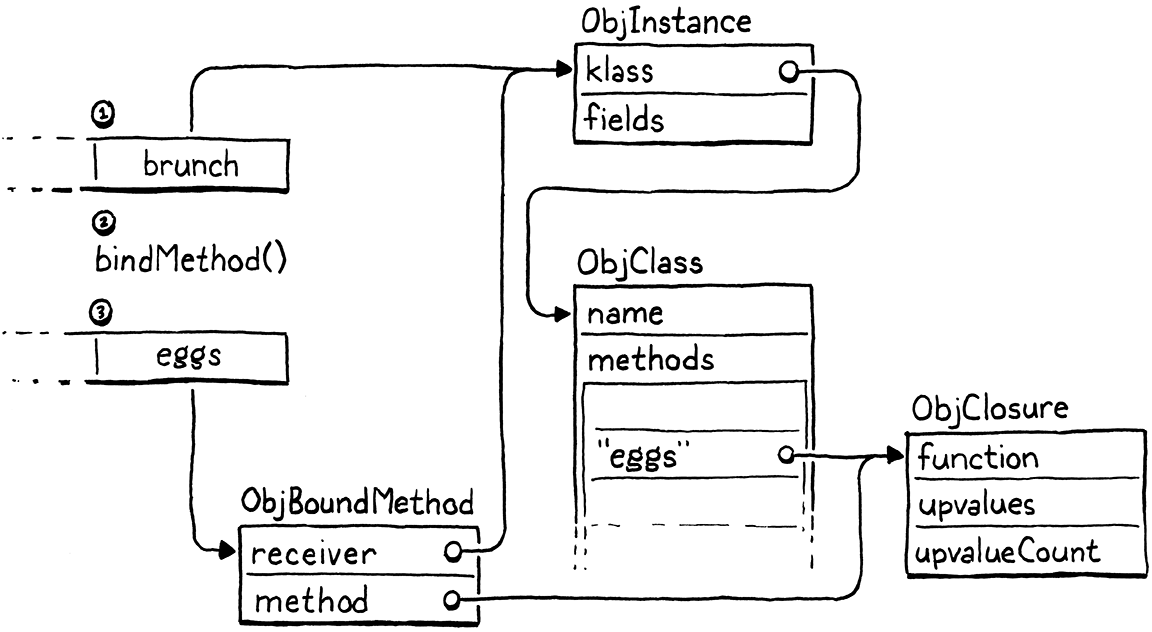
在幕后有大量的机器,但从用户的角度来看,他们只是得到了一个可以调用的函数。
28 . 2 . 3调用方法
用户可以在类上声明方法,在实例上访问它们,并将绑定方法放到栈上。 他们只是不能对这些绑定方法对象做任何有用的事情。 我们缺少的操作是调用它们。 调用是在 callValue() 中实现的,因此我们为新对象类型在那里添加了一个案例。
switch (OBJ_TYPE(callee)) {
在 callValue() 中
case OBJ_BOUND_METHOD: { ObjBoundMethod* bound = AS_BOUND_METHOD(callee); return call(bound->method, argCount); }
case OBJ_CLASS: {
我们从 ObjBoundMethod 中提取原始闭包,并使用现有的 call() 帮助程序通过将 CallFrame 推送到调用栈上开始调用该闭包。 这就是能够运行此 Lox 程序所需的全部操作
class Scone { topping(first, second) { print "scone with " + first + " and " + second; } } var scone = Scone(); scone.topping("berries", "cream");
这是三个大的步骤。 我们可以声明、访问和调用方法。 但还缺少一些东西。 我们费尽心思将方法闭包包装在一个绑定接收器的对象中,但当我们调用该方法时,我们根本没有使用该接收器。
28 . 3This
绑定方法需要保留接收器的原因是,以便可以在方法主体内部访问它。 Lox 通过 this 表达式公开方法的接收器。 是时候使用一些新的语法了。 词法分析器已经将 this 视为一种特殊的令牌类型,因此第一步是将该令牌连接到解析表中。
[TOKEN_SUPER] = {NULL, NULL, PREC_NONE},
替换 1 行
[TOKEN_THIS] = {this_, NULL, PREC_NONE},
[TOKEN_TRUE] = {literal, NULL, PREC_NONE},
当解析器在词法前缀位置遇到 this 时,它会分派到一个新的解析器函数。
在 variable() 之后添加
static void this_(bool canAssign) { variable(false); }
我们将对 clox 中的 this 应用与我们在 jlox 中使用的相同实现技术。 我们将 this 视为一个词法作用域的局部变量,其值会被神奇地初始化。 像局部变量一样编译它意味着我们免费获得了许多行为。 特别是,方法内部引用 this 的闭包将执行正确操作,并将接收器捕获到 upvalue 中。
当调用解析器函数时,this 令牌刚刚被消耗并存储为上一个令牌。 我们调用现有的 variable() 函数,该函数将标识符表达式编译为变量访问。 它接受一个布尔参数,用于指示编译器是否应该查找后面的 = 运算符并解析一个 setter。 您不能分配给 this,因此我们将 false 传递给它以禁止这样做。
variable() 函数并不关心 this 有自己的令牌类型并且不是标识符。 它很乐意将词素“this”视为变量名称,然后使用现有的作用域解析机制查找它。 现在,该查找将失败,因为我们从未声明过名为“this”的变量。 是时候考虑接收器应该在内存中的位置了。
至少在被闭包捕获之前,clox 会将每个局部变量存储在 VM 的栈上。 编译器会跟踪函数栈窗口中的哪些插槽由哪些局部变量拥有。 如果您还记得,编译器通过声明一个名为空字符串的局部变量来保留栈插槽零。
对于函数调用,该插槽最终会保存要调用的函数。 由于该插槽没有名称,因此函数主体永远不会访问它。 你可以猜到这是怎么回事。 对于方法调用,我们可以重新利用该插槽来存储接收器。 插槽零将存储 this 绑定到的实例。 为了编译 this 表达式,编译器只需要为该局部变量提供正确的名称。
local->isCaptured = false;
在 initCompiler() 中
替换 2 行
if (type != TYPE_FUNCTION) { local->name.start = "this"; local->name.length = 4; } else { local->name.start = ""; local->name.length = 0; }
}
我们只希望对方法执行此操作。 函数声明没有 this。 而且,实际上,他们不能声明一个名为“this”的变量,这样,如果您在函数声明内部(该函数声明本身位于方法内部)编写 this 表达式,则 this 将正确地解析为外部方法的接收器。
class Nested { method() { fun function() { print this; } function(); } } Nested().method();
此程序应打印“Nested instance”。 为了决定为局部插槽零指定什么名称,编译器需要知道它正在编译函数声明还是方法声明,因此我们在 FunctionType 枚举中添加了一个新案例来区分方法。
TYPE_FUNCTION,
在枚举 FunctionType 中
TYPE_METHOD,
TYPE_SCRIPT
当我们编译方法时,我们会使用该类型。
uint8_t constant = identifierConstant(&parser.previous);
在 method() 中
替换 1 行
FunctionType type = TYPE_METHOD;
function(type);
现在我们可以正确地编译对特殊“this”变量的引用,编译器将发出正确的 OP_GET_LOCAL 指令来访问它。 闭包甚至可以捕获 this 并将接收器存储在 upvalues 中。 太酷了。
除了在运行时,接收器实际上并不在插槽零中。 解释器还没有履行它的职责。 以下是修复方法
case OBJ_BOUND_METHOD: {
ObjBoundMethod* bound = AS_BOUND_METHOD(callee);
在 callValue() 中
vm.stackTop[-argCount - 1] = bound->receiver;
return call(bound->method, argCount);
}
当调用方法时,栈顶包含所有参数,然后在这些参数下方是调用的方法的闭包。 这就是新 CallFrame 中插槽零的位置。 这行代码将接收器插入到该插槽中。 例如,给定一个类似这样的方法调用
scone.topping("berries", "cream");
我们计算存储接收器的插槽,如下所示
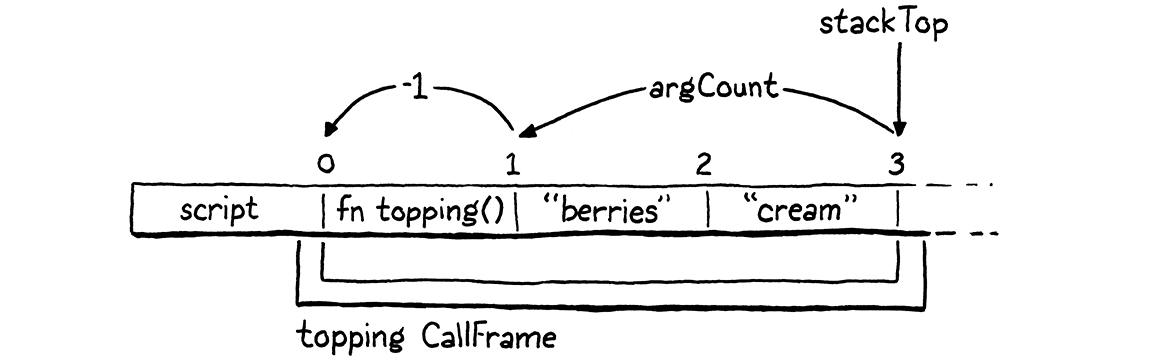
-argCount 会跳过参数,而 - 1 会调整 stackTop 指向最后一个使用过的栈插槽之后的事实。
28 . 3 . 1滥用 this
我们的 VM 现在支持用户正确使用 this,但我们还需要确保它正确处理用户误用 this 的情况。 Lox 表示,在方法主体之外出现 this 表达式是编译错误。 这些两种错误用法应该被编译器捕获
print this; // At top level. fun notMethod() { print this; // In a function. }
那么编译器如何知道它是否在方法内部呢?显而易见的答案是查看当前编译器的 FunctionType。我们确实在那里添加了一个枚举情况来专门处理方法。但是,这将无法正确处理像前面示例那样的代码,其中你位于一个函数内部,而该函数本身嵌套在方法内部。
我们可以尝试解析“this”,然后如果在任何周围的词法作用域中都没有找到它,就报告错误。这将起作用,但需要我们重新排列大量代码,因为现在解析变量的代码会隐式地将其视为全局访问,如果找不到声明。
在下一章中,我们将需要有关最近封闭类的信息。如果有,我们可以用它来确定我们是否在方法内部。所以我们不妨让未来的自己轻松一点,现在就将这个机制实现到位。
Compiler* current = NULL;
在变量 *current* 之后添加
ClassCompiler* currentClass = NULL;
static Chunk* currentChunk() {
此模块变量指向一个结构体,该结构体表示正在编译的当前最内层类。新类型如下所示
} Compiler;
在结构体 *Compiler* 之后添加
typedef struct ClassCompiler { struct ClassCompiler* enclosing; } ClassCompiler;
Parser parser;
现在,我们只存储指向封闭类的 ClassCompiler 的指针(如果有)。将类声明嵌套在另一个类的某个方法中是一种不常见的做法,但 Lox 支持它。就像 Compiler 结构体一样,这意味着 ClassCompiler 从正在编译的当前最内层类开始,一直到所有封闭类,形成一个链表。
如果我们根本不在任何类声明内部,模块变量 `currentClass` 为 `NULL`。当编译器开始编译类时,它会将一个新的 ClassCompiler 推送到那个隐式链接堆栈中。
defineVariable(nameConstant);
在 classDeclaration() 中
ClassCompiler classCompiler; classCompiler.enclosing = currentClass; currentClass = &classCompiler;
namedVariable(className, false);
ClassCompiler 结构体的内存直接位于 C 堆栈上,这是我们使用递归下降编写编译器时获得的一个方便的功能。在类主体结束时,我们将该编译器从堆栈中弹出并恢复封闭的编译器。
emitByte(OP_POP);
在 classDeclaration() 中
currentClass = currentClass->enclosing;
}
当最外层类主体结束时,`enclosing` 将为 `NULL`,因此这将 `currentClass` 重置为 `NULL`。因此,要查看我们是否在类内部——因此也在方法内部——我们只需检查该模块变量。
static void this_(bool canAssign) {
在 *this_*() 中
if (currentClass == NULL) { error("Can't use 'this' outside of a class."); return; }
variable(false);
有了它,在类外部的 `this` 将被正确禁止。现在,我们的方法在面向对象意义上真正感觉像 *方法* 了。访问接收者使它们能够影响你调用该方法的实例。我们正在接近目标!
28 . 4实例初始化器
面向对象语言将状态和行为绑定在一起的原因——这是该范式的核心原则之一——是为了确保对象始终处于有效、有意义的状态。当触碰对象状态的唯一方法是通过它的方法时,这些方法可以确保不会出现任何错误。但这假设对象 *已经* 处于适当的状态。那么,当它首次创建时呢?
面向对象语言通过构造函数确保全新对象被正确设置,构造函数既生成一个新实例,又初始化其状态。在 Lox 中,运行时分配新的原始实例,并且类可以声明一个初始化器来设置任何字段。初始化器在大多数情况下与普通方法类似,但也有一些调整
-
运行时在每次创建类的实例时会自动调用初始化器方法。
-
构造实例的调用方始终在初始化器完成后获得该实例,无论初始化器函数本身返回什么。初始化器方法不需要显式返回 `this`。
-
事实上,初始化器 *禁止* 返回任何值,因为无论如何都不会看到该值。
现在我们已经支持方法了,要添加初始化器,我们只需要实现这三个特殊规则。我们将按顺序进行。
28 . 4 . 1调用初始化器
首先,在新的实例上自动调用 `init()`
vm.stackTop[-argCount - 1] = OBJ_VAL(newInstance(klass));
在 callValue() 中
Value initializer; if (tableGet(&klass->methods, vm.initString, &initializer)) { return call(AS_CLOSURE(initializer), argCount); }
return true;
在运行时分配新的实例之后,我们在类上查找 `init()` 方法。如果找到,我们就启动对它的调用。这会为初始化器的闭包创建一个新的 CallFrame。假设我们运行了这个程序
class Brunch { init(food, drink) {} } Brunch("eggs", "coffee");
当 VM 执行对 `Brunch()` 的调用时,它会像这样执行
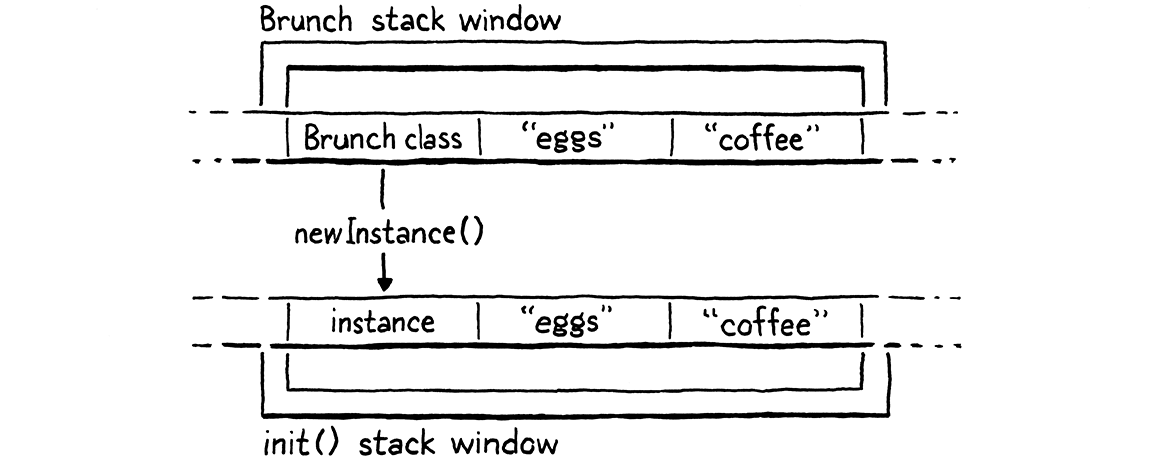
我们调用该类时传递的任何参数仍然位于实例上方的堆栈中。`init()` 方法的新 CallFrame 共享该堆栈窗口,因此这些参数隐式地被转发到初始化器。
Lox 不要求类定义初始化器。如果省略,运行时会简单地返回新的未初始化实例。但是,如果没有 `init()` 方法,那么在创建实例时向该类传递参数就没有任何意义。我们将其视为错误。
return call(AS_CLOSURE(initializer), argCount);
在 callValue() 中
} else if (argCount != 0) { runtimeError("Expected 0 arguments but got %d.", argCount); return false;
}
当类 *确实* 提供了初始化器时,我们还需要确保传递的参数数量与初始化器的元数匹配。幸运的是,`call()` 辅助函数已经为我们做到了这一点。
为了调用初始化器,运行时会按名称查找 `init()` 方法。我们希望它能够快速执行,因为它在每次构建实例时都会发生。这意味着利用我们已经实现的字符串驻留将是一件好事。为此,VM 为“init” 创建了一个 ObjString 并重复使用它。该字符串直接位于 VM 结构体中。
Table strings;
在结构体 *VM* 中
ObjString* initString;
ObjUpvalue* openUpvalues;
我们在 VM 启动时创建并驻留字符串。
initTable(&vm.strings);
在 *initVM()* 中
vm.initString = copyString("init", 4);
defineNative("clock", clockNative);
我们希望它能够一直存在,因此 GC 将其视为根。
markCompilerRoots();
在 *markRoots()* 中
markObject((Obj*)vm.initString);
}
仔细观察。看到任何可能发生的错误吗?没有?这是一个微妙的错误。垃圾收集器现在读取 `vm.initString`。该字段从调用 `copyString()` 的结果初始化。但是复制字符串会分配内存,这可能会触发 GC。如果收集器在恰好错误的时间运行,它将在初始化之前读取 `vm.initString`。因此,首先我们将该字段清零。
initTable(&vm.strings);
在 *initVM()* 中
vm.initString = NULL;
vm.initString = copyString("init", 4);
我们在 VM 关闭时清除指针,因为下一行将释放它。
freeTable(&vm.strings);
在 *freeVM()* 中
vm.initString = NULL;
freeObjects();
好的,这让我们可以调用初始化器。
28 . 4 . 2初始化器返回值
下一步是确保使用初始化器构造类的实例始终返回新实例,而不是 `nil` 或初始化器主体返回的值。现在,如果类定义了初始化器,那么在构造实例时,VM 会将对该初始化器的调用推送到 CallFrame 堆栈中。然后它会继续执行。
用户对类的调用以创建实例将在该初始化器方法返回时完成,并将该初始化器放置在堆栈上的任何值留在那里。这意味着,除非用户注意在初始化器的末尾放置 `return this;`,否则不会出现任何实例。这很不方便。
为了解决这个问题,无论何时前端编译初始化器方法,它都会在主体末尾发出不同的字节码,以从方法中返回 `this`,而不是大多数函数返回的通常的隐式 `nil`。为了做到 *这一点*,编译器需要真正知道它何时在编译初始化器。我们通过检查我们正在编译的方法的名称是否为“init” 来检测到这一点。
FunctionType type = TYPE_METHOD;
在 method() 中
if (parser.previous.length == 4 && memcmp(parser.previous.start, "init", 4) == 0) { type = TYPE_INITIALIZER; }
function(type);
我们定义了一种新的函数类型,以区分初始化器和其他方法。
TYPE_FUNCTION,
在枚举 FunctionType 中
TYPE_INITIALIZER,
TYPE_METHOD,
无论何时编译器在主体末尾发出隐式返回,我们都会检查该类型以决定是否插入特定于初始化器的行为。
static void emitReturn() {
在 *emitReturn()* 中
替换 1 行
if (current->type == TYPE_INITIALIZER) { emitBytes(OP_GET_LOCAL, 0); } else { emitByte(OP_NIL); }
emitByte(OP_RETURN);
在初始化器中,我们不会在返回之前将 `nil` 推送到堆栈中,而是加载插槽零,该插槽包含该实例。此 `emitReturn()` 函数在编译没有值的 `return` 语句时也会被调用,因此它也正确处理了用户在初始化器内部进行早期返回的情况。
28 . 4 . 3初始化器中的不正确返回值
最后一步,即我们关于初始化器特殊功能的列表中的最后一项,是让尝试从初始化器返回 *其他任何东西* 成为错误。现在编译器跟踪方法类型了,这很简单。
if (match(TOKEN_SEMICOLON)) {
emitReturn();
} else {
在 *returnStatement()* 中
if (current->type == TYPE_INITIALIZER) { error("Can't return a value from an initializer."); }
expression();
如果初始化器中的 `return` 语句有值,我们会报告错误。我们仍然会继续编译后面的值,以确保编译器不会因尾随表达式而感到困惑并报告大量级联错误。
除了我们将在不久后谈到的继承之外,我们现在在 clox 中拥有了一个功能相当齐全的类系统。
class CoffeeMaker { init(coffee) { this.coffee = coffee; } brew() { print "Enjoy your cup of " + this.coffee; // No reusing the grounds! this.coffee = nil; } } var maker = CoffeeMaker("coffee and chicory"); maker.brew();
对于一个能够装入旧的 软盘 的 C 程序来说,这真是太棒了。
28 . 5优化的调用
我们的 VM 正确地实现了该语言对方法调用和初始化器的语义。我们可以到此为止。但我们从头开始构建整个第二个 Lox 实现的主要原因是,它的执行速度比我们的旧 Java 解释器更快。现在,即使在 clox 中,方法调用也很慢。
Lox 的语义将方法调用定义为两个操作——访问方法,然后调用结果。我们的 VM 必须支持这些操作作为单独的操作,因为用户 *可以* 将它们分开。你可以访问方法而不调用它,然后稍后调用绑定方法。我们目前实现的任何内容都不是多余的。
但 *始终* 将这些操作作为单独的操作执行会带来显著的成本。每次 Lox 程序访问并调用方法时,运行时堆都会分配一个新的 ObjBoundMethod,初始化它的字段,然后立即将它们拉回来。之后,GC 必须花费时间释放所有这些短暂的绑定方法。
在大多数情况下,Lox 程序会访问一个方法,然后立即调用它。绑定方法由一个字节码指令创建,然后由下一个指令立即消耗。事实上,它非常直接,以至于编译器甚至可以从文字上 *看到* 它的发生——一个带点的属性访问,紧跟一个左括号,很可能是一个方法调用。
由于我们可以在编译时识别出这对操作,因此我们有机会发出一个 新的、特殊的 指令,执行优化的方法调用。
我们从编译带点的属性表达式的函数开始。
if (canAssign && match(TOKEN_EQUAL)) {
expression();
emitBytes(OP_SET_PROPERTY, name);
在 dot() 中
} else if (match(TOKEN_LEFT_PAREN)) { uint8_t argCount = argumentList(); emitBytes(OP_INVOKE, name); emitByte(argCount);
} else {
在编译器解析完属性名后,我们会寻找左括号。如果匹配到,我们将切换到一个新的代码路径。在那里,我们像编译调用表达式一样编译参数列表。然后,我们发出一个新的 OP_INVOKE 指令。它有两个操作数
-
属性名在常量表中的索引。
-
传递给方法的参数数量。
换句话说,这条指令将它替换的 OP_GET_PROPERTY 和 OP_CALL 指令的操作数按顺序合并在一起。它确实是这两个指令的融合。让我们定义它。
OP_CALL,
在 enum OpCode 中
OP_INVOKE,
OP_CLOSURE,
并将其添加到反汇编程序中
case OP_CALL:
return byteInstruction("OP_CALL", chunk, offset);
在 disassembleInstruction() 中
case OP_INVOKE: return invokeInstruction("OP_INVOKE", chunk, offset);
case OP_CLOSURE: {
这是一个新的特殊指令格式,因此需要一些自定义的反汇编逻辑。
添加到 constantInstruction() 之后
static int invokeInstruction(const char* name, Chunk* chunk, int offset) { uint8_t constant = chunk->code[offset + 1]; uint8_t argCount = chunk->code[offset + 2]; printf("%-16s (%d args) %4d '", name, argCount, constant); printValue(chunk->constants.values[constant]); printf("'\n"); return offset + 3; }
我们读取两个操作数,然后打印出方法名和参数计数。在解释器字节码分派循环中,真正的行动开始了。
}
在 run() 中
case OP_INVOKE: { ObjString* method = READ_STRING(); int argCount = READ_BYTE(); if (!invoke(method, argCount)) { return INTERPRET_RUNTIME_ERROR; } frame = &vm.frames[vm.frameCount - 1]; break; }
case OP_CLOSURE: {
大部分工作发生在 invoke() 中,我们将在后面介绍。在这里,我们从第一个操作数中查找方法名,然后读取参数计数操作数。然后,我们将任务交给 invoke() 进行繁重的工作。如果调用成功,该函数将返回 true。像往常一样,false 返回表示发生了运行时错误。我们在这里检查并查看是否发生了灾难,如果发生了灾难,我们将中止解释器。
最后,假设调用成功,则堆栈上有一个新的 CallFrame,因此我们刷新 frame 中缓存的当前帧副本。
有趣的工作发生在这里
在 callValue() 之后添加
static bool invoke(ObjString* name, int argCount) { Value receiver = peek(argCount); ObjInstance* instance = AS_INSTANCE(receiver); return invokeFromClass(instance->klass, name, argCount); }
首先,我们从堆栈中获取接收者。传递给方法的参数位于堆栈上的接收者之上,因此我们向下查看了那么多槽。然后,简单地将对象转换为实例并在其上调用方法。
这假设该对象确实是实例。与 OP_GET_PROPERTY 指令一样,我们还需要处理用户错误地尝试在错误类型的值上调用方法的情况。
Value receiver = peek(argCount);
在 invoke() 中
if (!IS_INSTANCE(receiver)) { runtimeError("Only instances have methods."); return false; }
ObjInstance* instance = AS_INSTANCE(receiver);
这是 一个运行时错误,因此我们报告并退出。否则,我们将获取实例的类并跳转到另一个新的实用程序函数
在 callValue() 之后添加
static bool invokeFromClass(ObjClass* klass, ObjString* name, int argCount) { Value method; if (!tableGet(&klass->methods, name, &method)) { runtimeError("Undefined property '%s'.", name->chars); return false; } return call(AS_CLOSURE(method), argCount); }
此函数结合了 VM 如何实现 OP_GET_PROPERTY 和 OP_CALL 指令的逻辑(按顺序)。首先,我们在类的 method 表中按名称查找方法。如果我们没有找到,我们会报告运行时错误并退出。
否则,我们将获取方法的闭包并将对其的调用推入 CallFrame 堆栈。我们不需要堆分配和初始化 ObjBoundMethod。事实上,我们甚至不需要处理堆栈上的任何内容。接收者和方法参数已经位于它们需要的位置。
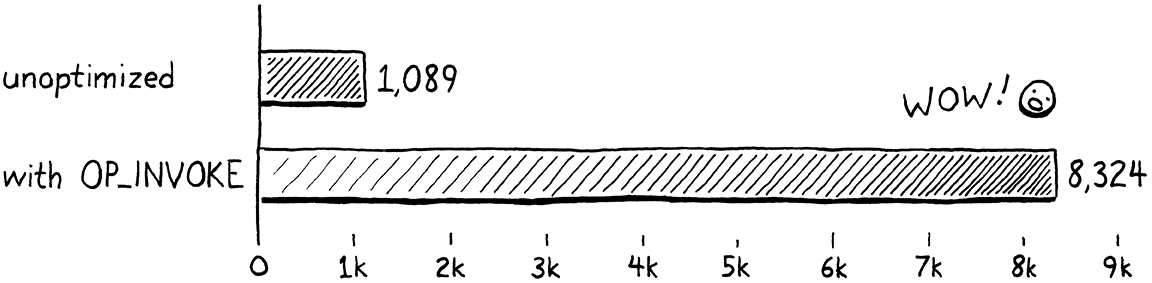
如果您启动 VM 并运行一个现在调用方法的小程序,您应该会看到与之前完全相同的行为。但是,如果我们做对了,性能应该会有很大提高。我编写了一个微型基准测试,它执行一批 10,000 次方法调用。然后,它测试在 10 秒内可以执行多少批次。在我的电脑上,没有新的 OP_INVOKE 指令,它完成了 1,089 批次。使用这种新的优化,它在相同的时间内完成了 8,324 批次。快了7.6 倍,这对于编程语言优化来说是一个巨大的改进。
28 . 5 . 1调用字段
优化的基本信条是:“你不应该破坏正确性”。用户 喜欢语言实现更快地给出答案,但前提是答案是正确的。唉,我们实现的更快方法调用未能坚持这一原则
class Oops { init() { fun f() { print "not a method"; } this.field = f; } } var oops = Oops(); oops.field();
最后一行看起来像是一个方法调用。编译器认为它是一个方法调用,并忠实地为其发出一个 OP_INVOKE 指令。然而,事实并非如此。实际上发生的是字段访问,它返回一个函数,然后调用该函数。现在,我们的 VM 并没有正确地执行此操作,而是在找不到名为“field”的方法时报告运行时错误。
早些时候,当我们实现 OP_GET_PROPERTY 时,我们处理了字段和方法访问。为了解决这个新的错误,我们需要对 OP_INVOKE 做同样的事情。
ObjInstance* instance = AS_INSTANCE(receiver);
在 invoke() 中
Value value; if (tableGet(&instance->fields, name, &value)) { vm.stackTop[-argCount - 1] = value; return callValue(value, argCount); }
return invokeFromClass(instance->klass, name, argCount);
非常简单的修复。在实例的类上查找方法之前,我们查找具有相同名称的字段。如果我们找到一个字段,那么我们将它存储在堆栈上,代替接收者,位于参数列表下方。这是 OP_GET_PROPERTY 的行为方式,因为后一个指令在后续括号括起来的参数列表被求值之前执行。
然后,我们尝试像可调用函数一样调用该字段的值,希望它是可调用函数。callValue() 辅助函数将检查值的类型,并根据需要调用它,或者如果字段的值不是可调用类型(例如闭包),则报告运行时错误。
这就是使我们的优化完全安全所需要做的。不幸的是,我们确实牺牲了一点性能。但这有时是你要付出的代价。您偶尔会因为优化而感到沮丧,如果您能消除一些令人讨厌的边缘情况,您就可以进行优化。但是,作为语言实现者,我们必须玩好我们被赋予的游戏。
我们在这里编写的代码遵循了优化中的一个典型模式
-
识别一个常见的操作或操作序列,该操作或操作序列对性能至关重要。在本例中,它是方法访问,然后是调用。
-
添加该模式的优化实现。这是我们的
OP_INVOKE指令。 -
用一些条件逻辑保护优化代码,该逻辑验证模式是否实际适用。如果适用,则保持在快速路径上。否则,回退到更慢但更健壮的未优化行为。这里,这意味着检查我们实际上是在调用一个方法而不是访问一个字段。
随着您的语言工作从让实现完全工作到让它更快地工作,您会发现自己会花越来越多时间寻找这样的模式,并为它们添加受保护的优化。全职 VM 工程师的大部分职业生涯都在这个循环中度过。
但我们现在可以停止了。有了这个,clox 现在支持面向对象编程语言的大多数功能,并且具有可观的性能。
挑战
-
哈希表查找以查找类的
init()方法是常数时间,但仍然相当慢。实现一些更快的。编写基准测试并衡量性能差异。 -
在像 Lox 这样的动态类型语言中,单个调用点可能会在程序执行期间调用许多类上的各种方法。即使这样,在实践中,大多数时候,调用点在运行期间最终会在完全相同的类上调用完全相同的方法。即使语言说它们可以是多态的,大多数调用实际上并不是多态的。
高级语言实现如何根据这些观察结果进行优化?
-
在解释
OP_INVOKE指令时,VM 必须执行两次哈希表查找。首先,它查找可能隐藏方法的字段,只有在失败的情况下才查找方法。前一个检查很少有用—大多数字段不包含函数。但它是必要的,因为语言说字段和方法使用相同的语法访问,并且字段会隐藏方法。这是一个影响我们实现性能的语言选择。这是正确选择吗?如果 Lox 是您的语言,您会怎么做?
设计说明:新颖性预算
我仍然记得我第一次在 TRS-80 上编写一个小型 BASIC 程序并让计算机做一些它以前没有做过的事情。感觉就像拥有超能力。我第一次拼凑出足够的解析器和解释器,让我用自己的语言编写一个小程序,让计算机做一件事,感觉就像某种高阶元超能力。它过去是,现在仍然是一种美妙的感觉。
我意识到我可以设计一种看起来和表现方式都由我选择的语言。就像我一直在上私立学校,他们要求穿制服,然后有一天转到公立学校,我可以穿任何我想穿的衣服。我不需要使用花括号来表示代码块?我可以使用除等号以外的符号来表示赋值?我可以不用类来创建对象?多重继承和多方法?一种动态语言,通过元数进行静态重载?
自然地,我利用了这种自由,并随之起舞。我做出了最奇怪、最武断的语言设计决定。使用撇号来表示泛型。参数之间没有逗号。重载解析可以在运行时失败。我做了一些与众不同的事情,仅仅为了与众不同。
这是一次非常有趣的经历,我强烈推荐。我们需要更多奇怪的、先锋的编程语言。我想看到更多艺术语言。我仍然偶尔会为娱乐而制作奇特的玩具语言。
然而,如果您的目标是成功,而“成功”的定义是大量的用户,那么您的优先级必须不同。在这种情况下,您的主要目标是让您的语言尽可能多地进入人们的大脑。这非常困难。将语言的语法和语义从计算机转移到数万亿个神经元需要大量的努力。
程序员对自己的时间非常保守,并且对哪些语言值得投入学习非常谨慎。他们不想浪费时间学习最终对他们没有用的语言。因此,作为一名语言设计师,你的目标是用尽可能少的学习量,给予他们尽可能多的语言能力。
一种自然的方法是**简洁**。你的语言包含的概念和功能越少,需要学习的内容总量就越少。这就是为什么即使最小化的脚本语言并不像大型工业语言那样强大,但它们往往能取得成功的原因之一——它们更容易上手,一旦被用户掌握,用户就会想要继续使用它们。
简洁的问题是,简单地裁剪功能往往会牺牲语言的强大和表达能力。找到性价比高的功能是一门艺术,但最小化的语言往往功能更少。
另一种方法可以避免大部分问题。诀窍是认识到用户不必将你的整个语言都加载到脑海中,**只需要加载他们脑海中还没有的部分**。正如我在之前的一篇设计笔记中提到的,学习是关于将他们已知的信息与他们需要知道的信息之间的**差距**传递过去。
你的语言的许多潜在用户已经了解其他编程语言。你的语言与这些语言共享的任何功能在学习方面都是**免费的**。这些功能已经存在于他们的脑海中,他们只需要意识到你的语言也能做同样的事情。
换句话说,**熟悉性**是降低语言采用成本的另一个关键工具。当然,如果你完全最大化这个属性,最终的结果将是一个与现有语言完全相同的语言。这不是一个成功的秘诀,因为此时用户根本没有理由切换到你的语言。
因此,你需要提供一些令人信服的差异。你的语言可以做一些其他语言做不到的事情,或者至少做不到同样好。我认为这是语言设计的基本平衡行为之一:与其他语言的相似性降低了学习成本,而差异性则提高了令人信服的优势。
我把这种平衡行为看作是**新颖性预算**,或者正如 Steve Klabnik 所称的,“奇特性预算”。用户对他们愿意为了学习一门新语言而接受的新事物的总量有一个很低的阈值。超过这个阈值,他们就不会出现。
每当你为你的语言添加其他语言没有的功能,或者每当你以其他语言不同的方式做一些其他语言做的事情时,你都会花掉一些预算。这没关系——你**需要**花掉它才能让你的语言更有说服力。但你的目标是**明智地**花掉它。对于每个功能或差异,问问自己它为你的语言增加了多少说服力,然后批判性地评估它是否物有所值。这种改变是否如此有价值,以至于值得花掉一些你的新颖性预算?
在实践中,我发现这意味着你最终会对语法持保守态度,对语义更具冒险精神。虽然更换衣服很有趣,但用其他块分隔符替换大括号不太可能真正增强语言的强大功能,但它确实会花掉一些新颖性。语法的差异很难发挥作用。
另一方面,新的语义可以显著提高语言的强大功能。多方法、mixin、特质、反射、依赖类型、运行时元编程等可以从根本上提升用户可以用语言做的事情的水平。
唉,像这样保守并不像改变一切那样有趣。但首先,由你来决定你是否想追求主流成功。我们并不都需要成为受大众欢迎的流行乐队。如果你想让你的语言像自由爵士或无人机金属音乐,并且对相应更小(但可能更忠诚)的受众规模感到满意,那就去做吧。