全局变量
如果有一种发明可以像香味一样把记忆装进瓶子里,并且永远不会褪色,永远不会变质。然后,当人们想要回忆的时候,就可以打开瓶子,就像重新体验那个时刻一样。
达芙妮·杜·莫里埃,《蝴蝶梦》
在上一章中,我们深入探讨了一个大型、深奥、基础的计算机科学数据结构。理论和概念都很重要。可能还有一些关于大O符号和算法的讨论。本章的智力追求较少。没有太多需要学习的大概念。相反,它是一系列简单的工程任务。完成它们后,我们的虚拟机将支持变量。
实际上,它只支持全局变量。局部变量将在下一章中介绍。在jlox中,我们成功地将它们都塞进了一章,因为我们对所有变量使用了相同的实现技术。我们构建了一个环境链,每个作用域一个环境,一直到最上面。这是一种简单、干净的方式来学习如何管理状态。
但这也很慢。每次进入一个块或调用一个函数时都分配一个新的哈希表,这不是构建快速VM的最佳方式。考虑到有多少代码与使用变量有关,如果变量运行缓慢,那么所有内容都会运行缓慢。对于clox,我们将通过对局部变量使用更高效的策略来改进这一点,但全局变量不容易优化。
Lox语义的快速复习:Lox中的全局变量是“晚绑定”的,或者说动态解析的。这意味着可以编译引用全局变量的代码块,而无需事先定义。只要代码在定义发生之前不执行,一切都会正常。在实践中,这意味着可以在函数主体中引用后面的变量。
fun showVariable() { print global; } var global = "after"; showVariable();
像这样的代码看起来可能很奇怪,但它对于定义相互递归的函数很有用。它也能更好地与REPL配合。可以在一行中编写一个小函数,然后在下一行定义它使用的变量。
局部变量的工作方式不同。由于局部变量的声明总是在使用之前发生,因此即使在简单的单遍编译器中,VM也可以在编译时解析它们。这将使我们能够对局部变量使用更智能的表示。但那是下一章的内容。现在,让我们只关注全局变量。
21 . 1语句
变量通过变量声明而存在,这意味着现在也是为我们的编译器添加语句支持的时候了。如果你还记得,Lox将语句分为两类。“声明”是指将新名称绑定到值的那些语句。其他类型的语句—控制流、打印等—只被称为“语句”。我们不允许在控制流语句中直接声明,比如这样
if (monday) var croissant = "yes"; // Error.
允许这样做会引发关于变量作用域的令人困惑的问题。因此,像其他语言一样,我们通过为允许在控制流主体中使用的语句子集设置单独的语法规则来在语法上禁止它。
statement → exprStmt | forStmt | ifStmt | printStmt | returnStmt | whileStmt | block ;
然后我们使用单独的规则用于脚本的顶层以及块内部。
declaration → classDecl | funDecl | varDecl | statement ;
declaration规则包含声明名称的语句,也包含statement,以便允许所有语句类型。由于block本身位于statement中,因此可以通过将声明嵌套在块内,将声明置于控制流结构内部。
在本章中,我们将只介绍几个语句和一个声明。
statement → exprStmt | printStmt ; declaration → varDecl | statement ;
到目前为止,我们的VM将“程序”视为一个表达式,因为这是我们所能解析和编译的。在完整的Lox实现中,程序是声明的序列。我们现在已经准备好支持这一点。
advance();
在 compile() 中
替换 2 行
while (!match(TOKEN_EOF)) { declaration(); }
endCompiler();
我们继续编译声明,直到遇到源文件的末尾。我们使用以下方法编译单个声明
在 expression() 之后添加
static void declaration() { statement(); }
我们将在本章后面介绍变量声明,所以现在我们只是转发到statement()。
在 declaration() 之后添加
static void statement() { if (match(TOKEN_PRINT)) { printStatement(); } }
块可以包含声明,控制流语句可以包含其他语句。这意味着这两个函数最终将是递归的。我们现在就可以写出前向声明了。
static void expression();
在 expression() 之后添加
static void statement(); static void declaration();
static ParseRule* getRule(TokenType type);
21 . 1 . 1打印语句
本章中要支持两种语句类型。让我们从print语句开始,这些语句自然地以print标记开始。我们使用以下辅助函数检测它
在 consume() 之后添加
static bool match(TokenType type) { if (!check(type)) return false; advance(); return true; }
你可能从jlox中认出了它。如果当前标记的类型是给定的类型,我们会使用该标记并返回true。否则,我们会保留该标记并返回false。这个辅助函数是根据这个其他辅助函数实现的
在 consume() 之后添加
static bool check(TokenType type) { return parser.current.type == type; }
check()函数如果当前标记的类型是给定的类型,则返回true。用函数包装它似乎有点愚蠢,但我们以后会更多地使用它,我认为像这样的短动词命名函数会使解析器更容易阅读。
如果我们确实匹配了print标记,那么我们将在以下位置编译语句的其余部分
在 expression() 之后添加
static void printStatement() { expression(); consume(TOKEN_SEMICOLON, "Expect ';' after value."); emitByte(OP_PRINT); }
print语句会计算一个表达式并打印结果,因此我们首先解析并编译该表达式。语法要求在表达式后面使用分号,因此我们使用它。最后,我们发出一个新的指令来打印结果。
OP_NEGATE,
在 enum OpCode 中
OP_PRINT,
OP_RETURN,
在运行时,我们像这样执行这条指令
break;
在 run() 中
case OP_PRINT: { printValue(pop()); printf("\n"); break; }
case OP_RETURN: {
当解释器遇到这条指令时,它已经执行了表达式的代码,将结果值留在了堆栈的顶部。现在我们只需弹出并打印它。
请注意,我们之后没有推送任何其他内容。这是VM中表达式和语句之间的关键区别。每个字节码指令都具有一个堆栈效果,它描述了指令如何修改堆栈。例如,OP_ADD 弹出两个值并推送一个值,使堆栈比之前小一个元素。
可以将一系列指令的堆栈效果相加,得到它们的总效果。当将从任何完整表达式编译的一系列指令的堆栈效果相加时,总计将为 1。每个表达式都在堆栈上留一个结果值。
整个语句的字节码的总堆栈效果为零。由于语句不产生任何值,因此它最终不会改变堆栈,尽管它在执行操作时会使用堆栈。这一点很重要,因为当我们进入控制流和循环时,程序可能会执行一系列长的语句。如果每个语句都使堆栈增大或缩小,最终可能会导致堆栈溢出或下溢。
在我们进入解释器循环时,应该删除一些代码。
case OP_RETURN: {
在 run() 中
替换 2 行
// Exit interpreter.
return INTERPRET_OK;
当VM只编译和评估一个表达式时,我们在OP_RETURN中有一些临时的代码来输出值。现在我们有了语句和print,我们不再需要它了。我们离clox的完整实现又近了一步。
像往常一样,新指令需要反汇编器支持。
return simpleInstruction("OP_NEGATE", offset);
在 disassembleInstruction() 中
case OP_PRINT: return simpleInstruction("OP_PRINT", offset);
case OP_RETURN:
那就是我们的print语句。如果你想,可以试试
print 1 + 2; print 3 * 4;
激动人心的!好吧,也许不激动人心,但现在我们可以构建包含任意数量语句的脚本,这感觉就像是在进步。
21 . 1 . 2表达式语句
等你看到下一个语句的时候就知道了。如果我们没有看到print关键字,那么我们一定是看到了表达式语句。
printStatement();
在 statement() 中
} else { expressionStatement();
}
它是这样解析的
在 expression() 之后添加
static void expressionStatement() { expression(); consume(TOKEN_SEMICOLON, "Expect ';' after expression."); emitByte(OP_POP); }
“表达式语句”只是一个表达式后跟一个分号。它们是在需要语句的上下文中编写表达式的形式。通常,这样做是为了调用函数或计算赋值以获取其副作用,比如这样
brunch = "quiche"; eat(brunch);
从语义上讲,表达式语句会计算表达式并丢弃结果。编译器直接编码了这种行为。它编译表达式,然后发出OP_POP指令。
OP_FALSE,
在 enum OpCode 中
OP_POP,
OP_EQUAL,
顾名思义,这条指令会弹出堆栈顶部的值并将其丢弃。
case OP_FALSE: push(BOOL_VAL(false)); break;
在 run() 中
case OP_POP: pop(); break;
case OP_EQUAL: {
我们也可以反汇编它。
return simpleInstruction("OP_FALSE", offset);
在 disassembleInstruction() 中
case OP_POP: return simpleInstruction("OP_POP", offset);
case OP_EQUAL:
表达式语句现在还不太有用,因为我们无法创建任何具有副作用的表达式,但当我们在后面添加函数时,它们将必不可少。在像C这样的语言中,现实世界代码中的大多数语句都是表达式语句。
21 . 1 . 3错误同步
当我们在编译器中完成这些初始工作时,我们可以解决几章之前遗留的一个问题。与jlox一样,clox使用恐慌模式错误恢复来尽量减少它报告的级联编译错误数量。当编译器遇到同步点时,它会退出恐慌模式。对于Lox,我们选择了语句边界作为该点。现在我们有了语句,就可以实现同步了。
statement();
在 declaration() 中
if (parser.panicMode) synchronize();
}
如果我们在解析上一个语句时遇到编译错误,我们会进入恐慌模式。当这种情况发生时,在该语句之后,我们开始同步。
在 printStatement() 之后添加
static void synchronize() { parser.panicMode = false; while (parser.current.type != TOKEN_EOF) { if (parser.previous.type == TOKEN_SEMICOLON) return; switch (parser.current.type) { case TOKEN_CLASS: case TOKEN_FUN: case TOKEN_VAR: case TOKEN_FOR: case TOKEN_IF: case TOKEN_WHILE: case TOKEN_PRINT: case TOKEN_RETURN: return; default: ; // Do nothing. } advance(); } }
我们会无差别地跳过标记,直到遇到看起来像语句边界的东西。我们会通过查找前面可以结束语句的标记(比如分号)来识别边界。或者我们会查找后面开始语句的标记,通常是控制流或声明关键字之一。
21 . 2变量声明
仅仅能够打印并不能让你的语言在编程语言博览会上获得任何奖项,所以让我们继续做一些更有雄心壮志的事情,让变量开始运作。我们需要支持三种操作
- 使用
var语句声明新变量。 - 使用标识符表达式访问变量的值。
- 使用赋值表达式将新值存储在现有变量中。
在我们拥有某些变量之前,我们无法执行最后两项操作,因此我们从声明开始。
static void declaration() {
在 declaration() 中
替换 1 行
if (match(TOKEN_VAR)) { varDeclaration(); } else { statement(); }
if (parser.panicMode) synchronize();
我们为声明语法规则草拟的占位符解析函数现在有了实际的生成。如果我们匹配 var 标记,我们就跳转到这里
在 expression() 之后添加
static void varDeclaration() { uint8_t global = parseVariable("Expect variable name."); if (match(TOKEN_EQUAL)) { expression(); } else { emitByte(OP_NIL); } consume(TOKEN_SEMICOLON, "Expect ';' after variable declaration."); defineVariable(global); }
关键字后面是变量名。这是由 parseVariable() 编译的,我们将在下一秒讨论它。然后,我们查找 =,后面跟着初始化表达式。如果用户没有初始化变量,编译器会通过发出 OP_NIL 指令来隐式地将其初始化为nil。无论哪种方式,我们都希望语句以分号结尾。
这里有两个用于处理变量和标识符的新函数。这是第一个
static void parsePrecedence(Precedence precedence);
在parsePrecedence()之后添加
static uint8_t parseVariable(const char* errorMessage) { consume(TOKEN_IDENTIFIER, errorMessage); return identifierConstant(&parser.previous); }
它要求下一个标记为标识符,它会消耗该标记并将其发送到这里
static void parsePrecedence(Precedence precedence);
在parsePrecedence()之后添加
static uint8_t identifierConstant(Token* name) { return makeConstant(OBJ_VAL(copyString(name->start, name->length))); }
此函数获取给定的标记,并将它的词素作为字符串添加到块的常量表中。然后,它返回该常量在常量表中的索引。
全局变量在运行时按名称查找。这意味着 VM—字节码解释器循环—需要访问该名称。整个字符串太大,无法作为操作数塞入字节码流中。相反,我们将字符串存储在常量表中,然后指令通过其在表中的索引来引用该名称。
此函数将该索引一直返回给 varDeclaration(),后者随后将其传递给这里
在parseVariable()之后添加
static void defineVariable(uint8_t global) { emitBytes(OP_DEFINE_GLOBAL, global); }
此函数输出定义新变量并存储其初始值的字节码指令。变量名称在常量表中的索引是指令的操作数。在基于堆栈的 VM 中,我们通常在最后发出此指令。在运行时,我们首先执行变量初始化器的代码。这会将值留在堆栈上。然后,此指令获取该值,并将其存储起来以备后用。
在运行时,我们从这个新的指令开始
OP_POP,
在 enum OpCode 中
OP_DEFINE_GLOBAL,
OP_EQUAL,
感谢我们方便实用的哈希表,实现起来并不难。
case OP_POP: pop(); break;
在 run() 中
case OP_DEFINE_GLOBAL: { ObjString* name = READ_STRING(); tableSet(&vm.globals, name, peek(0)); pop(); break; }
case OP_EQUAL: {
我们从常量表中获取变量的名称。然后,我们获取堆栈顶部的值,并将其存储在哈希表中,以该名称作为键。
此代码不检查键是否已存在于表中。Lox 对全局变量非常宽松,允许你重新定义它们而不会报错。这在 REPL 会话中很有用,因此 VM 通过简单地在键碰巧已存在于哈希表中的情况下覆盖值来支持这一点。
还有另一个小助手宏
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
在 run() 中
#define READ_STRING() AS_STRING(READ_CONSTANT())
#define BINARY_OP(valueType, op) \
它从字节码块中读取一个字节的操作数。它将其视为块常量表的索引,并返回该索引处的字符串。它不检查值是否为字符串—它只是无差别地将其强制转换为字符串。这是安全的,因为编译器永远不会发出引用非字符串常量的指令。
因为我们关心词法卫生,所以我们还在解释函数的末尾取消定义此宏。
#undef READ_CONSTANT
在 run() 中
#undef READ_STRING
#undef BINARY_OP
我一直说“哈希表”,但实际上我们还没有。我们需要一个地方来存储这些全局变量。由于我们希望它们在 clox 运行期间一直存在,因此我们将它们直接存储在 VM 中。
Value* stackTop;
在 struct VM 中
Table globals;
Table strings;
与字符串表一样,我们需要在 VM 启动时将哈希表初始化为有效状态。
vm.objects = NULL;
在initVM()中
initTable(&vm.globals);
initTable(&vm.strings);
当我们退出时,我们会拆除它。
void freeVM() {
在freeVM()中
freeTable(&vm.globals);
freeTable(&vm.strings);
与往常一样,我们希望能够反汇编新的指令。
return simpleInstruction("OP_POP", offset);
在 disassembleInstruction() 中
case OP_DEFINE_GLOBAL: return constantInstruction("OP_DEFINE_GLOBAL", chunk, offset);
case OP_EQUAL:
有了它,我们就可以定义全局变量了。不是说用户可以告诉他们已经这么做了,因为他们实际上还不能使用它们。所以我们接下来要解决这个问题。
21 . 3读取变量
与所有编程语言一样,我们使用变量的名称来访问它的值。我们在表达式解析器中将标识符标记连接到这里
[TOKEN_LESS_EQUAL] = {NULL, binary, PREC_COMPARISON},
替换 1 行
[TOKEN_IDENTIFIER] = {variable, NULL, PREC_NONE},
[TOKEN_STRING] = {string, NULL, PREC_NONE},
这会调用这个新的解析器函数
在string()之后添加
static void variable() { namedVariable(parser.previous); }
与声明一样,这里还有几个微不足道的辅助函数,现在看起来很无用,但在后面的章节中会变得更有用。我保证。
在string()之后添加
static void namedVariable(Token name) { uint8_t arg = identifierConstant(&name); emitBytes(OP_GET_GLOBAL, arg); }
这会调用之前相同的 identifierConstant() 函数,将给定的标识符标记及其词素作为字符串添加到块的常量表中。剩下的就是发出一个指令,加载具有该名称的全局变量。这是指令
OP_POP,
在 enum OpCode 中
OP_GET_GLOBAL,
OP_DEFINE_GLOBAL,
在解释器中,实现反映了 OP_DEFINE_GLOBAL。
case OP_POP: pop(); break;
在 run() 中
case OP_GET_GLOBAL: { ObjString* name = READ_STRING(); Value value; if (!tableGet(&vm.globals, name, &value)) { runtimeError("Undefined variable '%s'.", name->chars); return INTERPRET_RUNTIME_ERROR; } push(value); break; }
case OP_DEFINE_GLOBAL: {
我们从指令的操作数中提取常量表索引,并获取变量名称。然后,我们将其用作键,在全局变量哈希表中查找变量的值。
如果键不存在于哈希表中,则意味着全局变量从未定义过。这在 Lox 中是一个运行时错误,因此如果发生这种情况,我们会报告它并退出解释器循环。否则,我们会获取该值并将其压入堆栈。
return simpleInstruction("OP_POP", offset);
在 disassembleInstruction() 中
case OP_GET_GLOBAL: return constantInstruction("OP_GET_GLOBAL", chunk, offset);
case OP_DEFINE_GLOBAL:
稍微反汇编一下,我们就完成了。我们的解释器现在能够运行像这样的代码
var beverage = "cafe au lait"; var breakfast = "beignets with " + beverage; print breakfast;
只剩下一个操作了。
21 . 4赋值
在整本书中,我一直试图让你走上一条相当安全和容易的路。我不是要回避困难的问题,而是尽量避免让解决方案比必要的复杂。唉,我们字节码编译器的其他设计选择使得赋值的实现变得令人厌烦。
我们的字节码 VM 使用单遍编译器。它在不进行任何中间 AST 的情况下动态地解析并生成字节码。一旦它识别出一部分语法,它就会为其发出代码。赋值并不自然地适合这种情况。考虑一下
menu.brunch(sunday).beverage = "mimosa";
在这段代码中,解析器直到遇到 = 才会意识到 menu.brunch(sunday).beverage 是赋值的目标,而不是普通的表达式,而这比第一个 menu 晚了好几个标记。到那时,编译器已经为整个过程发出了字节码。
不过,这个问题并没有看起来那么严重。看看解析器如何看待这个例子

即使 .beverage 部分不能编译为获取表达式,但 . 左侧的所有内容都是表达式,具有正常的表达式语义。menu.brunch(sunday) 部分可以照常编译和执行。
对我们来说幸运的是,赋值左侧唯一的语义差异出现在最右侧的标记末尾,紧挨着 =。即使设置器的接收者可能是任意长的表达式,但行为与获取表达式不同的部分只有尾随标识符,它位于 = 的前面。我们不需要太多的前瞻性就可以意识到 beverage 应该编译为设置表达式,而不是获取器。
变量更简单,因为它们只是 = 之前的单个裸标识符。因此,想法是在编译可以作为赋值目标使用的表达式之前,我们会查找后面的 = 标记。如果我们看到了它,我们会将其编译为赋值或设置器,而不是变量访问或获取器。
我们还没有设置器需要担心,所以我们只需要处理变量。
uint8_t arg = identifierConstant(&name);
在namedVariable()中
替换 1 行
if (match(TOKEN_EQUAL)) { expression(); emitBytes(OP_SET_GLOBAL, arg); } else { emitBytes(OP_GET_GLOBAL, arg); }
}
在标识符表达式的解析函数中,我们查找标识符后面的等号。如果我们找到了它,我们不会发出变量访问的代码,而是编译分配的值,然后发出赋值指令。
这是我们本章需要添加的最后一条指令。
OP_DEFINE_GLOBAL,
在 enum OpCode 中
OP_SET_GLOBAL,
OP_EQUAL,
正如你所料,它的运行时行为与定义新变量类似。
}
在 run() 中
case OP_SET_GLOBAL: { ObjString* name = READ_STRING(); if (tableSet(&vm.globals, name, peek(0))) { tableDelete(&vm.globals, name); runtimeError("Undefined variable '%s'.", name->chars); return INTERPRET_RUNTIME_ERROR; } break; }
case OP_EQUAL: {
主要区别在于键不存在于全局变量哈希表中的情况。如果变量尚未定义,则尝试向其赋值是一个运行时错误。Lox 不执行隐式变量声明.
另一个区别是,设置变量不会从堆栈中弹出该值。请记住,赋值是一个表达式,因此它需要将该值保留在那里,以防赋值嵌套在某个更大的表达式中。
添加一些反汇编
return constantInstruction("OP_DEFINE_GLOBAL", chunk,
offset);
在 disassembleInstruction() 中
case OP_SET_GLOBAL: return constantInstruction("OP_SET_GLOBAL", chunk, offset);
case OP_EQUAL:
所以我们完成了,对吧?好吧 . . . 还不完全是。我们犯了一个错误!请看一看
a * b = c + d;
根据 Lox 的语法,= 的优先级最低,因此它应该被解析为类似于
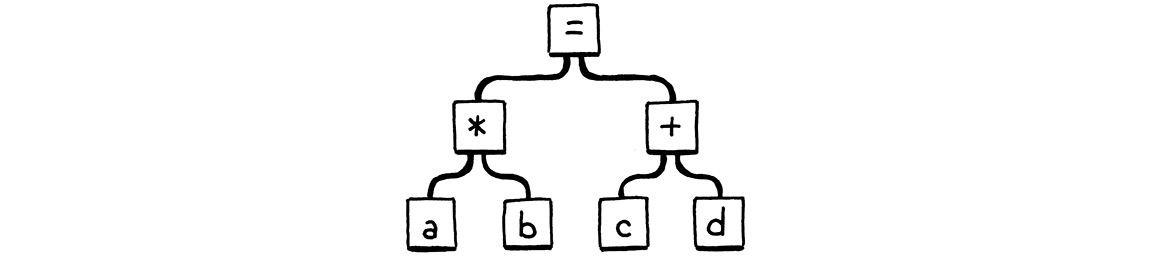
显然,a * b 不是一个有效的赋值目标,因此这应该是一个语法错误。但这是我们的解析器所做的
- 首先,
parsePrecedence()使用variable()前缀解析器解析a。 - 之后,它进入中缀解析循环。
- 它遇到
*并调用binary()。 - 这递归调用
parsePrecedence()来解析右操作数。 - 这再次调用
variable()来解析b。 - 在对
variable()的调用中,它会查找尾随的=。它看到一个,因此将该行的其余部分解析为赋值。
换句话说,解析器会像这样看到上面的代码:
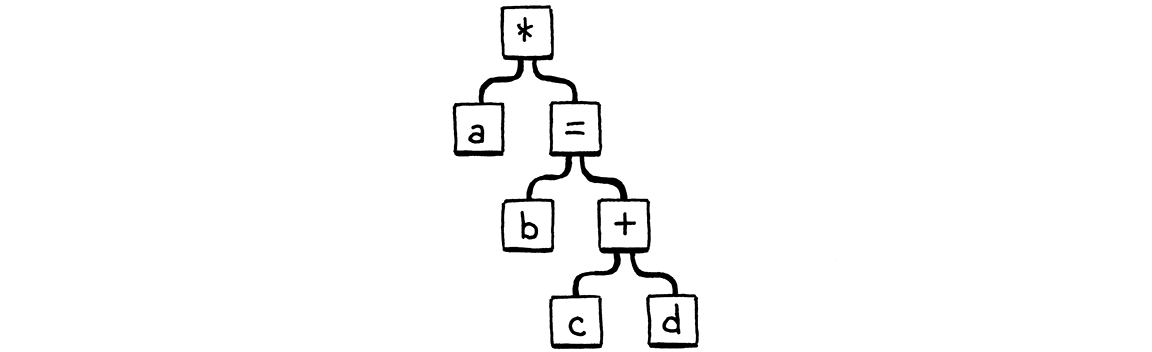
我们弄乱了优先级处理,因为 variable() 没有考虑包含变量的周围表达式的优先级。如果变量恰好是中缀运算符的右侧操作数,或者是一元运算符的操作数,那么包含它的表达式优先级太高,不允许 =。
为了解决这个问题,variable() 应该只在低优先级表达式的上下文中查找和使用 =。知道当前优先级的代码是 parsePrecedence(),这在逻辑上是合理的。variable() 函数不需要知道实际的级别。它只关心优先级是否足够低以允许赋值,所以我们将这个事实作为一个布尔值传递进去。
error("Expect expression.");
return;
}
在 parsePrecedence() 中
替换 1 行
bool canAssign = precedence <= PREC_ASSIGNMENT; prefixRule(canAssign);
while (precedence <= getRule(parser.current.type)->precedence) {
由于赋值是最低优先级的表达式,所以我们只允许在解析赋值表达式或顶级表达式(如表达式语句)时进行赋值。这个标志将传到这里,传递到解析器函数中
函数 variable()
替换 3 行
static void variable(bool canAssign) { namedVariable(parser.previous, canAssign); }
它通过一个新的参数传递过去
函数 namedVariable()
替换 1 行
static void namedVariable(Token name, bool canAssign) {
uint8_t arg = identifierConstant(&name);
然后最终在这里使用它
uint8_t arg = identifierConstant(&name);
在namedVariable()中
替换 1 行
if (canAssign && match(TOKEN_EQUAL)) {
expression();
这涉及很多管道工作,才能将一个比特的数据传递到编译器中正确的位置,但最终还是成功了。如果变量嵌套在优先级更高的表达式中,canAssign 将为 false,即使存在 =,它也会忽略它。然后 namedVariable() 返回,最终执行将回到 parsePrecedence()。
然后呢?编译器会如何处理我们之前损坏的例子?现在,variable() 不会使用 =,因此它将成为当前的标记。编译器从 variable() 前缀解析器返回到 parsePrecedence(),然后尝试进入中缀解析循环。没有与 = 关联的解析函数,所以它跳过了这个循环。
然后 parsePrecedence() 默默地返回到调用者。这也不对。如果 = 没有被解析为表达式的部分,那么就不会有其他东西会解析它。这是一个错误,我们应该报告它。
infixRule(); }
在 parsePrecedence() 中
if (canAssign && match(TOKEN_EQUAL)) { error("Invalid assignment target."); }
}
有了它,之前的错误程序会在编译时正确地报错。好了,我们现在结束了吗?还没有。你看,我们正在向一个解析函数传递参数。但是这些函数存储在一个函数指针表中,所以所有解析函数都需要具有相同的类型。即使大多数解析函数不支持用作赋值目标(设置器是唯一可以这样做的另一个函数),我们友好的 C 编译器要求它们都接受参数。
所以我们将用一些琐碎的工作来结束本章。首先,让我们将标志传递给中缀解析函数。
ParseFn infixRule = getRule(parser.previous.type)->infix;
在 parsePrecedence() 中
替换 1 行
infixRule(canAssign);
}
我们最终会需要它来做设置器。然后我们将修复函数类型的 typedef。
} Precedence;
在枚举 Precedence 之后添加
替换 1 行
typedef void (*ParseFn)(bool canAssign);
typedef struct {
以及一些完全乏味的代码,以便在所有现有的解析函数中接受这个参数。在这里
函数 binary()
替换 1 行
static void binary(bool canAssign) {
TokenType operatorType = parser.previous.type;
以及这里
函数 literal()
替换 1 行
static void literal(bool canAssign) {
switch (parser.previous.type) {
以及这里
函数 grouping()
替换 1 行
static void grouping(bool canAssign) {
expression();
以及这里
函数 number()
替换 1 行
static void number(bool canAssign) {
double value = strtod(parser.previous.start, NULL);
以及这里
函数 string()
替换 1 行
static void string(bool canAssign) {
emitConstant(OBJ_VAL(copyString(parser.previous.start + 1,
最后
函数 unary()
替换 1 行
static void unary(bool canAssign) {
TokenType operatorType = parser.previous.type;
呼!我们又回到了可以编译的 C 程序。启动它,现在你可以运行这个程序了
var breakfast = "beignets"; var beverage = "cafe au lait"; breakfast = "beignets with " + beverage; print breakfast;
它开始看起来像真正的代码,用于真实的语言了!
挑战
-
编译器每次遇到标识符时,都会将全局变量的名称作为字符串添加到常量表中。它每次都会创建一个新的常量,即使该变量名称之前已经存在于常量表中的某个槽位中。在同一个函数多次引用同一个变量的情况下,这是浪费的。反过来,这会增加填满常量表并耗尽槽位的可能性,因为我们只允许在单个块中使用 256 个常量。
优化它。与运行时相比,你的优化对编译器的性能有什么影响?这是正确的权衡吗?
-
每次使用全局变量时,都通过哈希表按名称查找它,即使使用好的哈希表,速度也很慢。你能想出一个更高效的方法来存储和访问全局变量,而不改变语义吗?
-
在 REPL 中运行时,用户可能会编写一个引用未知全局变量的函数。然后,在下一行,他们声明了这个变量。Lox 应该优雅地处理这个问题,在第一次定义函数时,不要报告 “未知变量” 编译错误。
但是,当用户运行 Lox 脚本时,编译器在任何代码运行之前都可以访问整个程序的完整文本。考虑这个程序
fun useVar() { print oops; } var ooops = "too many o's!";
在这里,我们可以静态地判断
oops不会被定义,因为程序中没有任何对该全局变量的声明。注意,useVar()也从来没有被调用,所以即使变量没有被定义,也不会发生运行时错误,因为它也没有被使用。我们可以在运行脚本时,至少将这种错误报告为编译错误。你认为我们应该这样做吗?证明你的答案。你所知道的其他脚本语言是如何做的?