超类
你可以选择你的朋友,但你不能选择你的家人,无论你是否承认他们,他们都是你的亲人,当你否认他们时,你会显得十分愚蠢。
哈珀·李,杀死一只知更鸟
这是我们向 VM 添加新功能的最后一章。我们已经将几乎整个 Lox 语言都塞了进去。剩下的只有继承方法和调用超类方法。我们在这之后还有另一章,但它没有引入新的行为。它只让现有功能更快。完成本章内容,你将拥有一个完整的 Lox 实现。
本章中的一些内容会让你想起 jlox。我们解析超级调用的方式基本相同,尽管它是通过 clox 更复杂的机制在栈上存储状态来实现的。但这一次,我们有了一个完全不同的、快得多的方法来处理继承方法调用。
29 . 1继承方法
我们将从方法继承开始,因为它比较简单。为了提醒你,Lox 继承语法如下所示
class Doughnut { cook() { print "Dunk in the fryer."; } } class Cruller < Doughnut { finish() { print "Glaze with icing."; } }
这里,Cruller 类继承自 Doughnut,因此,Cruller 的实例继承了 cook() 方法。我不知道为什么要强调这一点。你知道继承是如何工作的。让我们开始编译新的语法。
currentClass = &classCompiler;
在 classDeclaration() 中
if (match(TOKEN_LESS)) { consume(TOKEN_IDENTIFIER, "Expect superclass name."); variable(false); namedVariable(className, false); emitByte(OP_INHERIT); }
namedVariable(className, false);
在编译类名之后,如果下一个标记是 <,那么我们就找到了超类子句。我们消耗超类的标识符标记,然后调用 variable()。该函数接收先前消耗的标记,将其视为变量引用,并发出代码以加载变量的值。换句话说,它按名称查找超类并将其压入栈中。
之后,我们调用 namedVariable() 将进行继承的子类压入栈,然后调用 OP_INHERIT 指令。该指令将超类连接到新的子类。在上一章中,我们定义了一个 OP_METHOD 指令,用于通过将方法添加到其方法表来改变现有的类对象。这很相似—OP_INHERIT 指令接收一个现有的类,并对其应用继承的效果。
在前面的示例中,当编译器处理这段语法时
class Cruller < Doughnut {
结果是以下字节码
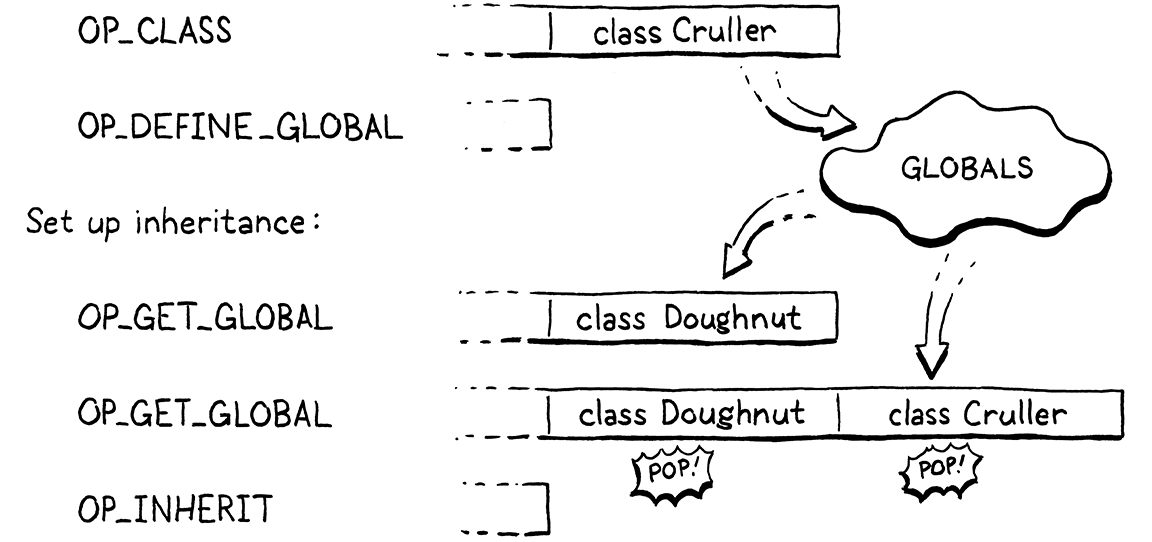
在我们实现新的 OP_INHERIT 指令之前,我们需要检测一个边缘情况。
variable(false);
在 classDeclaration() 中
if (identifiersEqual(&className, &parser.previous)) {
error("A class can't inherit from itself.");
}
namedVariable(className, false);
一个 类不能是它自己的超类。除非你能够接触到一个疯狂的核物理学家和一台经过大幅改造的 DeLorean,否则你无法从自身继承。
29 . 1 . 1执行继承
现在开始新的指令。
OP_CLASS,
在枚举 OpCode 中
OP_INHERIT,
OP_METHOD
没有操作数需要担心。我们需要的值—超类和子类—都在栈上。这意味着反汇编很简单。
return constantInstruction("OP_CLASS", chunk, offset);
在 disassembleInstruction() 中
case OP_INHERIT: return simpleInstruction("OP_INHERIT", offset);
case OP_METHOD:
解释器是行动发生的地方。
break;
在 run() 中
case OP_INHERIT: { Value superclass = peek(1); ObjClass* subclass = AS_CLASS(peek(0)); tableAddAll(&AS_CLASS(superclass)->methods, &subclass->methods); pop(); // Subclass. break; }
case OP_METHOD:
从栈顶到栈底,我们依次有子类和超类。我们获取这两个类,然后执行继承操作。这是 clox 与 jlox 不同之处。在我们第一个解释器中,每个子类都存储着对其超类的引用。在访问方法时,如果我们在子类的方法表中没有找到该方法,我们将递归遍历继承链,查看每个祖先的方法表,直到找到它。
例如,对 Cruller 实例调用 cook() 会让 jlox 经历以下旅程
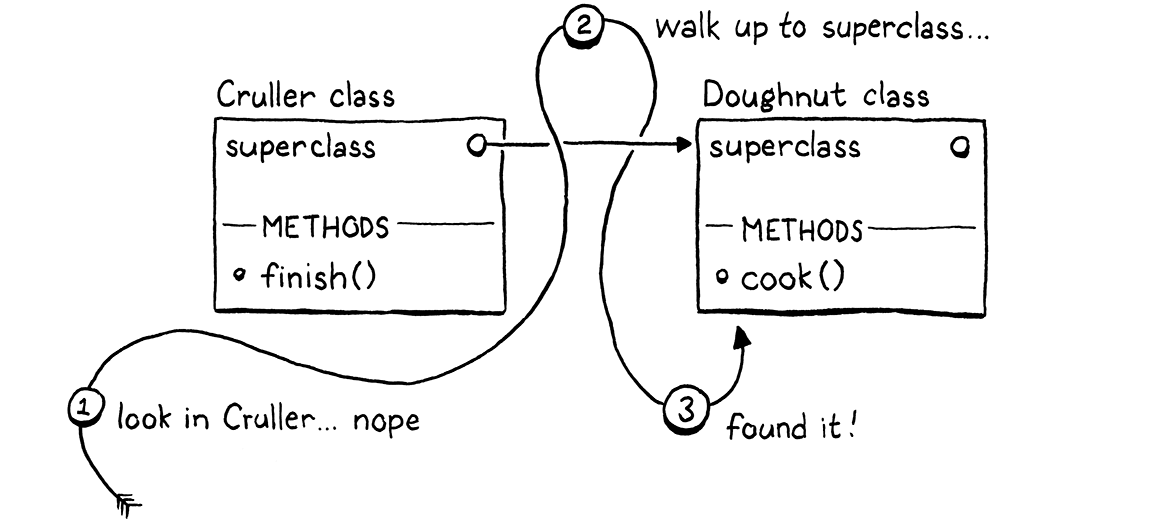
在方法调用期间执行这么多工作非常缓慢,更糟糕的是,继承的方法在祖先链中越远,它就会越慢。这不是一个很好的性能故事。
新方法快得多。当子类被声明时,我们将所有继承类的所有方法都复制到子类自己的方法表中。之后,当调用方法时,任何从超类继承的方法都将在子类自己的方法表中找到。根本不需要任何额外的运行时工作来进行继承。在类声明完成时,工作就完成了。这意味着继承方法调用与普通方法调用一样快—只需进行一次哈希表查找。
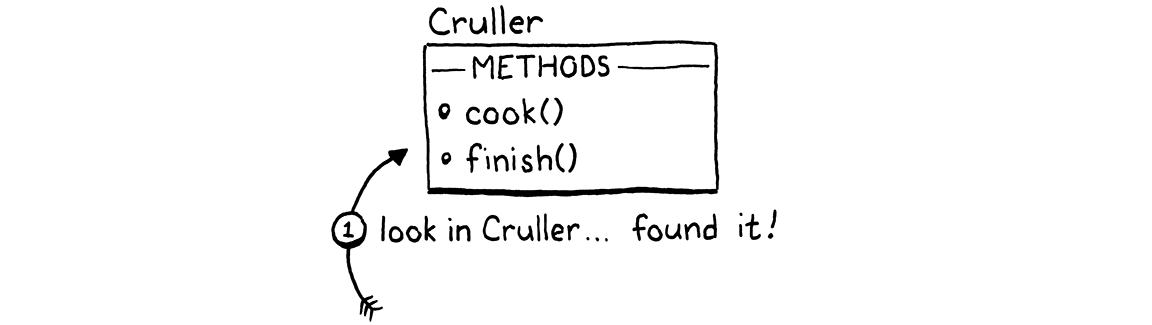
我有时听到这种技术被称为“复制向下继承”。它简单快捷,但就像大多数优化一样,你只能在某些约束下使用它。它在 Lox 中有效是因为 Lox 类是封闭的。一旦类声明执行完毕,该类的所有方法都无法改变。
在 Ruby、Python 和 JavaScript 等语言中,可以打开一个现有的类,并将一些新方法插入其中,甚至删除它们。这会破坏我们的优化,因为如果这些修改发生在子类声明执行之后的超类上,子类将不会获取这些更改。这违背了用户的期望,即继承始终反映超类的当前状态。
幸运的是对我们来说(但对喜欢这个功能的用户来说可能不幸运),Lox 不允许你修补猴子或穿孔鸭子,因此我们可以安全地应用这种优化。
方法重写怎么办?将超类的方法复制到子类的方法表中不会与子类自己的方法冲突吗?幸运的是,不会。我们在创建子类后但在编译任何方法声明和 OP_METHOD 指令之前发出 OP_INHERIT 指令。在我们复制超类的方法时,子类的方法表是空的。子类重写的任何方法都将覆盖表中的那些继承条目。
29 . 1 . 2无效超类
我们的实现简单快捷,这正是我喜欢我的 VM 代码的方式。但它不健壮。没有任何东西可以阻止用户从根本上不是类的对象继承
var NotClass = "So not a class"; class OhNo < NotClass {}
显然,没有任何一个自尊的程序员会这样写,但我们必须防止那些没有自尊的潜在 Lox 用户。一个简单的运行时检查就可以解决这个问题。
Value superclass = peek(1);
在 run() 中
if (!IS_CLASS(superclass)) { runtimeError("Superclass must be a class."); return INTERPRET_RUNTIME_ERROR; }
ObjClass* subclass = AS_CLASS(peek(0));
如果我们从超类子句中的标识符加载的值不是 ObjClass,我们会报告一个运行时错误,让用户知道我们对他们及其代码的看法。
29 . 2存储超类
你有没有注意到,当我们添加方法继承时,实际上并没有添加任何从子类到其超类的引用?在将继承方法复制完毕后,我们完全忘记了超类。我们不需要保留超类的句柄,所以我们也不保留。
这对于支持超级调用来说是不够的。由于子类可能会覆盖超类方法,因此我们需要能够访问超类方法表。在我们了解到这种机制之前,我想提醒你一下超级调用是如何进行静态解析的。
回到 jlox 的美好时光,我向你展示了这个棘手的示例来解释超级调用是如何分派的
class A { method() { print "A method"; } } class B < A { method() { print "B method"; } test() { super.method(); } } class C < B {} C().test();
在 test() 方法的内部,this 是 C 的实例。如果超级调用是相对于接收器的超类进行解析的,那么我们将在 C 的超类 B 中查找。但超级调用是相对于包含超级调用发生的类的超类进行解析的。在本例中,我们位于 B 的 test() 方法中,因此超类是 A,程序应该打印“A 方法”。
这意味着超级调用不是根据运行时实例动态解析的。用于查找方法的超类是调用发生的静态—实际上是词法—属性。当我们向 jlox 添加继承时,我们利用了这个静态方面,通过将超类存储在与所有词法作用域相同的 Environment 结构中。就像解释器看到上面的程序是这个样子
class A { method() { print "A method"; } } var Bs_super = A; class B < A { method() { print "B method"; } test() { runtimeSuperCall(Bs_super, "method"); } } var Cs_super = B; class C < B {} C().test();
每个子类都有一个隐藏变量,存储着对其超类的引用。每当我们需要执行超级调用时,我们都会从该变量中访问超类,并告诉运行时从那里开始查找方法。
我们将沿着相同的道路走下去。不同之处在于,我们没有 jlox 的堆分配的 Environment 类,而是有字节码 VM 的值栈和上值系统。机器有所不同,但总体效果相同。
29 . 2 . 1一个超类局部变量
我们的编译器已经发出代码来将超类压入栈。我们不是将该槽位留作临时存储,而是创建一个新的作用域,并将其设置为一个局部变量。
}
在 classDeclaration() 中
beginScope(); addLocal(syntheticToken("super")); defineVariable(0);
namedVariable(className, false);
emitByte(OP_INHERIT);
创建一个新的词法作用域可以确保,如果我们在同一个作用域中声明两个类,则每个类都有一个不同的局部槽位来存储其超类。由于我们始终将该变量命名为“super”,如果我们没有为每个子类创建作用域,这些变量就会发生冲突。
我们将该变量命名为“super”,原因与我们使用“this”作为隐藏局部变量的名称(this 表达式解析为该名称)相同:“super”是一个保留字,可以保证编译器的隐藏变量不会与用户定义的变量发生冲突。
不同之处在于,在编译 this 表达式时,我们恰好有一个标记,其词素为“this”。在这里我们没有那么幸运。相反,我们添加了一个小的辅助函数,用于为给定的常量字符串创建合成标记。
添加到 variable() 之后
static Token syntheticToken(const char* text) { Token token; token.start = text; token.length = (int)strlen(text); return token; }
由于我们为超类变量打开了局部作用域,因此我们需要关闭它。
emitByte(OP_POP);
在 classDeclaration() 中
if (classCompiler.hasSuperclass) { endScope(); }
currentClass = currentClass->enclosing;
在编译类体及其方法后,我们会弹出作用域并丢弃“super”变量。这样,该变量就在子类的所有方法中都可访问。这是一种有点无用的优化,但我们只有在存在超类子句的情况下才会创建作用域。因此,我们只需要在存在超类子句的情况下才关闭作用域。
为了跟踪这一点,我们可以在classDeclaration()中声明一个小的局部变量。但很快,编译器中的其他函数将需要知道周围的类是否是子类。所以我们不妨帮助未来的自己,现在将这个事实存储为ClassCompiler中的一个字段。
typedef struct ClassCompiler {
struct ClassCompiler* enclosing;
在结构体ClassCompiler中
bool hasSuperclass;
} ClassCompiler;
当我们第一次初始化ClassCompiler时,我们假设它不是子类。
ClassCompiler classCompiler;
在 classDeclaration() 中
classCompiler.hasSuperclass = false;
classCompiler.enclosing = currentClass;
然后,如果我们看到一个超类子句,我们就知道了我们正在编译一个子类。
emitByte(OP_INHERIT);
在 classDeclaration() 中
classCompiler.hasSuperclass = true;
}
这种机制为我们在运行时提供了一种机制,可以从子类的任何方法中访问周围子类的超类对象—只需发出代码来加载名为“super”的变量。该变量是在方法体之外的局部变量,但我们现有的上值支持使VM能够在方法体内或甚至在该方法内部嵌套的函数中捕获该局部变量。
29 . 3超类调用
有了运行时支持,我们就可以实现超类调用。和往常一样,我们从前往后,从新的语法开始。一个超类调用以,自然地,super关键字开头。
[TOKEN_RETURN] = {NULL, NULL, PREC_NONE},
替换1行
[TOKEN_SUPER] = {super_, NULL, PREC_NONE},
[TOKEN_THIS] = {this_, NULL, PREC_NONE},
当表达式解析器落在一个super令牌上时,控制跳转到一个新的解析函数,该函数从以下开始
在syntheticToken()之后添加
static void super_(bool canAssign) { consume(TOKEN_DOT, "Expect '.' after 'super'."); consume(TOKEN_IDENTIFIER, "Expect superclass method name."); uint8_t name = identifierConstant(&parser.previous); }
这与我们编译this表达式的方式大不相同。与this不同,super令牌不是一个独立的表达式。相反,它后面的点和方法名称是语法中不可分割的部分。然而,括号中的参数列表是分开的。与正常的访问方法一样,Lox 支持获取对超类方法的引用作为闭包,而不执行它
class A { method() { print "A"; } } class B < A { method() { var closure = super.method; closure(); // Prints "A". } }
换句话说,Lox 并没有真正的超类调用表达式,它有超类访问表达式,你可以选择立即调用它,如果你想要。所以当编译器遇到一个super令牌时,我们会消耗随后的.令牌,然后查找方法名称。方法是动态查找的,所以我们使用identifierConstant()获取方法名称令牌的词素,并将其存储在常量表中,就像我们对属性访问表达式所做的那样。
以下是编译器在消耗这些令牌后的行为
uint8_t name = identifierConstant(&parser.previous);
在super_()中
namedVariable(syntheticToken("this"), false); namedVariable(syntheticToken("super"), false); emitBytes(OP_GET_SUPER, name);
}
为了访问当前实例上的超类方法,运行时需要接收者和周围方法的类的超类。第一个namedVariable()调用生成代码来查找存储在隐藏变量“this”中的当前接收者,并将其压入堆栈。第二个namedVariable()调用发出代码来从其“super”变量中查找超类,并将该超类压入堆栈顶部。
最后,我们发出一个新的OP_GET_SUPER指令,该指令使用操作数来表示常量表中方法名称的索引。这很难记住。为了使它变得具体,请考虑这个示例程序
class Doughnut { cook() { print "Dunk in the fryer."; this.finish("sprinkles"); } finish(ingredient) { print "Finish with " + ingredient; } } class Cruller < Doughnut { finish(ingredient) { // No sprinkles, always icing. super.finish("icing"); } }
super.finish("icing")表达式的字节码如下所示,其工作方式如下
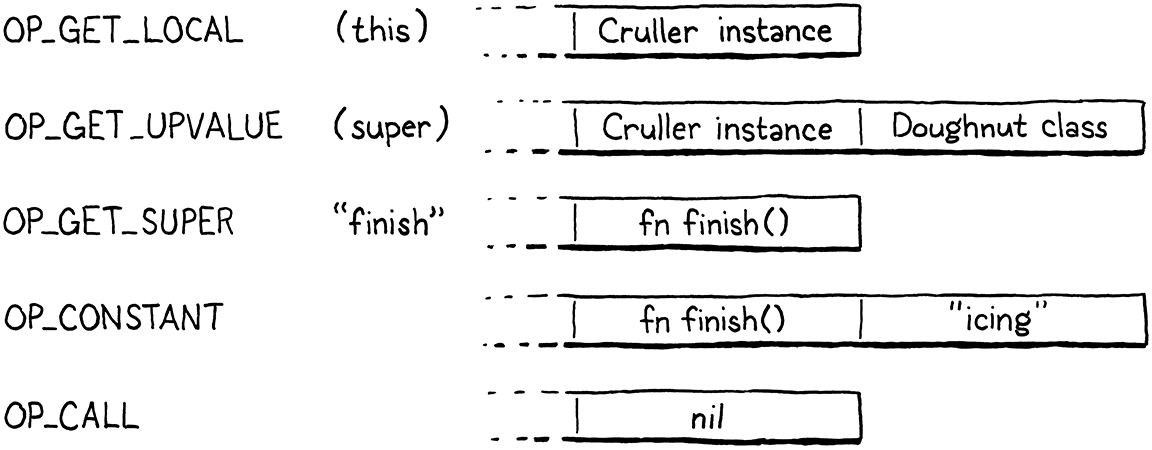
前三条指令使运行时能够访问执行超类访问所需的三个信息片段
-
第一条指令将实例加载到堆栈上。
-
第二条指令加载解析方法所在的超类。
-
然后,新的
OP_GET_SUPER指令将要访问的方法的名称编码为操作数。
其余的指令是用于评估参数列表和调用函数的正常字节码。
我们几乎准备好实现解释器中的新OP_GET_SUPER指令。但在此之前,编译器需要负责报告一些错误。
static void super_(bool canAssign) {
在super_()中
if (currentClass == NULL) { error("Can't use 'super' outside of a class."); } else if (!currentClass->hasSuperclass) { error("Can't use 'super' in a class with no superclass."); }
consume(TOKEN_DOT, "Expect '.' after 'super'.");
超类调用只有在方法体内部(或在方法内部嵌套的函数内部),并且只有在具有超类的类的的方法内部才有意义。我们使用currentClass的值检测这两种情况。如果它是NULL或指向没有超类的类,我们会报告这些错误。
29 . 3 . 1执行超类访问
假设用户没有在不允许的地方放置super表达式,他们的代码将从编译器传递到运行时。我们得到了一条新指令。
OP_SET_PROPERTY,
在枚举 OpCode 中
OP_GET_SUPER,
OP_EQUAL,
我们像其他采用常量表索引操作数的 opcode 一样对其进行反汇编。
return constantInstruction("OP_SET_PROPERTY", chunk, offset);
在 disassembleInstruction() 中
case OP_GET_SUPER: return constantInstruction("OP_GET_SUPER", chunk, offset);
case OP_EQUAL:
你可能会预料到更难的事情,但解释新的指令类似于执行正常的属性访问。
}
在 run() 中
case OP_GET_SUPER: { ObjString* name = READ_STRING(); ObjClass* superclass = AS_CLASS(pop()); if (!bindMethod(superclass, name)) { return INTERPRET_RUNTIME_ERROR; } break; }
case OP_EQUAL: {
与属性一样,我们从常量表中读取方法名称。然后我们将它传递给bindMethod(),它在给定类的“方法表”中查找方法,并创建一个ObjBoundMethod来将生成的闭包绑定到当前实例。
关键区别在于我们传递给bindMethod()的哪个类。对于正常的属性访问,我们使用ObjInstances自己的类,这给了我们想要的动态分派。对于超类调用,我们不使用实例的类。相反,我们使用包含类的静态解析的超类,编译器已经方便地确保它位于堆栈的顶部,等待着我们。
我们弹出该超类并将其传递给bindMethod(),它会正确地跳过该超类和实例自身类之间的任何子类中的任何覆盖方法。它还正确地包含了超类从其任何超类继承的任何方法。
其余的行为相同。弹出超类后,实例将位于堆栈的顶部。当bindMethod()成功时,它会弹出实例并压入新的绑定方法。否则,它会报告运行时错误并返回false。在这种情况下,我们会中止解释器。
29 . 3 . 2更快的超类调用
我们现在拥有了超类方法访问。而且,由于返回的对象是一个ObjBoundMethod,你可以随后调用它,所以我们也获得了超类调用。就像上一章一样,我们已经达到了 VM 具有完整、正确语义的点。
但是,就像上一章一样,它也很慢。同样,我们为每个超类调用都分配了一个ObjBoundMethod,即使大多数时候下一条指令是一个OP_CALL,它会立即解包该绑定方法、调用它,然后丢弃它。事实上,对于超类调用来说,这更有可能是真的,而不是对于普通的调用方法。至少对于调用方法,用户有可能实际上是在调用存储在字段中的函数。对于超类调用,你总是在查找方法。唯一的问题是你是否立即调用它。
编译器当然可以自己回答这个问题,如果它在超类方法名称后面看到一个左括号,所以我们继续执行与调用方法相同的优化。删除加载超类并发出OP_GET_SUPER的两行代码,并用以下代码替换它们
namedVariable(syntheticToken("this"), false);
在super_()中
替换2行
if (match(TOKEN_LEFT_PAREN)) { uint8_t argCount = argumentList(); namedVariable(syntheticToken("super"), false); emitBytes(OP_SUPER_INVOKE, name); emitByte(argCount); } else { namedVariable(syntheticToken("super"), false); emitBytes(OP_GET_SUPER, name); }
}
现在在我们发出任何内容之前,我们查找带括号的参数列表。如果我们找到它,我们编译它。然后我们加载超类。在那之后,我们发出一个新的OP_SUPER_INVOKE指令。这个超指令结合了OP_GET_SUPER和OP_CALL的行为,所以它有两个操作数:要查找的方法名称的常量表索引以及要传递给它的参数数量。
否则,如果我们没有找到(,我们会继续像以前一样编译表达式作为超类访问,并发出一个OP_GET_SUPER。
沿着编译管道漂移,我们的第一站是一条新指令。
OP_INVOKE,
在枚举 OpCode 中
OP_SUPER_INVOKE,
OP_CLOSURE,
就在它旁边,是它的反汇编支持。
return invokeInstruction("OP_INVOKE", chunk, offset);
在 disassembleInstruction() 中
case OP_SUPER_INVOKE: return invokeInstruction("OP_SUPER_INVOKE", chunk, offset);
case OP_CLOSURE: {
超类调用指令与OP_INVOKE具有相同的操作数集,因此我们重复使用相同的辅助函数对其进行反汇编。最后,管道将我们转储到解释器中。
break;
}
在 run() 中
case OP_SUPER_INVOKE: { ObjString* method = READ_STRING(); int argCount = READ_BYTE(); ObjClass* superclass = AS_CLASS(pop()); if (!invokeFromClass(superclass, method, argCount)) { return INTERPRET_RUNTIME_ERROR; } frame = &vm.frames[vm.frameCount - 1]; break; }
case OP_CLOSURE: {
这少量的代码基本上是我们的OP_INVOKE实现与OP_GET_SUPER的一点混合。在堆栈的组织方式上有一些差异。对于未优化的超类调用,超类在执行调用参数之前被弹出并替换为解析的函数的ObjBoundMethod。这确保了当OP_CALL被执行时,绑定方法位于参数列表下方,这是运行时为闭包调用所期望的位置。
使用我们优化的指令,事情发生了一些变化
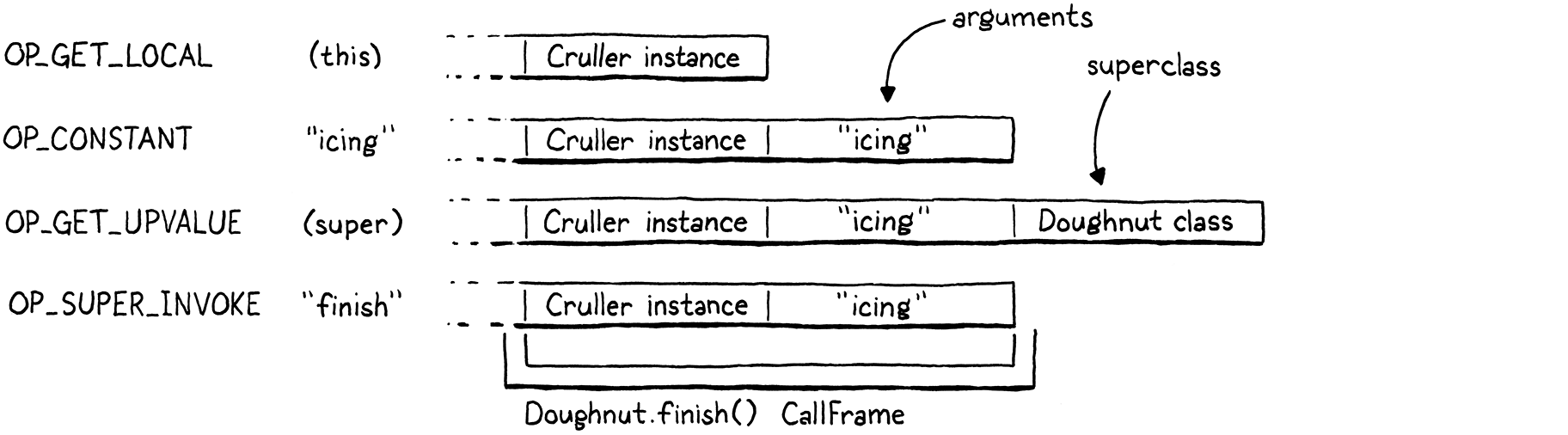
现在,解析超类方法是调用的一部分,因此在查找方法时,参数需要已经位于堆栈上。这意味着超类对象位于参数的顶部。
除此之外,行为与OP_GET_SUPER后跟OP_CALL大致相同。首先,我们提取方法名称和参数计数操作数。然后我们从堆栈的顶部弹出超类,以便我们可以在其方法表中查找方法。这巧合地使堆栈正确地设置好了方法调用。
我们将超类、方法名称和参数计数传递给现有的invokeFromClass()函数。该函数在给定类上查找给定的方法,并尝试使用给定的元数对其进行调用。如果找不到方法,它将返回false,我们会退出解释器。否则,invokeFromClass()会将一个新的CallFrame压入调用堆栈,用于方法的闭包。这会使解释器的缓存的CallFrame指针失效,所以我们刷新frame。
29 . 4完整的虚拟机
回顾一下我们所创造的东西。据我统计,我们编写了大约 2,500 行相当干净、直接的 C 代码。这个小程序包含了—相当高级的!—Lox 语言的完整实现,它包含一个完整的运算符优先级表,用于表示表达式类型,以及一系列控制流语句。我们实现了变量、函数、闭包、类、字段、方法和继承。
更令人印象深刻的是,我们的实现可移植到任何具有 C 编译器的平台,并且速度足够快,可以用于现实世界的生产环境。我们有一个单遍字节码编译器、一个用于我们内部指令集的紧凑的虚拟机解释器、紧凑的对象表示、用于在不进行堆分配的情况下存储变量的堆栈以及一个精确的垃圾收集器。
如果你出去看看 Lua、Python 或 Ruby 的实现,你会惊讶地发现其中有多少看起来很熟悉。你已经大大提高了你对编程语言工作原理的了解,这反过来让你更深入地理解编程本身。就像你过去是一名赛车手,现在你也可以打开引擎盖修理发动机了。
如果你愿意,可以在这里停下来。你拥有的两个 Lox 实现已经完整且功能齐全。你已经造好了这辆车,现在可以开着它去任何地方了。但是,如果你想要更多乐趣,对它进行微调和调整以获得更强大的性能,那么还有一章内容。我们不会添加任何新功能,但我们会引入一些经典的优化,以榨取更多性能。如果听起来很有趣,继续阅读 . . .
挑战
-
面向对象编程的一条准则是,一个类应该确保新对象处于有效状态。在 Lox 中,这意味着定义一个初始化器来填充实例的字段。继承会使不变式变得复杂,因为实例必须根据对象继承链中的所有类处于有效状态。
容易的部分是记住在每个子类的
init()方法中调用super.init()。困难的部分是字段。没有什么可以阻止继承链中的两个类意外地声明相同的字段名。当这种情况发生时,它们会踩踏彼此的字段,并可能导致实例处于损坏状态。如果 Lox 是你的语言,你会如何解决这个问题,如果有的话?如果你会改变语言,请实现你的更改。
-
我们的复制继承优化之所以有效,仅仅是因为 Lox 不允许你在声明类之后修改它的方法。这意味着我们不必担心子类中的复制方法与对超类的后续更改不同步。
其他语言,比如 Ruby,允许在事后修改类。这些语言的实现如何在保持方法解析效率的同时支持类修改?
-
在关于继承的 jlox 章节中,我们有一个挑战来实现 BETA 语言对方法覆盖的处理方式。再次解决这个挑战,但这次在 clox 中。以下是先前挑战的描述
在 Lox 中,就像大多数其他面向对象语言一样,在查找方法时,我们从类层次结构的底部开始,向上工作—子类的优先级高于超类的。为了从重写方法中获得超类方法,你使用
super。语言 BETA 采取了 相反的方法。当你调用一个方法时,它从类层次结构的顶部开始,向下工作。超类方法优先于子类方法。为了获得子类方法,超类方法可以调用
inner,这有点像super的反向操作。它链接到继承链中下一个方法。超类方法控制何时以及何地子类被允许细化其行为。如果超类方法根本不调用
inner,那么子类将无法覆盖或修改超类的行为。删除 Lox 当前的覆盖和
super行为,并用 BETA 的语义替换它。简而言之-
在类上调用方法时,类继承链中最高的方法优先。
-
在方法体内部,对
inner的调用会在包含inner的类和this的类之间的继承链中寻找最近的子类中具有相同名称的方法。如果没有匹配的方法,inner调用将不执行任何操作。
例如
class Doughnut { cook() { print "Fry until golden brown."; inner(); print "Place in a nice box."; } } class BostonCream < Doughnut { cook() { print "Pipe full of custard and coat with chocolate."; } } BostonCream().cook();
这将打印
Fry until golden brown. Pipe full of custard and coat with chocolate. Place in a nice box.
由于 clox 不仅是实现 Lox,而且是以良好的性能来实现,因此这次尝试着眼于效率来解决挑战。
-