闭包
正如那句话所说,对于每一个复杂的问题,都存在一个简单的解决方案,而这个解决方案是错误的。
翁贝托·艾柯,《傅科的摆》
感谢我们在上一章中辛勤的劳动,我们现在拥有一个功能正常的虚拟机。它缺少的是闭包。除了全局变量(它们是另一类动物),函数无法引用在自身主体之外声明的变量。
var x = "global"; fun outer() { var x = "outer"; fun inner() { print x; } inner(); } outer();
现在运行这个示例,它将打印“global”。它应该打印“outer”。为了修复这个问题,我们需要在解析变量时包含所有周围函数的整个词法作用域。
这个问题在 clox 中比在 jlox 中更难,因为我们的字节码 VM 将局部变量存储在栈上。我们使用栈是因为我声称局部变量具有栈语义—变量以创建的逆序被丢弃。但是对于闭包来说,这只是大部分正确。
fun makeClosure() { var local = "local"; fun closure() { print local; } return closure; } var closure = makeClosure(); closure();
外部函数 makeClosure() 声明了一个变量,local。它还创建了一个内部函数,closure(),该函数捕获了该变量。然后 makeClosure() 返回对该函数的引用。由于闭包逃逸时保留了对局部变量的引用,因此 local 必须比创建它的函数调用的生命周期更长。
我们可以通过为所有局部变量动态分配内存来解决这个问题。这就是 jlox 通过将所有内容放在那些在 Java 堆中四处飘动的 Environment 对象中所做的事情。但我们不想这样做。使用栈非常快。大多数局部变量不会被闭包捕获,并且确实具有栈语义。为了使那些很少被捕获的局部变量受益,而让所有其他局部变量变慢,这太糟糕了。
这意味着我们需要比我们在 Java 解释器中使用的更复杂的方法。由于有些局部变量具有非常不同的生命周期,我们将采用两种实现策略。对于不在闭包中使用的局部变量,我们将保留它们,就像它们在栈上一样。当一个局部变量被闭包捕获时,我们将采用另一种解决方案,将它们提升到堆上,在那里它们可以根据需要生存。
闭包自 Lisp 时代的早期就存在了,当时内存字节和 CPU 周期比祖母绿更珍贵。在过去的几十年里,黑客们设计了各种各样的方法,将闭包编译成优化的运行时表示。有些方法效率更高,但需要更复杂的编译过程,我们无法轻松地将其移植到 clox 中。
我在这里解释的技术来自 Lua VM 的设计。它速度快,内存占用少,并且实现代码相对较少。更令人印象深刻的是,它自然地适合 clox 和 Lua 使用的单遍编译器。不过,它有点复杂。所有这些部分可能需要一段时间才能在你的脑海中组合起来。我们将一步一步地构建它们,我将尝试分阶段介绍这些概念。
25 . 1闭包对象
我们的 VM 在运行时使用 ObjFunction 来表示函数。这些对象在编译期间由前端创建。在运行时,VM 所做的只是从常量表中加载函数对象并将其绑定到一个名称。没有在运行时“创建”函数的操作。就像字符串和数字字面量一样,它们是在编译时完全实例化的常量。
这很有意义,因为构成函数的所有数据在编译时都是已知的:从函数主体编译的字节码块,以及主体中使用的常量。但是,一旦我们引入了闭包,这种表示就不再足够了。看一看
fun makeClosure(value) { fun closure() { print value; } return closure; } var doughnut = makeClosure("doughnut"); var bagel = makeClosure("bagel"); doughnut(); bagel();
makeClosure() 函数定义并返回一个函数。我们调用它两次,并获得两个闭包。它们是由同一个嵌套函数声明(closure)创建的,但它们闭包了不同的值。当我们调用这两个闭包时,每个闭包都打印不同的字符串。这意味着我们需要一些闭包的运行时表示,该表示捕获了函数声明执行时周围的局部变量,而不仅仅是在编译时。
我们将逐步实现捕获变量,但第一步是定义该对象表示。我们现有的 ObjFunction 类型表示函数声明的“原始”编译时状态,因为从单个声明创建的所有闭包共享相同的代码和常量。在运行时,当我们执行函数声明时,我们将 ObjFunction 包装在一个新的 ObjClosure 结构中。后者对底层的裸函数以及函数闭包的变量的运行时状态进行引用。
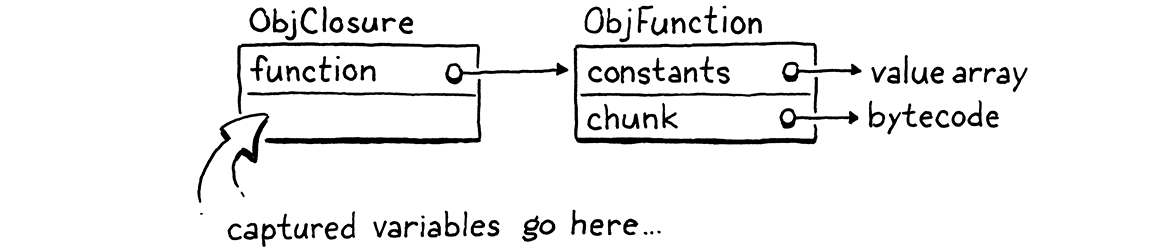
我们将用 ObjClosure 包装每个函数,即使该函数实际上没有闭包并捕获任何周围的局部变量。这有点浪费,但它简化了 VM,因为我们始终可以假设我们要调用的函数是一个 ObjClosure。这个新的结构从这里开始
在 struct ObjString 之后添加
typedef struct { Obj obj; ObjFunction* function; } ObjClosure;
现在,它只是指向一个 ObjFunction,并添加了必要的对象头信息。通过为 clox 添加一个新的对象类型而进行的常规操作,我们声明了一个 C 函数来创建一个新的闭包。
} ObjClosure;
在 struct ObjClosure 之后添加
ObjClosure* newClosure(ObjFunction* function);
ObjFunction* newFunction();
然后我们在这里实现它
在 allocateObject() 之后添加
ObjClosure* newClosure(ObjFunction* function) { ObjClosure* closure = ALLOCATE_OBJ(ObjClosure, OBJ_CLOSURE); closure->function = function; return closure; }
它接受一个指向它所包装的 ObjFunction 的指针。它还将类型字段初始化为一个新的类型。
typedef enum {
在 enum ObjType 中
OBJ_CLOSURE,
OBJ_FUNCTION,
当我们完成一个闭包时,我们会释放它的内存。
switch (object->type) {
在 freeObject() 中
case OBJ_CLOSURE: { FREE(ObjClosure, object); break; }
case OBJ_FUNCTION: {
我们只释放 ObjClosure 本身,而不是 ObjFunction。这是因为闭包不拥有函数。可能有多个闭包都引用同一个函数,它们没有哪个对它拥有特殊权利。我们无法释放 ObjFunction,直到所有引用它的对象都消失了—甚至包括包含它的周围函数的常量表。跟踪这听起来很棘手,确实如此!这就是为什么我们很快就会编写一个垃圾收集器来为我们管理它。
我们还有用于检查值的类型的常规宏。
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
#define IS_CLOSURE(value) isObjType(value, OBJ_CLOSURE)
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
以及用于强制转换值的
#define IS_STRING(value) isObjType(value, OBJ_STRING)
#define AS_CLOSURE(value) ((ObjClosure*)AS_OBJ(value))
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
闭包是一等对象,因此你可以打印它们。
switch (OBJ_TYPE(value)) {
在 printObject() 中
case OBJ_CLOSURE: printFunction(AS_CLOSURE(value)->function); break;
case OBJ_FUNCTION:
它们的显示方式与 ObjFunction 完全相同。从用户的角度来看,ObjFunction 和 ObjClosure 之间的区别纯粹是隐藏的实现细节。有了这些,我们拥有一个功能齐全但为空的闭包表示。
25 . 1 . 1编译为闭包对象
我们拥有闭包对象,但我们的 VM 从未创建它们。下一步是让编译器发出指令,告诉运行时何时为给定的 ObjFunction 创建一个新的 ObjClosure。这发生在函数声明的末尾。
ObjFunction* function = endCompiler();
在 function() 中
替换 1 行
emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function)));
}
以前,函数声明的最终字节码是一个单独的 OP_CONSTANT 指令,用于从周围函数的常量表中加载编译后的函数并将其推送到栈上。现在我们有了新的指令。
OP_CALL,
在 enum OpCode 中
OP_CLOSURE,
OP_RETURN,
与 OP_CONSTANT 一样,它接受一个单独的操作数,该操作数代表函数的常量表索引。但是,当我们转到运行时实现时,我们会做一些更有趣的事情。
首先,让我们成为勤勉的 VM 黑客,并为该指令插入反汇编支持。
case OP_CALL:
return byteInstruction("OP_CALL", chunk, offset);
在 disassembleInstruction() 中
case OP_CLOSURE: { offset++; uint8_t constant = chunk->code[offset++]; printf("%-16s %4d ", "OP_CLOSURE", constant); printValue(chunk->constants.values[constant]); printf("\n"); return offset; }
case OP_RETURN:
这里有比我们通常在反汇编器中看到的更多内容。到本章结束时,你将发现 OP_CLOSURE 是一个很不寻常的指令。现在它很简单—只是一个字节操作数—但我们将对其进行扩展。此处的代码预见到了未来。
25 . 1 . 2解释函数声明
我们需要做的主要工作是在运行时。自然,我们需要处理新的指令。但我们还需要修改 VM 中处理 ObjFunction 的所有代码,将其改为使用 ObjClosure—函数调用、调用帧等。我们将从指令开始。
}
在 run() 中
case OP_CLOSURE: { ObjFunction* function = AS_FUNCTION(READ_CONSTANT()); ObjClosure* closure = newClosure(function); push(OBJ_VAL(closure)); break; }
case OP_RETURN: {
就像我们之前使用的 OP_CONSTANT 指令一样,首先我们从常量表中加载编译后的函数。现在不同的是,我们将该函数包装在一个新的 ObjClosure 中,并将结果推送到栈上。
一旦你有了闭包,你最终会想要调用它。
switch (OBJ_TYPE(callee)) {
在 callValue() 中
替换 2 行
case OBJ_CLOSURE: return call(AS_CLOSURE(callee), argCount);
case OBJ_NATIVE: {
我们删除了调用类型为 OBJ_FUNCTION 的对象的代码。由于我们将所有函数包装在 ObjClosures 中,因此运行时将不再尝试调用裸 ObjFunction。这些对象只存在于常量表中,并在其他任何内容看到它们之前立即包装在闭包中。
我们用非常相似的代码来调用闭包替换了旧代码。唯一的区别是我们传递给 call() 的对象类型。真正的更改是在该函数中。首先,我们更新其签名。
函数 call()
替换 1 行
static bool call(ObjClosure* closure, int argCount) {
if (argCount != function->arity) {
然后,在主体中,我们需要修复所有引用函数的内容,以处理我们引入的一层间接层。我们从参数检查开始
static bool call(ObjClosure* closure, int argCount) {
在 call() 中
替换 3 行
if (argCount != closure->function->arity) { runtimeError("Expected %d arguments but got %d.", closure->function->arity, argCount);
return false;
唯一的变化是我们解开了闭包以获取底层函数。接下来,call() 会创建一个新的 CallFrame。我们将代码更改为将闭包存储在 CallFrame 中,并从闭包的函数中获取字节码指针。
CallFrame* frame = &vm.frames[vm.frameCount++];
在 call() 中
替换 2 行
frame->closure = closure; frame->ip = closure->function->chunk.code;
frame->slots = vm.stackTop - argCount - 1;
这需要更改 CallFrame 的声明。
typedef struct {
在 struct CallFrame 中
替换 1 行
ObjClosure* closure;
uint8_t* ip;
这一更改会引发其他一些连锁反应。VM 中每个访问 CallFrame 函数的地方都需要使用闭包。首先,用于从当前函数的常量表中读取常量的宏
(uint16_t)((frame->ip[-2] << 8) | frame->ip[-1]))
在 run() 中
替换 2 行
#define READ_CONSTANT() \ (frame->closure->function->chunk.constants.values[READ_BYTE()])
#define READ_STRING() AS_STRING(READ_CONSTANT())
当 DEBUG_TRACE_EXECUTION 启用时,它需要从闭包中获取代码块。
printf("\n");
在 run() 中
替换 2 行
disassembleInstruction(&frame->closure->function->chunk, (int)(frame->ip - frame->closure->function->chunk.code));
#endif
同样地,在报告运行时错误时
CallFrame* frame = &vm.frames[i];
在 runtimeError() 中
替换 1 行
ObjFunction* function = frame->closure->function;
size_t instruction = frame->ip - function->chunk.code - 1;
差不多快完成了。最后一块代码是设置第一个 CallFrame 以开始执行 Lox 脚本的顶级代码。
push(OBJ_VAL(function));
在 interpret() 中
替换 1 行
ObjClosure* closure = newClosure(function); pop(); push(OBJ_VAL(closure)); call(closure, 0);
return run();
编译器在编译脚本时仍然会返回原始的 ObjFunction。这没有问题,但意味着我们需要在这里将它包装在 ObjClosure 中,然后 VM 才能执行它。
我们又回到了一个工作的解释器。用户无法察觉到任何差异,但编译器现在生成代码,告诉 VM 为每个函数声明创建一个闭包。每次 VM 执行函数声明时,它都会将 ObjFunction 包装在一个新的 ObjClosure 中。VM 的其余部分现在处理这些四处漂浮的 ObjClosure。这些无聊的东西已经完成了。现在我们准备让这些闭包真正发挥作用。
25 . 2Upvalues
我们现有的用于读取和写入局部变量的指令仅限于单个函数的堆栈窗口。周围函数的局部变量在内部函数的窗口之外。我们需要一些新的指令。
最简单的方法可能是使用一条指令,该指令接受一个相对堆栈槽偏移量,该偏移量可以到达当前函数的窗口之前。如果闭包的变量始终在堆栈上,这将有效。但正如我们之前看到的,这些变量有时会比声明它们的函数存活更久。这意味着它们并不总是会在堆栈上。
那么,下一个最简单的方法是将所有被闭包的局部变量始终放在堆上。当周围函数中的局部变量声明被执行时,VM 将为它动态分配内存。这样它就可以根据需要存活。
如果 clox 没有单遍编译器,这将是一个很好的方法。但是,我们在实现中选择的这个限制使事情变得更加困难。看一下这个例子
fun outer() { var x = 1; // (1) x = 2; // (2) fun inner() { // (3) print x; } inner(); }
这里,编译器在 (1) 处编译 x 的声明,并在 (2) 处发出赋值代码。它在到达 (3) 处的 inner() 声明之前就完成了这些操作,并发现 x 实际上是被闭包的。我们没有简单的方法可以返回并修复已经发出的代码以特殊对待 x。相反,我们希望找到一种解决方案,使闭包的变量可以像普通局部变量一样完全存活在堆栈上,直到它被闭包为止。
幸运的是,感谢 Lua 开发团队,我们找到了一个解决方案。我们使用了一种他们称为upvalue的间接层级。Upvalue 指的是封闭函数中的局部变量。每个闭包都维护一个 upvalue 数组,每个数组对应于闭包使用的每个周围局部变量。
Upvalue 指回堆栈中的被捕获变量所在位置。当闭包需要访问闭包的变量时,它会通过相应的 upvalue 来访问它。当函数声明首次执行,并且我们为它创建一个闭包时,VM 会创建 upvalue 数组,并将它们连接起来,以“捕获”闭包需要的周围局部变量。
例如,如果我们将这个程序抛给 clox,
{
var a = 3;
fun f() {
print a;
}
}
编译器和运行时将协同工作,在内存中构建一组这样的对象
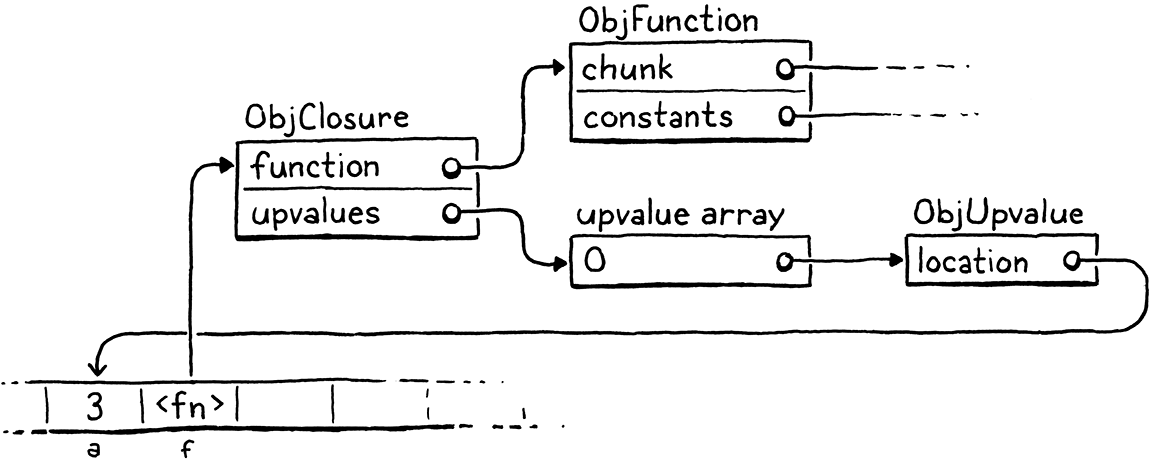
这可能看起来让人不知所措,但不要害怕。我们会逐步讲解。重要的是 upvalue 充当了间接层,即使在捕获的局部变量从堆栈中移出后,我们仍然可以找到它。但在我们深入研究这些之前,让我们先关注如何编译捕获的变量。
25 . 2 . 1编译 upvalues
和往常一样,我们希望在编译期间完成尽可能多的工作,以使执行简单快捷。由于 Lox 中的局部变量是词法作用域的,因此我们在编译时有足够的信息来确定函数访问哪些周围局部变量以及这些局部变量是在哪里声明的。反过来,这意味着我们知道闭包需要多少 upvalue,哪些变量被它们捕获以及哪些堆栈槽包含这些变量在声明函数的堆栈窗口中。
当前,当编译器解析标识符时,它会从最内层到最外层遍历当前函数的块作用域。如果我们没有在该函数中找到该变量,我们假设该变量一定是全局变量。我们不会考虑封闭函数的局部作用域—它们会被直接跳过。因此,第一个更改是插入一个解析这些外部局部作用域的步骤。
if (arg != -1) {
getOp = OP_GET_LOCAL;
setOp = OP_SET_LOCAL;
在 namedVariable() 中
} else if ((arg = resolveUpvalue(current, &name)) != -1) { getOp = OP_GET_UPVALUE; setOp = OP_SET_UPVALUE;
} else {
这个新的 resolveUpvalue() 函数会查找在任何周围函数中声明的局部变量。如果找到,它将返回该变量的“upvalue 索引”。(我们将在稍后介绍这是什么意思。)否则,它将返回 -1,表示未找到该变量。如果找到,我们将使用这两个新指令通过其 upvalue 来读取或写入该变量
OP_SET_GLOBAL,
在 enum OpCode 中
OP_GET_UPVALUE, OP_SET_UPVALUE,
OP_EQUAL,
我们正在以这种自顶向下的方式实现,因此我将很快向您展示这些指令在运行时的工作方式。现在需要关注的是编译器如何实际解析标识符。
在 resolveLocal() 后添加
static int resolveUpvalue(Compiler* compiler, Token* name) { if (compiler->enclosing == NULL) return -1; int local = resolveLocal(compiler->enclosing, name); if (local != -1) { return addUpvalue(compiler, (uint8_t)local, true); } return -1; }
我们在未能解析当前函数作用域中的局部变量后调用此函数,因此我们知道该变量不在当前编译器中。回想一下,Compiler 存储一个指向封闭函数的 Compiler 的指针,这些指针形成一个链接链,一直延伸到顶级代码的根 Compiler。因此,如果封闭 Compiler 为 NULL,我们知道我们已经到达最外层函数,但没有找到局部变量。该变量一定是 全局变量,因此我们返回 -1。
否则,我们尝试在封闭编译器中将标识符解析为局部变量。换句话说,我们在当前函数之外查找它。例如
fun outer() { var x = 1; fun inner() { print x; // (1) } inner(); }
在编译 (1) 处的标识符表达式时,resolveUpvalue() 会在 outer() 中查找声明的局部变量 x。如果找到—就像在这个例子中一样—那么我们就成功解析了该变量。我们创建一个 upvalue,以便内部函数可以通过它访问该变量。Upvalue 在这里创建
在 resolveLocal() 后添加
static int addUpvalue(Compiler* compiler, uint8_t index, bool isLocal) { int upvalueCount = compiler->function->upvalueCount; compiler->upvalues[upvalueCount].isLocal = isLocal; compiler->upvalues[upvalueCount].index = index; return compiler->function->upvalueCount++; }
编译器维护一个 upvalue 结构数组,以跟踪它在每个函数的主体中解析的闭包标识符。还记得编译器的 Local 数组是如何反映局部变量在运行时所在的堆栈槽索引的吗?这个新的 upvalue 数组的工作方式相同。编译器数组中的索引与 upvalue 在 ObjClosure 中运行时所在的索引相匹配。
这个函数在该数组中添加了一个新的 upvalue。它还跟踪函数使用的 upvalue 的数量。它将该计数直接存储在 ObjFunction 本身中,因为我们也需要这个数字在运行时使用。
index 字段跟踪闭包的局部变量的槽索引。这样编译器就知道封闭函数中哪个变量需要被捕获。我们将在不久后回到 isLocal 字段的用途。最后,addUpvalue() 返回在函数的 upvalue 列表中创建的 upvalue 的索引。该索引成为 OP_GET_UPVALUE 和 OP_SET_UPVALUE 指令的操作数。
这就是解析 upvalue 的基本思路,但该函数尚未完全完善。闭包可能多次引用周围函数中的同一个变量。在这种情况下,我们不希望浪费时间和内存为每个标识符表达式创建单独的 upvalue。为了解决这个问题,在我们添加新的 upvalue 之前,我们首先检查函数是否已经拥有一个闭包该变量的 upvalue。
int upvalueCount = compiler->function->upvalueCount;
在 addUpvalue() 中
for (int i = 0; i < upvalueCount; i++) { Upvalue* upvalue = &compiler->upvalues[i]; if (upvalue->index == index && upvalue->isLocal == isLocal) { return i; } }
compiler->upvalues[upvalueCount].isLocal = isLocal;
如果我们在数组中找到一个其槽索引与我们正在添加的槽索引匹配的 upvalue,我们只需返回该upvalue 索引并重用它。否则,我们将继续执行并添加新的 upvalue。
这两个函数访问并修改了许多新的状态,因此让我们定义一下。首先,我们将 upvalue 计数添加到 ObjFunction 中。
int arity;
在 struct ObjFunction 中
int upvalueCount;
Chunk chunk;
我们是尽职尽责的 C 程序员,因此我们在首次分配 ObjFunction 时将其初始化为零。
function->arity = 0;
在 newFunction() 中
function->upvalueCount = 0;
function->name = NULL;
在编译器中,我们为 upvalue 数组添加了一个字段。
int localCount;
在 struct Compiler 中
Upvalue upvalues[UINT8_COUNT];
int scopeDepth;
为简单起见,我给了它一个固定的大小。OP_GET_UPVALUE 和 OP_SET_UPVALUE 指令使用一个字节操作数来编码 upvalue 索引,因此函数可以拥有的 upvalue 数量(即它可以闭包的唯一变量数量)存在限制。考虑到这一点,我们可以负担得起如此大的静态数组。我们还需要确保编译器不会超过该限制。
if (upvalue->index == index && upvalue->isLocal == isLocal) {
return i;
}
}
在 addUpvalue() 中
if (upvalueCount == UINT8_COUNT) { error("Too many closure variables in function."); return 0; }
compiler->upvalues[upvalueCount].isLocal = isLocal;
最后,Upvalue 结构类型本身。
在 struct Local 后添加
typedef struct { uint8_t index; bool isLocal; } Upvalue;
index 字段存储 upvalue 捕获的哪个局部槽。isLocal 字段有其自己的部分,我们将在稍后介绍。
25 . 2 . 2扁平化 upvalues
在我之前展示的示例中,闭包访问的是在直接封闭函数中声明的变量。Lox 还支持访问在任何封闭作用域中声明的局部变量,例如
fun outer() { var x = 1; fun middle() { fun inner() { print x; } } }
这里,我们在 inner() 中访问 x。该变量不是在 middle() 中定义的,而是在 outer() 中定义的。我们也需要处理这种情况。你可能认为这并不难,因为该变量只是在堆栈中的某个更低的位置。但是,考虑一下这个 阴险的 例子
fun outer() { var x = "value"; fun middle() { fun inner() { print x; } print "create inner closure"; return inner; } print "return from outer"; return middle; } var mid = outer(); var in = mid(); in();
当您运行此程序时,它应该打印
return from outer create inner closure value
我知道,这很复杂。重要的是,outer()—其中声明了x—在执行声明inner()之前,会返回并将所有变量从堆栈中弹出。因此,在我们创建inner()的闭包时,x已经不在堆栈中了。
在这里,我为您追踪了执行流程
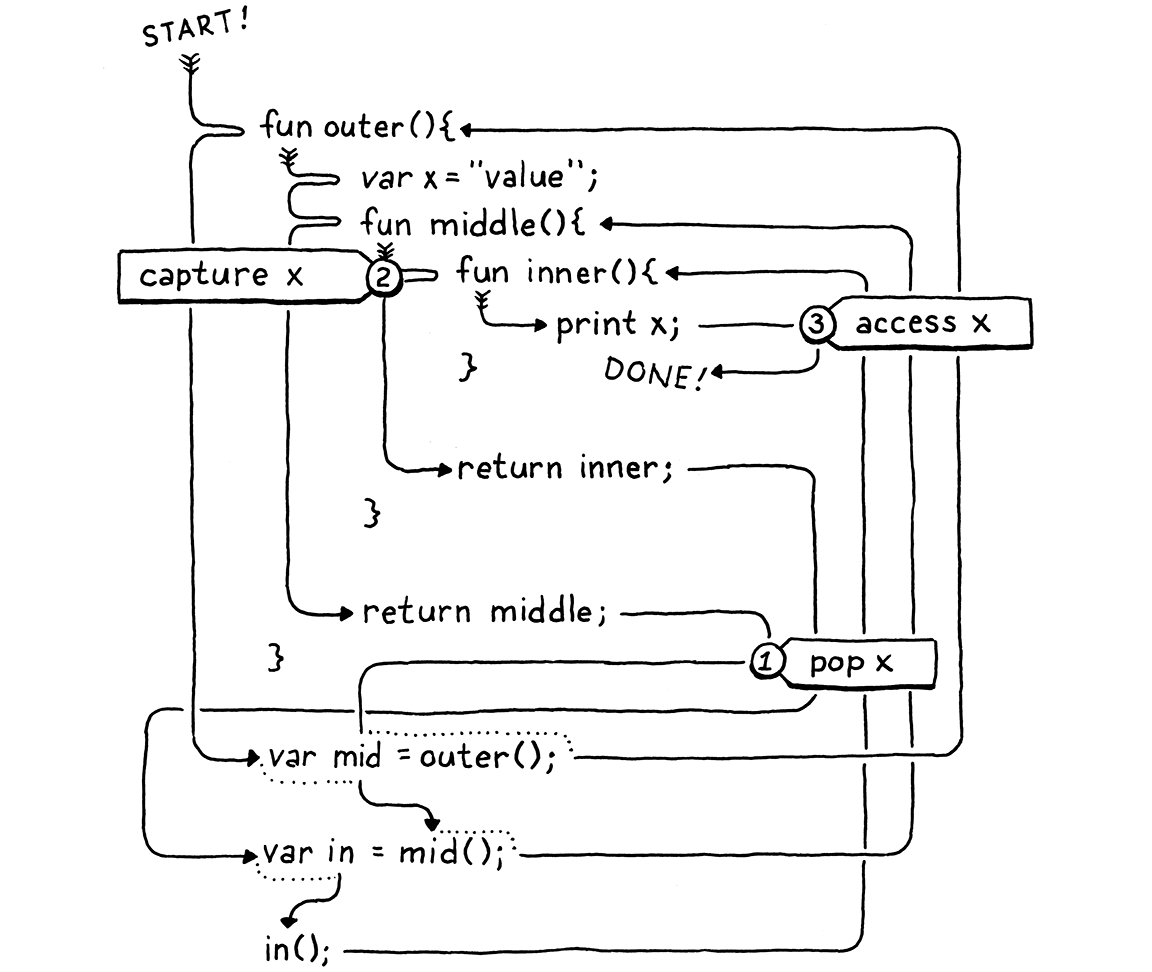
看看x是如何在被捕获②之前被弹出①,然后在之后被访问③?我们实际上有两个问题
-
我们需要解析在包围函数中声明的局部变量,这些函数超出了直接包围函数。
-
我们需要能够捕获已经离开堆栈的变量。
幸运的是,我们正在向 VM 添加 upvalues,而 upvalues 是专门设计用于跟踪已从堆栈中逃逸的变量的。因此,在一个巧妙的自引用中,我们可以使用 upvalues 来允许 upvalues 捕获在直接包围函数之外声明的变量。
解决方案是允许闭包捕获直接包围函数中的局部变量或现有 upvalue。如果一个深度嵌套的函数引用了一个在多个层次之外声明的局部变量,我们将通过让每个函数捕获一个 upvalue 来传递给下一个函数来将其穿过所有中间函数。
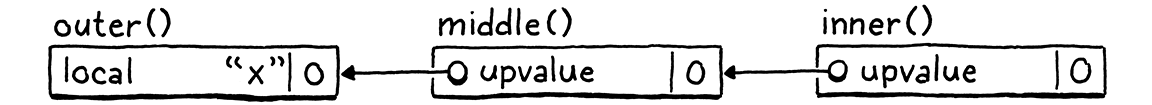
在上面的例子中,middle()捕获了直接包围函数outer()中的局部变量x,并将其存储在自己的 upvalue 中。它这样做即使middle()本身没有引用x。然后,当inner()的声明执行时,它的闭包从捕获了x的middle()的 ObjClosure 中获取upvalue。一个函数只从直接包围函数中捕获—局部变量或 upvalue—,而直接包围函数在内部函数声明执行时一定会存在。
为了实现这一点,resolveUpvalue()变成了递归函数。
if (local != -1) {
return addUpvalue(compiler, (uint8_t)local, true);
}
在resolveUpvalue()中
int upvalue = resolveUpvalue(compiler->enclosing, name); if (upvalue != -1) { return addUpvalue(compiler, (uint8_t)upvalue, false); }
return -1;
它只有另外三行代码,但我发现第一次很难让这个函数正确执行。尽管我并没有发明任何新的东西,只是从 Lua 中移植了这个概念。大多数递归函数要么在递归调用之前完成所有工作(前序遍历,或“向下走”),要么在递归调用之后完成所有工作(后序遍历,或“向上走”)。这个函数两者都做。递归调用就在中间。
我们将慢慢地遍历它。首先,我们在包围函数中寻找匹配的局部变量。如果我们找到一个,我们就捕获该局部变量并返回。这是基本情况。
否则,我们在直接包围函数之外寻找一个局部变量。我们通过递归调用包围编译器而不是当前编译器的resolveUpvalue()来实现这一点。这一系列resolveUpvalue()调用沿嵌套编译器的链工作,直到它遇到其中一个基本情况—要么它找到一个要捕获的实际局部变量,要么它耗尽了编译器。
当找到一个局部变量时,resolveUpvalue()的最深层嵌套调用会捕获它并返回 upvalue 索引。这将返回到内部函数声明的下一个调用。该调用从包围函数中捕获upvalue,依此类推。当每个嵌套的resolveUpvalue()调用返回时,我们向下钻到标识符要解析的内部函数声明中。在沿途的每一步,我们都会在中间函数中添加一个 upvalue,并将得到的 upvalue 索引传递给下一个调用。
在解析x时,遍历原始示例可能会有所帮助
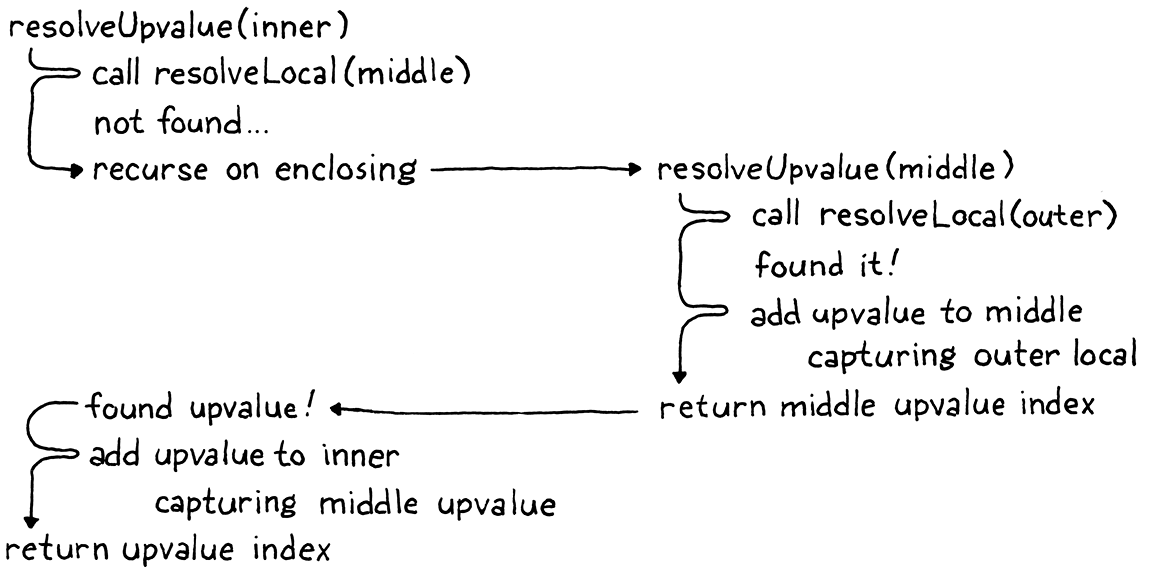
注意,对addUpvalue()的新调用为isLocal参数传递了false。现在你看到,该标志控制闭包是捕获一个局部变量还是包围函数的 upvalue。
当编译器到达函数声明的末尾时,每个变量引用都已解析为局部变量、upvalue 或全局变量。每个 upvalue 又可以捕获包围函数中的局部变量,或者在传递闭包的情况下捕获 upvalue。我们终于拥有足够的数据来发出字节码,该字节码在运行时创建一个捕获所有正确变量的闭包。
emitBytes(OP_CLOSURE, makeConstant(OBJ_VAL(function)));
在 function() 中
for (int i = 0; i < function->upvalueCount; i++) { emitByte(compiler.upvalues[i].isLocal ? 1 : 0); emitByte(compiler.upvalues[i].index); }
}
OP_CLOSURE指令的独特之处在于它具有可变大小的编码。对于闭包捕获的每个 upvalue,都有两个单字节操作数。每对操作数都指定了该 upvalue 捕获的内容。如果第一个字节为 1,则它捕获包围函数中的一个局部变量。如果为 0,则它捕获该函数的一个 upvalue。下一个字节是要捕获的局部变量槽或 upvalue 索引。
这种奇怪的编码意味着我们需要在OP_CLOSURE的反汇编代码中提供一些专门的支持。
printf("\n");
在 disassembleInstruction() 中
ObjFunction* function = AS_FUNCTION(
chunk->constants.values[constant]);
for (int j = 0; j < function->upvalueCount; j++) {
int isLocal = chunk->code[offset++];
int index = chunk->code[offset++];
printf("%04d | %s %d\n",
offset - 2, isLocal ? "local" : "upvalue", index);
}
return offset;
例如,取这个脚本
fun outer() { var a = 1; var b = 2; fun middle() { var c = 3; var d = 4; fun inner() { print a + c + b + d; } } }
如果我们反汇编创建inner()闭包的指令,它会打印以下内容
0004 9 OP_CLOSURE 2 <fn inner> 0006 | upvalue 0 0008 | local 1 0010 | upvalue 1 0012 | local 2
我们还有另外两个更简单的指令需要添加反汇编支持。
case OP_SET_GLOBAL:
return constantInstruction("OP_SET_GLOBAL", chunk, offset);
在 disassembleInstruction() 中
case OP_GET_UPVALUE: return byteInstruction("OP_GET_UPVALUE", chunk, offset); case OP_SET_UPVALUE: return byteInstruction("OP_SET_UPVALUE", chunk, offset);
case OP_EQUAL:
它们都有一个单字节操作数,所以没有令人兴奋的事情发生。我们需要添加一个包含文件,以便调试模块可以访问AS_FUNCTION()。
#include "debug.h"
#include "object.h"
#include "value.h"
这样一来,我们的编译器就达到了我们想要的状态。对于每个函数声明,它输出一个OP_CLOSURE指令,然后是一系列操作数字节对,用于在运行时捕获每个 upvalue。现在该转到 VM 的另一端,让事情运行起来。
25 . 3Upvalue 对象
现在,每个OP_CLOSURE指令后面都跟着一系列字节,这些字节指定了 ObjClosure 应该拥有的 upvalues。在处理这些操作数之前,我们需要一个 upvalues 的运行时表示。
在 struct ObjString 之后添加
typedef struct ObjUpvalue { Obj obj; Value* location; } ObjUpvalue;
我们知道,upvalues 必须管理不再位于堆栈中的闭包变量,这意味着需要进行一定程度的动态分配。在我们的 VM 中,最简单的做法是建立在我们已经拥有的对象系统之上。这样,当我们在下一章中实现垃圾收集器时,GC 也可以管理 upvalues 的内存。
因此,我们的运行时 upvalue 结构是带有典型 Obj 头字段的 ObjUpvalue。其后是一个location字段,它指向闭包变量。请注意,这是一个指向 Value 的指针,而不是 Value 本身。它是对变量的引用,而不是对值的引用。这一点很重要,因为这意味着当我们为 upvalue 捕获的变量赋值时,我们是对实际变量进行赋值,而不是对副本赋值。例如
fun outer() { var x = "before"; fun inner() { x = "assigned"; } inner(); print x; } outer();
即使闭包为x赋值,包围函数访问它,这个程序也应该打印“assigned”。
由于 upvalues 是对象,因此我们拥有所有通常的对象机制,从一个类似构造函数的函数开始
ObjString* copyString(const char* chars, int length);
在copyString()之后添加
ObjUpvalue* newUpvalue(Value* slot);
void printObject(Value value);
它接受闭包变量所在槽的地址。以下是实现
在copyString()之后添加
ObjUpvalue* newUpvalue(Value* slot) { ObjUpvalue* upvalue = ALLOCATE_OBJ(ObjUpvalue, OBJ_UPVALUE); upvalue->location = slot; return upvalue; }
我们只需初始化对象并存储指针。这需要一种新的对象类型。
OBJ_STRING,
在 enum ObjType 中
OBJ_UPVALUE
} ObjType;
在背面,有一个类似析构函数的函数
FREE(ObjString, object);
break;
}
在 freeObject() 中
case OBJ_UPVALUE: FREE(ObjUpvalue, object); break;
}
多个闭包可以闭包同一个变量,因此 ObjUpvalue 不拥有它引用的变量。因此,唯一需要释放的是 ObjUpvalue 本身。
最后,打印
case OBJ_STRING:
printf("%s", AS_CSTRING(value));
break;
在 printObject() 中
case OBJ_UPVALUE: printf("upvalue"); break;
}
打印对最终用户没有用。Upvalues 只是对象,以便我们可以利用 VM 的内存管理。它们不是 Lox 用户可以在程序中直接访问的一等值。因此,这段代码实际上永远不会执行 . . . 但它可以阻止编译器因未处理的 switch case 而报错,所以我们就这样做了。
25 . 3 . 1闭包中的 Upvalues
当我第一次介绍 upvalues 时,我说每个闭包都有一个 upvalues 数组。我们终于回到了实现它的过程。
ObjFunction* function;
在 struct ObjClosure 中
ObjUpvalue** upvalues; int upvalueCount;
} ObjClosure;
不同的闭包可能具有不同数量的 upvalues,因此我们需要一个动态数组。upvalues 本身也是动态分配的,因此我们最终得到一个双指针—指向指向 upvalues 的动态分配数组的指针。我们还存储数组中的元素数量。
当我们创建一个 ObjClosure 时,我们会分配一个大小合适的 upvalue 数组,我们在编译时确定了该大小并将其存储在 ObjFunction 中。
ObjClosure* newClosure(ObjFunction* function) {
在newClosure()中
ObjUpvalue** upvalues = ALLOCATE(ObjUpvalue*, function->upvalueCount); for (int i = 0; i < function->upvalueCount; i++) { upvalues[i] = NULL; }
ObjClosure* closure = ALLOCATE_OBJ(ObjClosure, OBJ_CLOSURE);
在创建闭包对象本身之前,我们会分配 upvalues 数组并将其全部初始化为NULL。围绕内存的这种奇怪的仪式是为满足(即将到来的)垃圾收集神灵而进行的谨慎舞蹈。它确保内存管理器永远不会看到未初始化的内存。
然后,我们将数组存储在新的闭包中,并将计数从 ObjFunction 中复制过来。
closure->function = function;
在newClosure()中
closure->upvalues = upvalues; closure->upvalueCount = function->upvalueCount;
return closure;
当我们释放一个 ObjClosure 时,我们也会释放 upvalue 数组。
case OBJ_CLOSURE: {
在 freeObject() 中
ObjClosure* closure = (ObjClosure*)object; FREE_ARRAY(ObjUpvalue*, closure->upvalues, closure->upvalueCount);
FREE(ObjClosure, object);
ObjClosure 不拥有 ObjUpvalue 对象本身,但它拥有包含指向这些 upvalues 的指针的数组。
当解释器创建闭包时,我们会填充 upvalue 数组。这是我们遍历OP_CLOSURE后面的所有操作数以查看每个槽捕获了哪种 upvalue 的地方。
push(OBJ_VAL(closure));
在 run() 中
for (int i = 0; i < closure->upvalueCount; i++) { uint8_t isLocal = READ_BYTE(); uint8_t index = READ_BYTE(); if (isLocal) { closure->upvalues[i] = captureUpvalue(frame->slots + index); } else { closure->upvalues[i] = frame->closure->upvalues[index]; } }
break;
这段代码是闭包诞生的魔法时刻。我们迭代闭包期望的每个 upvalue。对于每个 upvalue,我们读取一对操作数字节。如果 upvalue 闭包了包围函数中的一个局部变量,我们会让captureUpvalue()执行该工作。
否则,我们会从包围函数中捕获一个 upvalue。OP_CLOSURE指令在函数声明的末尾发出。在我们执行该声明时,当前函数是包围函数。这意味着当前函数的闭包存储在调用栈顶部的 CallFrame 中。因此,要从包围函数中获取一个 upvalue,我们可以直接从frame局部变量中读取它,该变量缓存对该 CallFrame 的引用。
闭包一个局部变量更有趣。大部分工作都在一个单独的函数中进行,但首先我们要计算要传递给它的参数。我们需要获取一个指向捕获的局部变量在包围函数的堆栈窗口中的槽的指针。该窗口从frame->slots开始,它指向槽 0。添加index偏移量将其偏移到我们想要捕获的局部变量槽。我们将这个指针传递到这里
在callValue()之后添加
static ObjUpvalue* captureUpvalue(Value* local) { ObjUpvalue* createdUpvalue = newUpvalue(local); return createdUpvalue; }
这看起来有点傻。它所做的只是创建一个新的 ObjUpvalue,捕获给定的堆栈槽并将其返回。我们需要为此单独创建一个函数吗?好吧,现在还不需要。但你知道我们最终会在里面添加更多代码的。
首先,让我们完成我们正在进行的工作。回到处理 `OP_CLOSURE` 的解释器代码中,我们最终完成了对 upvalue 数组的迭代,并初始化了每一个。当完成时,我们得到一个新的闭包,它拥有一个充满了指向变量的 upvalue 的数组。
有了它,我们就可以实现使用这些 upvalue 的指令了。
}
在 run() 中
case OP_GET_UPVALUE: { uint8_t slot = READ_BYTE(); push(*frame->closure->upvalues[slot]->location); break; }
case OP_EQUAL: {
操作数是当前函数的 upvalue 数组中的索引。因此,我们只需查找相应的 upvalue 并取消引用其位置指针,即可读取该槽中的值。设置变量类似。
}
在 run() 中
case OP_SET_UPVALUE: { uint8_t slot = READ_BYTE(); *frame->closure->upvalues[slot]->location = peek(0); break; }
case OP_EQUAL: {
我们 获取 堆栈顶部的值,并将其存储到由选择的 upvalue 指向的槽中。就像局部变量的指令一样,这些指令要快很重要。用户程序不断地读写变量,因此,如果这很慢,那么一切都将很慢。而且,像往常一样,我们让它们变快的方法是保持简单。这两个新的指令相当不错:没有控制流,没有复杂的算术运算,只是一些指针间接访问和一个 `push()`。
这是一个里程碑。只要所有变量都保留在堆栈中,我们就拥有了可工作的闭包。试试这个
fun outer() { var x = "outside"; fun inner() { print x; } inner(); } outer();
运行这个,它会正确地输出“outside”。
25 . 4闭包 Upvalue
当然,闭包的一个关键特性是,它们会一直持有变量,直到需要为止,即使声明该变量的函数已经返回了。以下是一个应该可以正常工作的另一个示例
fun outer() { var x = "outside"; fun inner() { print x; } return inner; } var closure = outer(); closure();
但是,如果你现在运行它 . . . 谁知道它会做什么?在运行时,它最终会从一个不再包含闭包变量的堆栈槽中读取。就像我之前提到的几次,问题的关键在于闭包中的变量没有堆栈语义。这意味着我们必须在声明它们的函数返回时,将它们从堆栈中移除。本章的最后一部分将完成这项工作。
25 . 4 . 1值和变量
在我们开始编写代码之前,我想深入探讨一个重要的语义点。闭包是闭包值还是变量?这不是一个纯粹的 学术问题。我不是在咬文嚼字。考虑一下
var globalSet; var globalGet; fun main() { var a = "initial"; fun set() { a = "updated"; } fun get() { print a; } globalSet = set; globalGet = get; } main(); globalSet(); globalGet();
外部的 `main()` 函数创建了两个闭包,并将它们存储在 全局变量中,以便它们比 `main()` 本身的执行时间更长。这两个闭包都捕获了同一个变量。第一个闭包为其分配了一个新值,第二个闭包读取了该变量。
调用 `globalGet()` 会输出什么?如果闭包捕获的是值,那么每个闭包都会获得 `a` 的一个副本,其中包含 `a` 在闭包的函数声明执行时所具有的值。调用 `globalSet()` 会修改 `set()` 的 `a` 副本,但 `get()` 的副本将不会受到影响。因此,调用 `globalGet()` 将输出“initial”。
如果闭包闭包的是变量,那么 `get()` 和 `set()` 都将捕获—引用—同一个可变变量。当 `set()` 改变 `a` 时,它改变的是 `get()` 从中读取的同一个 `a`。只有一个 `a`。反过来,这意味着调用 `globalGet()` 将输出“updated”。
哪一个是正确的?对于 Lox 和大多数其他我所知道的具有闭包的语言来说,答案是后者。闭包捕获变量。你可以认为它们是捕获值所在的位置。在处理不再位于堆栈中的闭包变量时,这一点很重要。当变量移动到堆时,我们需要确保所有捕获该变量的闭包都保留对该变量的一个新位置的引用。这样,当变量发生变异时,所有闭包都会看到这种变化。
25 . 4 . 2闭包 Upvalue
我们知道局部变量总是从堆栈开始。这更快,并且允许我们单遍编译器在发现变量已被捕获之前发出代码。我们也知道,如果闭包比声明捕获变量的函数存活的时间更长,则闭包变量需要移动到堆中。
遵循 Lua,我们将使用打开 Upvalue 来指代指向仍位于堆栈中的局部变量的 Upvalue。当变量移动到堆中时,我们正在关闭 Upvalue,结果自然是一个闭包 Upvalue。我们需要回答的两个问题是
-
闭包变量在堆的哪个位置?
-
我们什么时候关闭 Upvalue?
第一个问题的答案很简单。我们已经在堆中拥有一个方便的对象,它表示对变量的引用—ObjUpvalue 本身。闭包变量将移动到 ObjUpvalue 结构中的一个新字段中。这样,我们就不需要进行任何额外的堆分配来关闭 Upvalue。
第二个问题也很直接。只要变量位于堆栈中,可能会有代码引用它,并且这些代码必须正常工作。因此,将局部变量提升到堆中的最晚时间是尽可能晚。如果我们在局部变量超出范围时立即将其移动,那么我们就可以确定之后没有代码会尝试从堆栈中访问它。在变量超出范围之后,如果任何代码尝试使用它,编译器将会报告错误。
编译器在局部变量超出范围时,已经发出 `OP_POP` 指令。如果变量被闭包捕获,我们将发出一个不同的指令,将该变量从堆栈中提升到其相应的 Upvalue 中。为了做到这一点,编译器需要知道哪些 局部变量被闭包捕获。
编译器已经为函数中的每个局部变量维护了一个 Upvalue 结构数组,以跟踪确切的状态。该数组非常适合回答“这个闭包使用哪些变量?”但它不适合回答“任何函数是否捕获了这个局部变量?”特别是,一旦某个闭包的编译器完成,捕获了该变量的封闭函数的编译器将无法访问任何 Upvalue 状态。
换句话说,编译器维护着从 Upvalue 到它们捕获的局部变量的指针,但反过来则没有。因此,我们首先需要在现有的 Local 结构中添加一些额外的跟踪信息,以便我们能够判断给定的局部变量是否被闭包捕获。
int depth;
在 struct Local 中
bool isCaptured;
} Local;
如果局部变量被任何后续的嵌套函数声明捕获,则该字段为 `true`。最初,所有局部变量都没有被捕获。
local->depth = -1;
在 addLocal() 中
local->isCaptured = false;
}
同样地,编译器隐式声明的特殊“slot zero 局部变量”也没有被捕获。
local->depth = 0;
在 initCompiler() 中
local->isCaptured = false;
local->name.start = "";
在解析标识符时,如果我们最终为局部变量创建了一个 Upvalue,我们将将其标记为已捕获。
if (local != -1) {
在resolveUpvalue()中
compiler->enclosing->locals[local].isCaptured = true;
return addUpvalue(compiler, (uint8_t)local, true);
现在,在块范围结束时,当编译器发出代码来释放局部变量的堆栈槽时,我们可以知道哪些需要被提升到堆中。我们将使用一个新的指令来实现这一点。
while (current->localCount > 0 &&
current->locals[current->localCount - 1].depth >
current->scopeDepth) {
在 endScope() 中
替换 1 行
if (current->locals[current->localCount - 1].isCaptured) { emitByte(OP_CLOSE_UPVALUE); } else { emitByte(OP_POP); }
current->localCount--; }
该指令不需要操作数。我们知道,该变量始终会在执行该指令时位于堆栈顶部。我们声明该指令。
OP_CLOSURE,
在 enum OpCode 中
OP_CLOSE_UPVALUE,
OP_RETURN,
并添加对它的简单反汇编支持
}
在 disassembleInstruction() 中
case OP_CLOSE_UPVALUE: return simpleInstruction("OP_CLOSE_UPVALUE", offset);
case OP_RETURN:
很好。现在,生成的字节码告诉运行时每个捕获的局部变量必须何时移动到堆中。更好的是,它只对被闭包使用的局部变量执行此操作,这些变量需要特殊处理。这与我们的总体性能目标一致,即我们希望用户只为他们使用的功能付费。没有被闭包使用的变量完全在堆栈中生存和消亡,就像以前一样。
25 . 4 . 3跟踪打开 Upvalue
让我们转到运行时方面。在我们能够解释 `OP_CLOSE_UPVALUE` 指令之前,我们有一个问题需要解决。之前,当我谈到闭包是捕获变量还是值时,我说过,如果多个闭包访问同一个变量,那么它们最终应该引用内存中的同一个存储位置,这一点很重要。这样,如果一个闭包写入该变量,另一个闭包就能看到这种变化。
现在,如果两个闭包捕获了同一个 局部变量,那么 VM 会为每个闭包创建一个单独的 Upvalue。必要的共享是缺失的。当我们将变量从堆栈中移出时,如果我们只将其移入一个 Upvalue 中,那么另一个 Upvalue 将会得到一个孤立的值。
为了解决这个问题,无论何时 VM 需要一个捕获特定局部变量槽的 Upvalue,我们首先都会搜索一个指向该槽的现有 Upvalue。如果找到了,我们会重复使用它。挑战在于,所有之前创建的 Upvalue 都隐藏在各种闭包的 Upvalue 数组中。这些闭包可能位于 VM 内存的任何地方。
第一步是让 VM 拥有它自己的一个列表,其中包含所有指向仍然位于堆栈中的变量的打开 Upvalue。每次 VM 需要一个 Upvalue 时都搜索一个列表听起来可能很慢,但实际上并不是很慢。实际上,堆栈中真正被闭包捕获的变量数量往往很少。并且,创建闭包的函数声明很少出现在用户程序中的性能关键执行路径上。
更棒的是,我们可以根据它们指向的堆栈槽索引来排序打开 Upvalue 列表。常见的情况是,一个槽还没有被捕获—在闭包之间共享变量并不常见—并且闭包倾向于捕获堆栈顶部的局部变量。如果我们将打开 Upvalue 数组存储在堆栈槽顺序中,那么只要我们跨过包含我们正在捕获的局部变量的槽,我们就知道它不会被找到。当该局部变量位于堆栈顶部附近时,我们可以尽早退出循环。
维护排序列表需要有效地在中间插入元素。 这意味着使用链表而不是动态数组。 由于我们自己定义了 ObjUpvalue 结构体,最简单的实现是侵入式列表,它将 next 指针直接放在 ObjUpvalue 结构体本身中。
Value* location;
在 struct ObjUpvalue 中
struct ObjUpvalue* next;
} ObjUpvalue;
当我们分配一个 upvalue 时,它还没有附加到任何列表中,因此链接为 NULL。
upvalue->location = slot;
在 newUpvalue() 中
upvalue->next = NULL;
return upvalue;
VM 拥有列表,因此头指针直接位于主 VM 结构体中。
Table strings;
在 struct VM 中
ObjUpvalue* openUpvalues;
Obj* objects;
列表最初为空。
vm.frameCount = 0;
在 resetStack() 中
vm.openUpvalues = NULL;
}
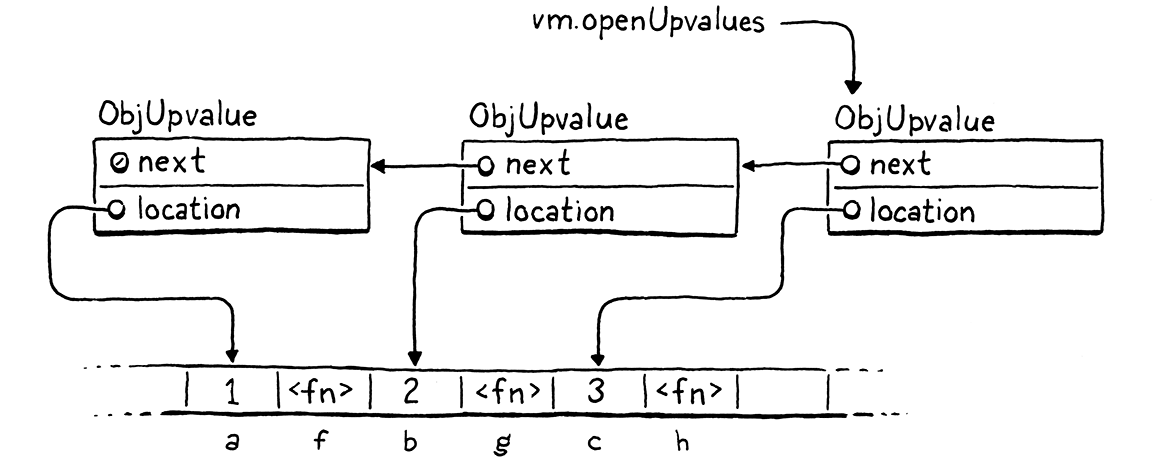
从 VM 指向的第一个 upvalue 开始,每个打开的 upvalue 都指向下一个打开的 upvalue,该 upvalue 引用堆栈中更远的局部变量。 例如,这个脚本:
{
var a = 1;
fun f() {
print a;
}
var b = 2;
fun g() {
print b;
}
var c = 3;
fun h() {
print c;
}
}
应该产生一系列链接的 upvalue,如下所示
每当我们闭包一个局部变量时,在创建新的 upvalue 之前,我们会在列表中查找现有的 upvalue。
static ObjUpvalue* captureUpvalue(Value* local) {
在 captureUpvalue() 中
ObjUpvalue* prevUpvalue = NULL; ObjUpvalue* upvalue = vm.openUpvalues; while (upvalue != NULL && upvalue->location > local) { prevUpvalue = upvalue; upvalue = upvalue->next; } if (upvalue != NULL && upvalue->location == local) { return upvalue; }
ObjUpvalue* createdUpvalue = newUpvalue(local);
我们从列表的 头部 开始,这是最靠近堆栈顶部的 upvalue。 我们遍历列表,使用一个小指针比较来迭代经过指向我们正在寻找的槽位上方的每个 upvalue。 在此过程中,我们跟踪列表中的前一个 upvalue。 如果我们最终在它之后插入节点,我们需要更新该节点的 next 指针。
有三个原因我们可以退出循环
-
我们停止的局部槽位就是我们正在寻找的槽位。 我们找到了一个捕获变量的现有 upvalue,因此我们重复使用该 upvalue。
-
我们没有可搜索的 upvalue。 当
upvalue为NULL时,这意味着列表中的每个打开的 upvalue 都指向我们正在寻找的槽位上方的本地变量,或者(更可能)upvalue 列表为空。 无论哪种情况,我们都没有找到我们槽位的 upvalue。 -
我们找到了一个其局部槽位位于我们正在寻找的槽位下方的 upvalue。 由于列表已排序,这意味着我们已经越过了我们正在闭包的槽位,因此一定不存在该槽位的现有 upvalue。
在第一种情况下,我们完成了,并返回。 否则,我们为我们的局部槽位创建一个新的 upvalue,并将它插入到列表中的正确位置。
ObjUpvalue* createdUpvalue = newUpvalue(local);
在 captureUpvalue() 中
createdUpvalue->next = upvalue; if (prevUpvalue == NULL) { vm.openUpvalues = createdUpvalue; } else { prevUpvalue->next = createdUpvalue; }
return createdUpvalue;
此函数的当前版本已经创建了 upvalue,因此我们只需要添加代码将 upvalue 插入到列表中。 我们通过越过列表的末尾或在第一个其堆栈槽位位于我们正在寻找的槽位下方的 upvalue 上停止,退出了列表遍历。 在任何一种情况下,这意味着我们需要在 upvalue 指向的对象(如果我们到达列表末尾,则可能为 NULL)之前插入新的 upvalue。
正如你可能在数据结构 101 中学到的那样,要将节点插入到链表中,你需要将前一个节点的 next 指针指向你的新节点。 我们一直在遍历列表时方便地跟踪该前一个节点。 我们还需要处理将新 upvalue 插入到列表头部的 特殊 情况,在这种情况下,“next”指针是 VM 的头指针。
使用此更新后的函数,VM 现在确保对于任何给定的局部槽位,永远只有一个 ObjUpvalue。 如果两个闭包捕获了同一个变量,它们将获得同一个 upvalue。 我们现在可以将这些 upvalue 从堆栈中移出。
25 . 4 . 4在运行时关闭 upvalue
编译器帮助地发出 OP_CLOSE_UPVALUE 指令,告诉 VM 局部变量何时应该提升到堆上。 执行该指令是解释器的责任。
}
在 run() 中
case OP_CLOSE_UPVALUE: closeUpvalues(vm.stackTop - 1); pop(); break;
case OP_RETURN: {
当我们到达指令时,我们正在提升的变量位于堆栈的顶部。 我们调用一个辅助函数,传递该堆栈槽位的地址。 该函数负责关闭 upvalue 并将局部变量从堆栈移动到堆。 之后,VM 可以自由丢弃堆栈槽位,它通过调用 pop() 来实现。
有趣的事情发生在这里
在 captureUpvalue() 之后添加
static void closeUpvalues(Value* last) { while (vm.openUpvalues != NULL && vm.openUpvalues->location >= last) { ObjUpvalue* upvalue = vm.openUpvalues; upvalue->closed = *upvalue->location; upvalue->location = &upvalue->closed; vm.openUpvalues = upvalue->next; } }
此函数接受指向堆栈槽位的指针。 它关闭所有它能找到的指向该槽位或堆栈上任何位于该槽位上方的槽位的打开的 upvalue。 现在,我们只传递指向堆栈顶部的槽位的指针,因此“或位于其上方”部分不起作用,但很快就会起作用。
为此,我们从上到下遍历 VM 的打开 upvalue 列表。 如果 upvalue 的位置指向我们正在关闭的槽位范围,我们关闭 upvalue。 否则,一旦我们到达范围之外的 upvalue,我们就知道其余的 upvalue 也在范围之外,因此我们停止迭代。
关闭 upvalue 的方式非常 酷。 首先,我们将变量的值复制到 ObjUpvalue 中的 closed 字段中。 闭包变量就住在堆中的这里。 OP_GET_UPVALUE 和 OP_SET_UPVALUE 指令需要在变量移动后在那里寻找该变量。 我们可以向这些指令的解释器代码中添加一些条件逻辑,以检查 upvalue 是否打开或关闭的标志。
但是已经存在一层间接寻址—这些指令取消引用 location 指针以获取变量的值。 当变量从堆栈移动到 closed 字段时,我们只需将该 location 更新为指向 ObjUpvalue 自己的 closed 字段的地址。
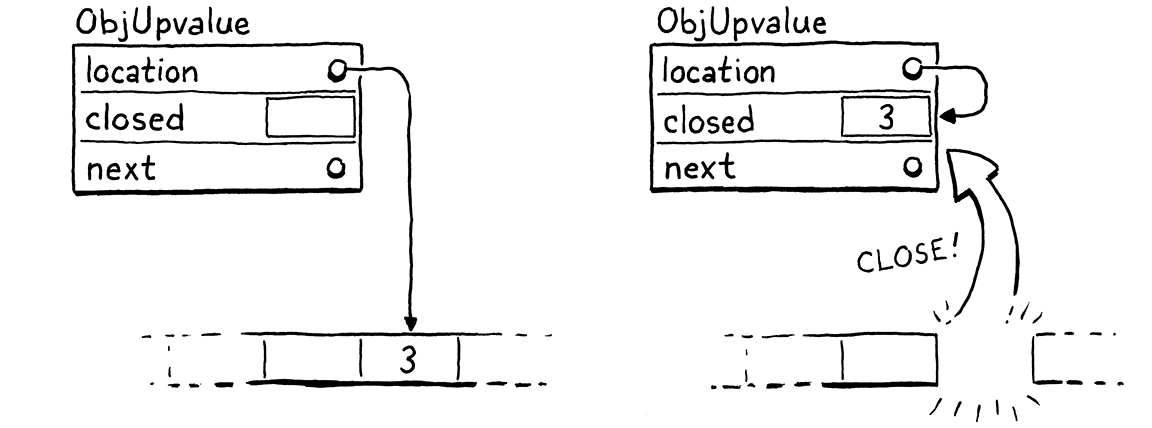
我们不需要更改 OP_GET_UPVALUE 和 OP_SET_UPVALUE 的解释方式。 这使它们保持简单,从而使它们保持快速。 但是,我们需要向 ObjUpvalue 添加新字段。
Value* location;
在 struct ObjUpvalue 中
Value closed;
struct ObjUpvalue* next;
当我们创建 ObjUpvalue 时,我们应该将其清零,这样就不会有任何未初始化的内存四处漂浮。
ObjUpvalue* upvalue = ALLOCATE_OBJ(ObjUpvalue, OBJ_UPVALUE);
在 newUpvalue() 中
upvalue->closed = NIL_VAL;
upvalue->location = slot;
每当编译器到达块的末尾时,它都会丢弃该块中的所有局部变量,并为每个被闭包的局部变量发出 OP_CLOSE_UPVALUE。 编译器 不会 在定义函数体的最外层块作用域的末尾发出任何指令。 该作用域包含函数的参数以及在函数内部立即声明的任何局部变量。 这些也需要被关闭。
这就是 closeUpvalues() 接受指向堆栈槽位的指针的原因。 当函数返回时,我们调用同一个辅助函数,并将函数拥有的第一个堆栈槽位传递进去。
Value result = pop();
在 run() 中
closeUpvalues(frame->slots);
vm.frameCount--;
通过传递函数堆栈窗口中的第一个槽位,我们关闭了返回函数拥有的所有剩余的打开的 upvalue。 这样一来,我们现在就有了功能齐全的闭包实现。 闭包变量的生存期与捕获它们的函数一样长。
这真是太费劲了! 在 jlox 中,闭包从我们的环境表示中自然地产生。 在 clox 中,我们不得不添加很多代码—新的字节码指令,编译器中的更多数据结构,以及新的运行时对象。 VM 非常重视闭包中的变量与其他变量的不同之处。
这是有道理的。 就实现复杂性而言,jlox 为我们提供了“免费”的闭包。 但就性能而言,jlox 的闭包绝非如此。 通过在堆上分配所有环境,jlox 为所有局部变量支付了巨大的性能代价,即使大多数局部变量从未被闭包捕获。
有了 clox,我们拥有一个更复杂的系统,但这让我们可以根据我们观察到的局部变量的两种使用模式,来定制实现。 对于大多数具有堆栈语义的变量,我们完全在堆栈上分配它们,这很简单且快速。 然后,对于少数不适合这种模式的局部变量,我们有一个可以根据需要选择使用的第二条更慢的路径。
幸运的是,用户没有感觉到这种复杂性。 从他们的角度来看,Lox 中的局部变量是简单且一致的。 语言本身与 jlox 的实现一样简单。 但在幕后,clox 正在观察用户的操作,并针对他们的特定用途进行优化。 随着你的语言实现越来越复杂,你会发现自己会越来越多地这样做。 大部分“优化”都是关于添加特殊情况代码,检测某些用法并为符合该模式的代码提供定制构建的更快路径。
我们现在在 clox 中完全实现了词法作用域,这是一个重要的里程碑。 而且,现在我们有了具有复杂生存期的函数和变量,clox 的堆中也漂浮着很多对象,它们之间通过指针网络连接在一起。 下一步就是弄清楚如何管理这些内存,以便我们可以在不再需要时释放其中一些对象。
挑战
-
将每个 ObjFunction 包裹在 ObjClosure 中会引入一层间接寻址,这会带来性能成本。 对于没有闭包任何变量的函数来说,这种成本是不必要的,但它确实可以让运行时统一地处理所有调用。
更改 clox,只将需要 upvalue 的函数包裹在 ObjClosure 中。 代码复杂度和性能与始终包裹函数相比如何? 注意对使用和不使用闭包的程序进行基准测试。 你应该如何衡量每个基准测试的重要性? 如果一个变慢了,另一个变快了,你如何决定做出什么权衡来选择实现策略?
-
阅读下面的设计说明。 我会等你。 现在,你认为 Lox 应该如何表现? 更改实现,为每次循环迭代创建一个新变量。
-
一个 著名的公案 教导我们,“对象是穷人的闭包”(反之亦然)。 我们的 VM 还不支持对象,但现在我们有了闭包,我们可以模拟它们。 使用闭包,编写一个 Lox 程序来模拟二维向量“对象”。 它应该
-
定义一个“构造函数”函数来创建一个具有给定x 和y 坐标的新向量。
-
提供“方法”来访问从该构造函数返回的值的x 和y 坐标。
-
定义一个加法“方法”,它添加两个向量并产生第三个向量。
-
设计说明:闭包循环变量
闭包捕获变量。 当两个闭包捕获同一个变量时,它们共享对同一个底层存储位置的引用。 当为变量赋值时,这个事实是可见的。 显然,如果两个闭包捕获不同的变量,就不会共享。
var globalOne; var globalTwo; fun main() { { var a = "one"; fun one() { print a; } globalOne = one; } { var a = "two"; fun two() { print a; } globalTwo = two; } } main(); globalOne(); globalTwo();
这将打印“one”,然后打印“two”。 在这个例子中,很明显这两个 a 变量是不同的。 但并不总是那么明显。 考虑以下代码
var globalOne; var globalTwo; fun main() { for (var a = 1; a <= 2; a = a + 1) { fun closure() { print a; } if (globalOne == nil) { globalOne = closure; } else { globalTwo = closure; } } } main(); globalOne(); globalTwo();
代码很复杂,因为 Lox 没有集合类型。重要的是 main() 函数对 for 循环执行了两次迭代。每次循环,它都会创建一个闭包来捕获循环变量。它将第一个闭包存储在 globalOne 中,第二个存储在 globalTwo 中。
肯定有两个不同的闭包。它们是否闭合了两个不同的变量?整个循环过程中只有一个 a,还是每次迭代都得到它自己的 a 变量?
这里的脚本很奇怪,而且很牵强,但这确实出现在像 clox 一样不那么简化的语言的真实代码中。这是一个 JavaScript 示例
var closures = []; for (var i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
它打印 “1” 然后 “2”,还是打印 “3” 两次?您可能会惊讶地发现它打印了 “3” 两次。在这个 JavaScript 程序中,只有一个 i 变量,它的生命周期包括循环的所有迭代,包括最终的退出。
如果您熟悉 JavaScript,您可能知道使用 var 声明的变量隐式地提升到周围的函数或顶层范围。就好像您真的写了这个
var closures = []; var i; for (i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
在这一点上,很明显只有一个 i。现在考虑一下,如果您将程序更改为使用较新的 let 关键字
var closures = []; for (let i = 1; i <= 2; i++) { closures.push(function () { console.log(i); }); } closures[0](); closures[1]();
这个新程序的行为相同吗?不。在这种情况下,它打印了 “1” 然后 “2”。每个闭包都有它自己的 i。当你想到的时候,这有点奇怪。增量子句是 i++。这看起来非常像它正在分配和修改现有变量,而不是创建新的变量。
让我们尝试其他一些语言。这是 Python
closures = [] for i in range(1, 3): closures.append(lambda: print(i)) closures[0]() closures[1]()
Python 实际上没有块范围。变量是隐式声明的,并且自动作用于周围的函数。现在想想,有点像 JS 中的提升。所以这两个闭包都捕获了同一个变量。不过,与 C 不同的是,我们不会通过将 i 超过最后一个值来增加 i 来退出循环,因此它打印了 “2” 两次。
Ruby 呢?Ruby 有两种典型的数字迭代方式。这是经典的命令式风格
closures = [] for i in 1..2 do closures << lambda { puts i } end closures[0].call closures[1].call
这与 Python 一样,打印了 “2” 两次。但是更惯用的 Ruby 风格是在范围对象上使用高阶 each() 方法
closures = [] (1..2).each do |i| closures << lambda { puts i } end closures[0].call closures[1].call
如果您不熟悉 Ruby,do |i| ... end 部分基本上是一个闭包,它被创建并传递给 each() 方法。|i| 是闭包的参数签名。each() 方法调用该闭包两次,第一次传递 1 作为 i,第二次传递 2。
在这种情况下,“循环变量”实际上是一个函数参数。而且,由于循环的每次迭代都是对函数的单独调用,因此每次调用肯定都是单独的变量。因此,它打印了 “1” 然后 “2”。
如果一种语言具有像 C# 中的 foreach、Java 的“增强 for”、JavaScript 中的 for-of、Dart 中的 for-in 等等一样的高级基于迭代器的循环结构,那么我认为对读者来说,每次迭代都创建一个新变量是自然的。代码看起来像一个新变量,因为循环标题看起来像一个变量声明。而且没有增量表达式看起来像是它正在修改该变量以推进到下一步。
如果您在 StackOverflow 和其他地方四处寻找,您会发现证据表明这是用户期望的,因为当他们没有得到它时,他们会非常惊讶。特别是,C# 最初没有为 foreach 循环的每次迭代创建一个新的循环变量。这是一个用户困惑的常见来源,因此他们采取了非常罕见的步骤来发布对语言的重大更改。在 C# 5 中,每次迭代都会创建一个新的变量。
旧的 C 样式 for 循环更难。增量子句确实看起来像修改。这意味着有一个单一的变量,它在每一步都被更新。但对于每次迭代来说,共享一个循环变量几乎从来没有用处。您唯一可以检测到它的时间是当闭包捕获它时。而且,很少有帮助让闭包引用一个变量,该变量的值是导致您退出循环的值。
从实用角度来看,可能是做 JavaScript 在 for 循环中对 let 所做的事情。让它看起来像修改,但实际上每次都创建一个新变量,因为这是用户想要的。不过,当你想到它的时候,这有点奇怪。