局部变量
正如想象力塑造
未知事物的形式,诗人的笔
将它们变成形状,并赋予空无一物
一个本地住所和一个名字。威廉·莎士比亚,仲夏夜之梦
在上一章中,我们向 clox 引入了变量,但只有全局变量。在本章中,我们将扩展到支持块、块作用域和局部变量。在 jlox 中,我们成功地将所有这些以及全局变量都打包到一章中。对于 clox,这相当于两章的工作,部分原因是,坦率地说,在 C 中一切都需要付出更多的努力。
但更重要的原因是,我们对局部变量的处理方式将与我们实现全局变量的方式大不相同。全局变量在 Lox 中是后期绑定的。“后期”在这个上下文中意味着“在编译时之后解析”。这有利于保持编译器简单,但不利于性能。局部变量是语言中最常用的部分之一。如果局部变量很慢,所有东西都很慢。所以我们想要一个尽可能高效的局部变量策略。
幸运的是,词法作用域可以帮助我们。顾名思义,词法作用域意味着我们可以通过查看程序的文本—局部变量不是后期绑定的。我们在编译器中做的任何处理工作都是我们在运行时不需要做的工作,因此我们对局部变量的实现将很大程度上依赖于编译器。
22 . 1 局部变量的表示
在现代时代对编程语言进行黑客攻击的好处是,有许多其他语言的血统可以借鉴。那么,C 和 Java 如何管理它们的局部变量?为什么,当然是在栈上!它们通常使用芯片和操作系统支持的本机栈机制。这对我们来说有点太底层了,但在 clox 的虚拟世界中,我们有自己的栈可以使用。
现在,我们只使用它来保存临时变量—计算表达式时需要记住的短期数据块。只要我们不阻碍它们,我们也可以将局部变量塞入栈中。这对性能很有利。为一个新的局部变量分配空间只需要递增stackTop指针,释放同样也是一个递减。从已知栈槽访问变量是一个索引数组查找。
不过,我们需要注意。VM 期望栈的行为就像一个栈。我们必须能够接受仅在栈顶分配新的局部变量,并且我们必须接受只有在栈上没有任何东西在它之上时才能丢弃一个局部变量。此外,我们需要确保临时变量不会干扰。
方便的是,Lox 的设计与这些约束协调一致。新的局部变量总是由声明语句创建。语句不会嵌套在表达式中,因此在语句开始执行时,栈上永远不会有临时变量。块是严格嵌套的。当一个块结束时,它总是会带走最里面的、最近声明的局部变量。由于这些也是最后进入作用域的局部变量,因此它们应该位于栈顶,那里是我们需要它们的地方。
逐步执行此示例程序,并观察局部变量是如何进入和退出作用域的
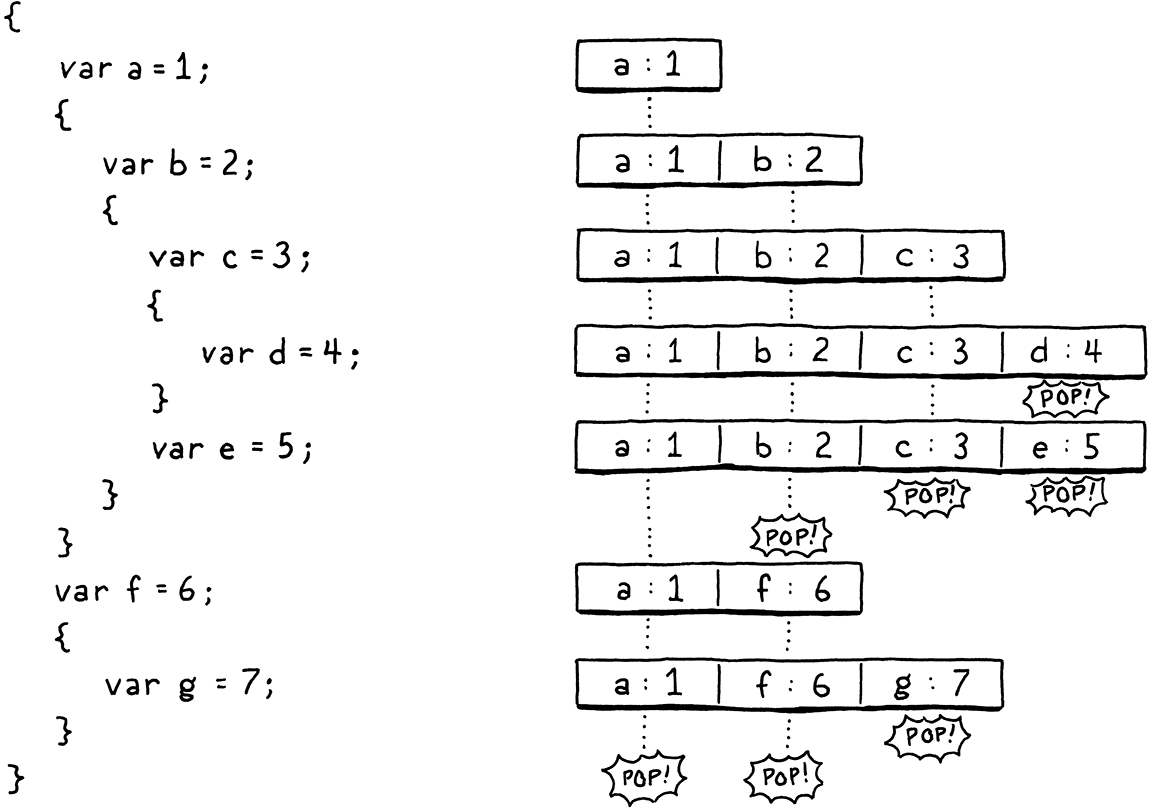
看看它们是如何完美地适应栈的?看来栈可以用来在运行时存储局部变量。但我们还可以更进一步。我们不仅知道它们将在栈上,我们甚至可以精确地确定它们将在栈上的位置。由于编译器准确地知道在任何时间点哪些局部变量在作用域中,它可以在编译期间有效地模拟栈,并记录每个变量在栈中的位置。
我们将通过使用这些栈偏移量作为读取和存储局部变量的字节码指令的操作数来利用这一点。这使得处理局部变量变得非常快—就像索引数组一样简单。
我们需要跟踪编译器中的许多状态才能使整个过程进行,所以让我们从那里开始。在 jlox 中,我们使用一个名为“环境”的 HashMap 的链接链来跟踪当前处于作用域中的哪些局部变量。这有点类似于经典的、教科书式的表示词法作用域的方式。对于 clox,像往常一样,我们将更加接近底层。所有状态都保存在一个新的结构体中。
} ParseRule;
在 struct ParseRule 之后添加
typedef struct { Local locals[UINT8_COUNT]; int localCount; int scopeDepth; } Compiler;
Parser parser;
我们有一个简单的、扁平的数组,包含在编译过程中的每个时间点都处于作用域中的所有局部变量。它们在数组中的排序顺序与它们在代码中的声明顺序相同。由于我们将用于编码局部变量的指令操作数是一个字节,因此我们的 VM 对一次处于作用域中的局部变量数量有一个硬性限制。这意味着我们也可以给局部变量数组赋予一个固定大小。
#define DEBUG_TRACE_EXECUTION
#define UINT8_COUNT (UINT8_MAX + 1)
#endif
回到 Compiler 结构体中,localCount 字段跟踪处于作用域中的局部变量数量—数组中有多少个槽位正在使用。我们还跟踪“作用域深度”。这是当前正在编译的代码块周围的块数量。
我们的 Java 解释器使用一个映射链来将每个块的变量与其他块的变量分开。这次,我们只需用变量出现的嵌套级别对变量进行编号。零是全局作用域,一是第一个顶层块,二是其内部,你明白了。我们使用它来跟踪每个局部变量属于哪个块,以便我们知道在块结束时要丢弃哪些局部变量。
数组中的每个局部变量都是以下之一
} ParseRule;
在 struct ParseRule 之后添加
typedef struct { Token name; int depth; } Local;
typedef struct {
我们存储变量的名称。当我们解析一个标识符时,我们将标识符的词素与每个局部变量的名称进行比较以找到匹配项。如果你不知道一个变量的名称,就很难解析它。depth 字段记录声明局部变量的块的作用域深度。到目前为止,这些是我们需要的所有状态。
这与我们在 jlox 中使用的表示方式大不相同,但它仍然让我们能够回答编译器需要从词法环境中获取的所有问题。下一步是弄清楚编译器如何获取这些状态。如果我们是有原则的工程师,我们会给前端的每个函数传递一个参数,该参数接收指向 Compiler 的指针。我们会在开始时创建一个 Compiler,并小心地将其传递到每个函数调用中 . . . 但这意味着要对我们已经编写的代码进行很多无聊的修改,所以这里我们将使用一个全局变量代替
Parser parser;
在变量 parser 之后添加
Compiler* current = NULL;
Chunk* compilingChunk;
这里有一个小函数来初始化编译器
在 emitConstant() 之后添加
static void initCompiler(Compiler* compiler) { compiler->localCount = 0; compiler->scopeDepth = 0; current = compiler; }
当我们第一次启动 VM 时,我们会调用它来将所有东西都置于干净的状态。
initScanner(source);
在 compile() 中
Compiler compiler; initCompiler(&compiler);
compilingChunk = chunk;
我们的编译器拥有它需要的数据,但没有操作这些数据的方法。没有办法创建和销毁作用域,或者添加和解析变量。我们将根据需要添加这些功能。首先,让我们开始构建一些语言特性。
22 . 2 块语句
在我们拥有任何局部变量之前,我们需要一些局部作用域。这些来自两件事:函数体和块。函数是一大块工作,我们将在以后的章节中处理,所以现在我们只处理块。像往常一样,我们从语法开始。我们将引入的新语法是
statement → exprStmt | printStmt | block ; block → "{" declaration* "}" ;
块是一种语句,所以它的规则位于statement 产生式中。编译一个块的相应代码如下所示
if (match(TOKEN_PRINT)) {
printStatement();
在 statement() 中
} else if (match(TOKEN_LEFT_BRACE)) { beginScope(); block(); endScope();
} else {
在解析了初始的大括号之后,我们使用此辅助函数来编译块的其余部分
在 expression() 之后添加
static void block() { while (!check(TOKEN_RIGHT_BRACE) && !check(TOKEN_EOF)) { declaration(); } consume(TOKEN_RIGHT_BRACE, "Expect '}' after block."); }
它会一直解析声明和语句,直到遇到右大括号。与解析器中的任何循环一样,我们也会检查令牌流的结束位置。这样,如果程序格式错误,缺少右大括号,编译器就不会陷入循环。
执行一个块只是意味着按顺序执行它包含的语句,因此编译它们并没有太多内容。块在语义上做的事情是创建作用域。在我们编译块的主体之前,我们会调用此函数来进入一个新的局部作用域
在 endCompiler() 之后添加
static void beginScope() { current->scopeDepth++; }
为了“创建”一个作用域,我们只需要增加当前深度。这当然比 jlox 快得多,jlox 为每个作用域分配了一个全新的 HashMap。有了 beginScope(),你可能就能猜到 endScope() 是做什么的了。
在 beginScope() 后添加
static void endScope() { current->scopeDepth--; }
关于块和作用域,就这些了——差不多吧——所以我们准备往里面塞一些变量。
22 . 3声明局部变量
通常我们从解析开始,但是我们的编译器已经支持解析和编译变量声明。我们现在已经有了 var 语句、标识符表达式和赋值。只是编译器假设所有变量都是全局变量。所以我们不需要任何新的解析支持,只需要将新的作用域语义连接到现有的代码中。
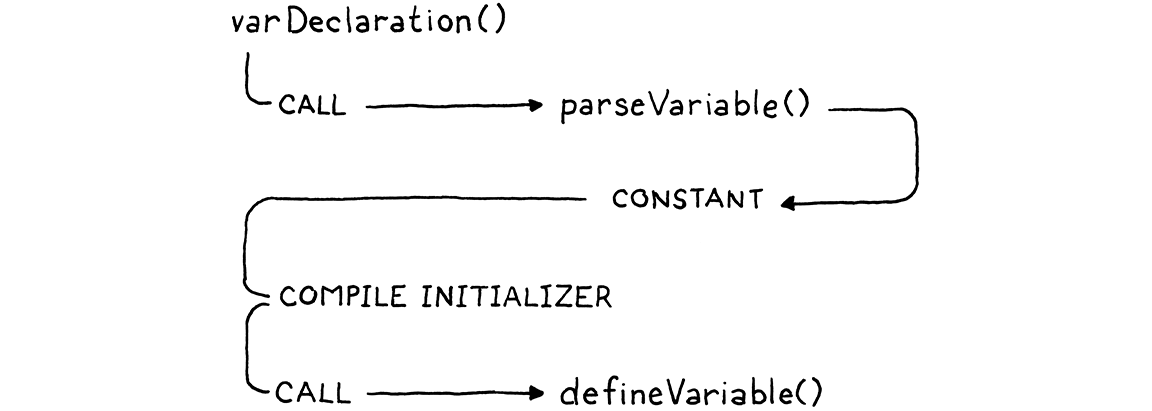
变量声明解析从 varDeclaration() 开始,并依赖于几个其他函数。首先,parseVariable() 使用变量名的标识符标记,将它的词素添加到块的常量表中作为字符串,然后返回它被添加到的常量表索引。然后,在 varDeclaration() 编译初始化器之后,它调用 defineVariable() 来发出字节码,用于将变量的值存储在全局变量哈希表中。
这两个辅助函数都需要一些更改才能支持局部变量。在 parseVariable() 中,我们添加了
consume(TOKEN_IDENTIFIER, errorMessage);
在 parseVariable() 中
declareVariable(); if (current->scopeDepth > 0) return 0;
return identifierConstant(&parser.previous);
首先,我们“声明”变量。我将在稍后解释这意味着什么。之后,如果我们在局部作用域中,我们就退出函数。在运行时,局部变量不会通过名称查找。不需要将变量名塞进常量表中,所以如果声明在局部作用域内,我们就返回一个虚拟的表索引。
在 defineVariable() 中,如果我们在局部作用域内,我们需要发出存储局部变量的代码。看起来像这样
static void defineVariable(uint8_t global) {
在 defineVariable() 中
if (current->scopeDepth > 0) { return; }
emitBytes(OP_DEFINE_GLOBAL, global);
等等,什么?是的。就是这样。在运行时没有创建局部变量的代码。想想 VM 的状态。它已经执行了变量初始化器的代码(如果用户省略了初始化器,则为隐式的 nil),并且该值作为唯一剩余的临时变量,正位于堆栈顶部。我们也知道新的局部变量是在堆栈顶部分配的——就在该值所在的位置。因此,没什么需要做的。临时变量就变成了局部变量。效率再高不过了。
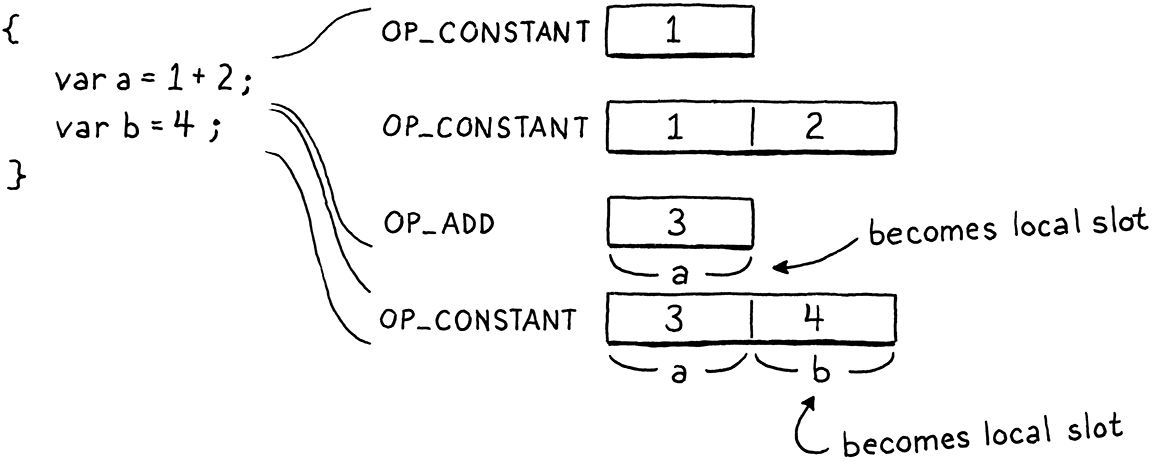
好的,那么“声明”是什么?这就是它的作用
在 identifierConstant() 后添加
static void declareVariable() { if (current->scopeDepth == 0) return; Token* name = &parser.previous; addLocal(*name); }
这是编译器记录变量存在的点。我们只对局部变量这样做,所以如果我们在顶层全局作用域中,我们只需要退出。因为全局变量是后期绑定的,所以编译器不会跟踪它已经看到了哪些声明。
但是对于局部变量,编译器确实需要记住变量存在。这就是声明它的作用——将它添加到编译器当前作用域的变量列表中。我们使用另一个新函数来实现它。
在 identifierConstant() 后添加
static void addLocal(Token name) { Local* local = ¤t->locals[current->localCount++]; local->name = name; local->depth = current->scopeDepth; }
这将初始化编译器变量数组中的下一个可用 Local。它存储了变量的 名称 和拥有该变量的作用域的深度。
我们的实现对于正确的 Lox 程序来说是没问题的,但是对于无效代码呢?让我们力求健壮。第一个需要处理的错误并非真正是用户的错,而是 VM 的限制。操作局部变量的指令通过槽索引引用它们。该索引存储在一个单字节操作数中,这意味着 VM 只能在任何时候支持最多 256 个局部变量处于作用域内。
如果我们试图超过这个限制,不仅我们无法在运行时引用它们,而且编译器也会覆盖它自己的局部变量数组。让我们阻止这种情况发生。
static void addLocal(Token name) {
在 addLocal() 中
if (current->localCount == UINT8_COUNT) { error("Too many local variables in function."); return; }
Local* local = ¤t->locals[current->localCount++];
下一个案例比较棘手。考虑
{
var a = "first";
var a = "second";
}
在顶层,Lox 允许用与先前声明相同的名称重新声明变量,因为这对 REPL 很有用。但是在局部作用域内,这样做很 奇怪。这很可能是错误,许多语言,包括我们自己的 Lox,将这一假设奉为圭臬,将其视为错误。
请注意,上面的程序与下面的程序不同
{
var a = "outer";
{
var a = "inner";
}
}
在不同的作用域中拥有两个具有相同名称的变量是可以的,即使作用域重叠,使得两个变量同时可见。这就是遮蔽,Lox 允许这样做。只有在相同的局部作用域中拥有两个具有相同名称的变量才会出错。
我们这样检测这个错误
Token* name = &parser.previous;
在 declareVariable() 中
for (int i = current->localCount - 1; i >= 0; i--) { Local* local = ¤t->locals[i]; if (local->depth != -1 && local->depth < current->scopeDepth) { break; } if (identifiersEqual(name, &local->name)) { error("Already a variable with this name in this scope."); } }
addLocal(*name); }
在声明局部变量时,它们会被附加到数组中,这意味着当前作用域总是在数组的末尾。当我们声明一个新变量时,我们从末尾开始,向后查找具有相同名称的现有变量。如果我们在当前作用域中找到一个,我们就报告错误。否则,如果我们到达数组的开头或另一个作用域拥有的变量,那么我们就知道我们已经检查了作用域中的所有现有变量。
要查看两个标识符是否相同,我们使用以下方法
在 identifierConstant() 后添加
static bool identifiersEqual(Token* a, Token* b) { if (a->length != b->length) return false; return memcmp(a->start, b->start, a->length) == 0; }
由于我们知道两个词素的长度,因此我们首先检查长度。这将使许多不相等的字符串快速失败。如果长度相同,我们使用 memcmp() 检查字符。要使用 memcmp(),我们需要一个包含文件。
#include <stdlib.h>
#include <string.h>
#include "common.h"
有了这些,我们就可以让变量存在了。但是,就像鬼魂一样,它们会在声明它们的范围之外徘徊。当一个块结束时,我们需要让它们安息。
current->scopeDepth--;
在 endScope() 中
while (current->localCount > 0 && current->locals[current->localCount - 1].depth > current->scopeDepth) { emitByte(OP_POP); current->localCount--; }
}
当我们弹出作用域时,我们向后遍历局部变量数组,查找在刚离开的作用域深度声明的任何变量。我们通过简单地减少数组的长度来丢弃它们。
这方面也有一些运行时组件。局部变量占用堆栈上的槽。当局部变量超出作用域时,该槽不再需要,应该被释放。因此,对于我们丢弃的每个变量,我们也会发出一个 OP_POP 指令,将其从堆栈中弹出。
22 . 4使用局部变量
我们现在可以编译和执行局部变量声明。在运行时,它们的值将位于堆栈中的正确位置。让我们开始使用它们。我们将同时执行变量访问和赋值,因为它们会触及编译器中的相同函数。
我们已经有了获取和设置全局变量的代码,并且——就像优秀的软件工程师——我们想要尽可能多地重用现有的代码。类似于
static void namedVariable(Token name, bool canAssign) {
在 namedVariable() 中
替换 1 行
uint8_t getOp, setOp; int arg = resolveLocal(current, &name); if (arg != -1) { getOp = OP_GET_LOCAL; setOp = OP_SET_LOCAL; } else { arg = identifierConstant(&name); getOp = OP_GET_GLOBAL; setOp = OP_SET_GLOBAL; }
if (canAssign && match(TOKEN_EQUAL)) {
我们没有对变量访问和赋值发出的字节码指令进行硬编码,而是使用几个 C 变量。首先,我们尝试找到一个具有给定名称的局部变量。如果我们找到了,我们使用用于操作局部变量的指令。否则,我们假设它是一个全局变量,并使用现有的全局变量字节码指令。
再往下一段,我们使用这些变量来发出正确的指令。对于赋值
if (canAssign && match(TOKEN_EQUAL)) {
expression();
在 namedVariable() 中
替换 1 行
emitBytes(setOp, (uint8_t)arg);
} else {
对于访问
emitBytes(setOp, (uint8_t)arg);
} else {
在 namedVariable() 中
替换 1 行
emitBytes(getOp, (uint8_t)arg);
}
本章的核心,即我们解析局部变量的部分,在这里
在 identifiersEqual() 后添加
static int resolveLocal(Compiler* compiler, Token* name) { for (int i = compiler->localCount - 1; i >= 0; i--) { Local* local = &compiler->locals[i]; if (identifiersEqual(name, &local->name)) { return i; } } return -1; }
尽管如此,它还是很简单。我们遍历当前处于作用域的局部变量列表。如果一个局部变量的名称与标识符标记相同,那么标识符必须引用该变量。我们找到了它!我们向后遍历数组,以便找到最后声明的具有该标识符的变量。这确保了内部局部变量能够正确地遮蔽周围作用域中具有相同名称的局部变量。
在运行时,我们使用堆栈槽索引来加载和存储局部变量,因此这就是编译器在解析变量后需要计算的内容。每当声明一个变量时,我们都会将其追加到 Compiler 中的局部变量数组。这意味着第一个局部变量位于索引零处,下一个位于索引一处,依此类推。换句话说,编译器中的局部变量数组与 VM 在运行时将具有的堆栈布局完全相同。变量在局部变量数组中的索引与其堆栈槽相同。多么方便!
如果我们在整个数组中遍历而没有找到具有给定名称的变量,那么它一定不是局部变量。在这种情况下,我们返回 -1 来表示没有找到,应该假设它是一个全局变量。
22 . 4 . 1解释局部变量
我们的编译器发出了两个新的指令,所以让我们让它们工作起来。第一个是加载局部变量
OP_POP,
在 enum OpCode 中
OP_GET_LOCAL,
OP_GET_GLOBAL,
及其实现
case OP_POP: pop(); break;
在 run() 中
case OP_GET_LOCAL: { uint8_t slot = READ_BYTE(); push(vm.stack[slot]); break; }
case OP_GET_GLOBAL: {
它使用一个单字节操作数来表示局部变量所在的堆栈槽。它从该索引中加载值,然后将其推送到堆栈顶部,以便后面的指令可以找到它。
接下来是赋值
OP_GET_LOCAL,
在 enum OpCode 中
OP_SET_LOCAL,
OP_GET_GLOBAL,
你可能已经可以预测出它的实现。
}
在 run() 中
case OP_SET_LOCAL: { uint8_t slot = READ_BYTE(); vm.stack[slot] = peek(0); break; }
case OP_GET_GLOBAL: {
它从堆栈顶部获取赋值的值,并将其存储在对应于局部变量的堆栈槽中。请注意,它不会从堆栈中弹出该值。记住,赋值是一个表达式,每个表达式都会产生一个值。赋值表达式的值是赋值的值本身,因此 VM 只将该值留在堆栈上。
如果没有对这两个新指令的支持,我们的反汇编器是不完整的。
return simpleInstruction("OP_POP", offset);
在 disassembleInstruction() 中
case OP_GET_LOCAL: return byteInstruction("OP_GET_LOCAL", chunk, offset); case OP_SET_LOCAL: return byteInstruction("OP_SET_LOCAL", chunk, offset);
case OP_GET_GLOBAL:
编译器将局部变量编译为直接插槽访问。局部变量的名称根本不会离开编译器进入块。这对性能来说很棒,但对自省来说却不太好。当我们反汇编这些指令时,我们无法像全局变量那样显示变量的名称。相反,我们只显示插槽编号。
在 `simpleInstruction()` 后添加
static int byteInstruction(const char* name, Chunk* chunk, int offset) { uint8_t slot = chunk->code[offset + 1]; printf("%-16s %4d\n", name, slot); return offset + 2; }
22 . 4 . 2 另一个作用域边缘情况
我们已经花了一些时间来处理围绕作用域的几个奇怪的边缘情况。我们确保阴影工作正常。如果同一局部作用域中的两个变量具有相同的名称,我们会报告错误。出于我不完全清楚的原因,变量作用域似乎有很多这些皱纹。我从未见过一种语言,它感觉完全 优雅。
在我们结束本章之前,我们还有一个边缘情况要处理。回想一下这个奇怪的家伙,我们第一次在 jlox 的变量解析实现 中遇到它。
{
var a = "outer";
{
var a = a;
}
}
我们当时通过将变量的声明分成两个阶段来解决它,我们也会在这里这样做。
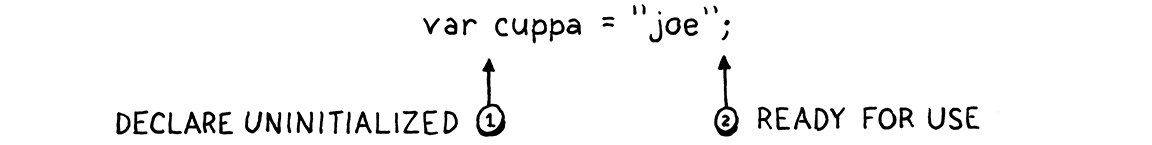
一旦变量声明开始 —换句话说,在它的初始化器之前 —该名称在当前作用域中声明。变量存在,但处于特殊的“未初始化”状态。然后我们编译初始化器。如果在该表达式中的任何点,我们解析指向该变量的标识符,我们会发现它尚未初始化,并报告错误。在我们完成编译初始化器后,我们将变量标记为已初始化,并准备使用。
为了实现这一点,当我们声明一个局部变量时,我们需要以某种方式指示“未初始化”状态。我们可以向 `Local` 添加一个新字段,但让我们在内存上节俭一些。相反,我们将变量的作用域深度设置为一个特殊的哨兵值,`-1`。
local->name = name;
在 addLocal() 中
替换 1 行
local->depth = -1;
}
稍后,一旦变量的初始化器编译完成,我们将它标记为已初始化。
if (current->scopeDepth > 0) {
在 defineVariable() 中
markInitialized();
return; }
实现如下
在 `parseVariable()` 后添加
static void markInitialized() { current->locals[current->localCount - 1].depth = current->scopeDepth; }
所以这实际上是在编译器中“声明”和“定义”变量的含义。“声明”是指将变量添加到作用域中,“定义”是指它变得可用。
当我们解析对局部变量的引用时,我们检查作用域深度以查看它是否已完全定义。
if (identifiersEqual(name, &local->name)) {
在 `resolveLocal()` 中
if (local->depth == -1) { error("Can't read local variable in its own initializer."); }
return i;
如果变量具有哨兵深度,那么它一定是对其自身初始化器的引用,我们将其报告为错误。
这就是本章的全部内容!我们添加了块、局部变量和真正的、诚实的词法作用域。鉴于我们为变量引入了完全不同的运行时表示,我们不必编写很多代码。实现最终变得非常干净和高效。
你会注意到,我们编写的几乎所有代码都在编译器中。在运行时,它只有两个小指令。你将在 clox 与 jlox 相比中看到这一点是一个持续的 趋势。优化器工具箱中最强大的工具之一是将工作提前拉到编译器中,这样你就不必在运行时进行。在本章中,这意味着解析每个局部变量占据的堆栈插槽。这样,在运行时,就不需要进行任何查找或解析。
挑战
-
我们的简单局部数组使我们能够轻松地计算每个局部变量的堆栈插槽。但这意味着当编译器解析对变量的引用时,我们必须对数组进行线性扫描。
想出一个更有效的方法。你认为额外的复杂性值得吗?
-
其他语言如何处理这样的代码
var a = a;
如果它是你的语言,你会怎么做?为什么?
-
许多语言区分可以重新分配的变量和不能重新分配的变量。在 Java 中,`final` 修饰符会阻止你对变量进行赋值。在 JavaScript 中,使用 `let` 声明的变量可以赋值,但使用 `const` 声明的变量则不能。Swift 将 `let` 视为单赋值,并使用 `var` 作为可赋值变量。Scala 和 Kotlin 使用 `val` 和 `var`。
选择一个关键字来添加一个单赋值变量形式到 Lox 中。证明你的选择,然后实现它。尝试对使用新关键字声明的变量进行赋值会导致编译错误。
-
扩展 clox 以允许一次有超过 256 个局部变量在作用域中。