解析与绑定
有时你会发现自己处于一种奇怪的境地。你一步步地陷入其中,以最自然的方式,但当你身处其中时,你会突然感到惊讶,并问自己这一切究竟是如何发生的。
索尔·海尔达尔,《Kon-Tiki》
哦,不!我们的语言实现正在进水!早在我们添加变量和代码块的时候,我们就将作用域定义得很好。但是,当我们后来添加闭包时,我们以前防水的解释器出现了一个漏洞。大多数实际程序不太可能通过这个漏洞,但作为语言实现者,我们发誓要关心即使是在语义中最深、最潮湿的角落的正确性。
我们将用这整章的时间来探索这个漏洞,然后仔细地修补它。在这个过程中,我们将更深入地了解 Lox 和 C 语言传统中其他语言使用的词法作用域。我们还将有机会学习语义分析—一种从用户源代码中提取含义的强大技术,而无需运行它。
11 . 1静态作用域
快速回顾一下:Lox 与大多数现代语言一样,使用词法作用域。这意味着,你只需阅读程序文本即可弄清楚变量名称引用的是哪个声明。例如
var a = "outer"; { var a = "inner"; print a; }
在这里,我们知道被打印的a是前一行声明的变量,而不是全局变量。运行程序不会—不能—影响这一点。作用域规则是语言静态语义的一部分,这就是为什么它们也被称为静态作用域。
我还没有详细说明这些作用域规则,但现在是时候精确了
一个变量使用引用了在封闭表达式中包含该变量使用的代码段中具有相同名称的前面声明。
这句话有很多东西需要解释
-
我用“变量使用”代替“变量表达式”,以涵盖变量表达式和赋值。同样,用“变量使用的表达式”代替“包含该变量使用的代码段”。
-
“前面”指的是在程序文本中出现之前。
var a = "outer"; { print a; var a = "inner"; }
在这里,被打印的
a是外部的,因为它在使用它的print语句之前出现。在大多数情况下,在直线代码中,文本中的前面声明也将在时间上早于使用。但并非总是如此。正如我们所看到的,函数可能会推迟一段代码,以便它的动态时间执行不再反映静态文本顺序。 -
“最内层”是由于我们亲爱的遮蔽现象。可能在封闭作用域中存在多个具有给定名称的变量,例如
var a = "outer"; { var a = "inner"; print a; }
我们的规则通过说最内层作用域获胜来消除这种歧义。
由于这条规则没有提到任何运行时行为,这意味着变量表达式始终引用程序整个执行过程中相同的声明。到目前为止,我们的解释器几乎完全正确地实现了这条规则。但是,当我们添加闭包时,一个错误潜入了进来。
var a = "global"; { fun showA() { print a; } showA(); var a = "block"; showA(); }
在你输入并运行这段代码之前,请决定你认为它应该打印什么。
好吧 . . . 明白了?如果你熟悉其他语言中的闭包,你会期望它打印两次“global”。第一次调用showA()肯定应该打印“global”,因为我们还没有到达内部a的声明。根据我们的规则,变量表达式始终解析为相同的变量,这意味着第二次调用showA()应该打印相同的内容。
唉,它打印了
global block
我要强调的是,这个程序从未重新赋值任何变量,并且只包含一个print语句。然而,不知何故,该print语句用于一个从未赋值的变量,在不同的时间点打印了两个不同的值。我们肯定在某处破坏了一些东西。
11 . 1 . 1作用域和可变环境
在我们的解释器中,环境是静态作用域的动态体现。两者大多保持同步—当我们进入一个新的作用域时,我们创建一个新的环境,当我们离开作用域时,我们丢弃它。我们对环境进行的另一个操作是在环境中绑定一个变量。这就是我们的错误所在。
让我们看一下那个有问题的例子,看看在每一步环境是什么样子。首先,我们在全局作用域中声明a。

这给了我们一个只有一个环境,其中包含一个变量。然后我们进入代码块并执行showA()的声明。
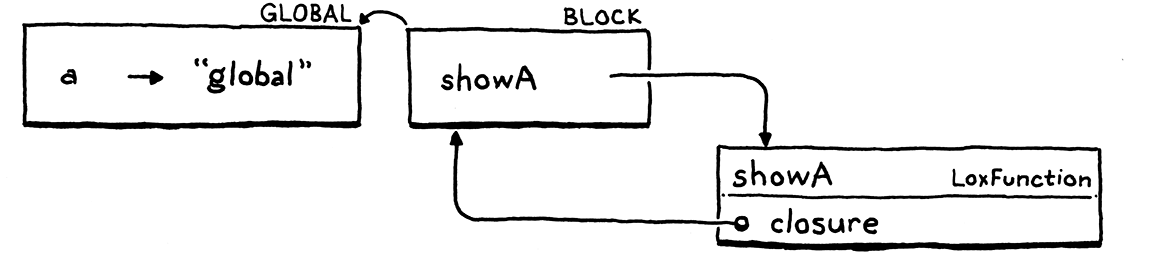
我们为代码块获得了一个新的环境。在那里,我们声明了一个名称showA,它绑定到我们创建的用来表示函数的 LoxFunction 对象。该对象有一个closure字段,它捕获声明函数的环境,因此它对代码块的环境有一个反向引用。
现在我们调用showA()。
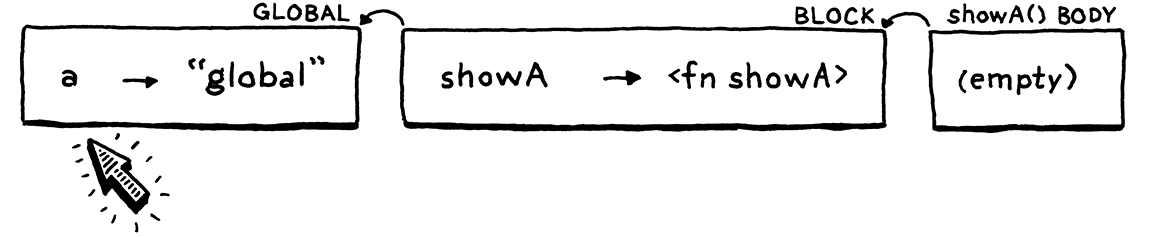
解释器动态地为showA()的函数体创建了一个新的环境。它是空的,因为该函数没有声明任何变量。该环境的父级是函数的闭包—外部代码块环境。
在showA()的函数体内部,我们打印a的值。解释器通过遍历环境链来查找此值。它一直走到全局环境,然后在那里找到它并打印"global"。很好。
接下来,我们声明第二个a,这次是在代码块内。
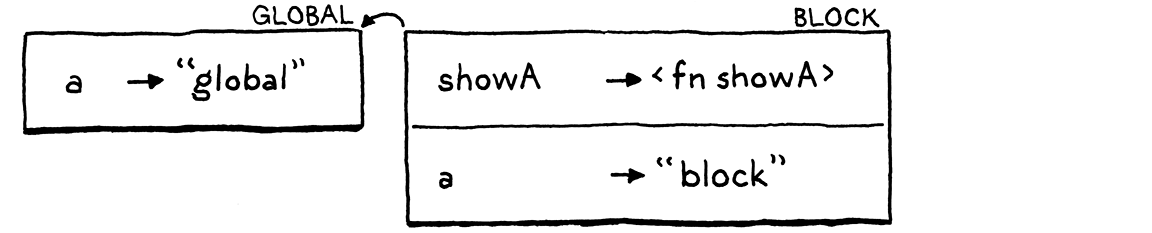
它与showA()位于同一个代码块—同一个作用域—,因此它位于同一个环境中,这也是showA()的闭包引用的同一个环境。这就是它变得有趣的地方。我们再次调用showA()。
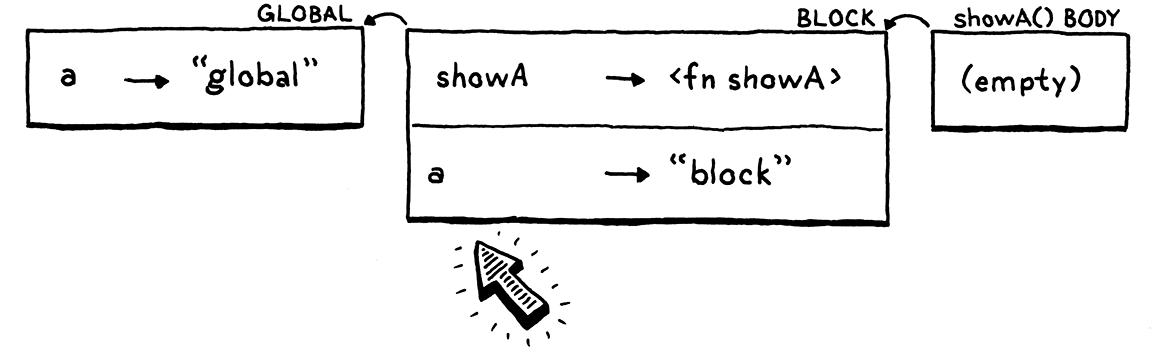
我们再次为showA()的函数体创建了一个新的空环境,将其连接到该闭包,并运行函数体。当解释器遍历环境链以查找a时,它现在在代码块环境中发现了新的a。太糟糕了。
我选择以一种我认为与你对作用域的非正式直觉相符的方式来实现环境。我们倾向于将代码块内的所有代码都视为同一个作用域,因此我们的解释器使用一个环境来表示它。每个环境都是一个可变的哈希表。当声明一个新的局部变量时,它将被添加到该作用域的现有环境中。
这种直觉,就像生活中许多事情一样,并不完全正确。代码块不一定都属于同一个作用域。考虑一下
{
var a;
// 1.
var b;
// 2.
}
在第一条标注线处,只有a在作用域内。在第二条线处,a和b都在作用域内。如果你将“作用域”定义为一组声明,那么它们显然不是同一个作用域—它们不包含相同的声明。这就像每个var语句拆分代码块为两个独立的作用域,变量声明之前的作用域和变量声明之后的包含新变量的作用域。
但在我们的实现中,环境确实表现得好像整个代码块是一个作用域,只是一个随着时间推移而变化的作用域。闭包不喜欢这样。当声明一个函数时,它会捕获对当前环境的引用。函数应该捕获对声明函数时存在的环境的冻结快照。但是,在 Java 代码中,它对实际的可变环境对象有一个引用。当后来在该环境所对应的作用域中声明一个变量时,闭包会看到新变量,即使声明没有在函数之前。
11 . 1 . 2持久环境
有一种编程风格使用称为持久数据结构的东西。与你在命令式编程中熟悉的软绵绵的数据结构不同,持久数据结构永远不会被直接修改。相反,对现有结构的任何“修改”都会生成一个全新的对象,其中包含所有原始数据和新修改。原始数据保持不变。
如果我们将该技术应用于 Environment,那么每次你声明一个变量时,它都会返回一个新的环境,其中包含所有先前声明的变量以及一个新名称。声明一个变量会执行隐式的“拆分”,你会有变量声明之前的环境和变量声明之后的环境
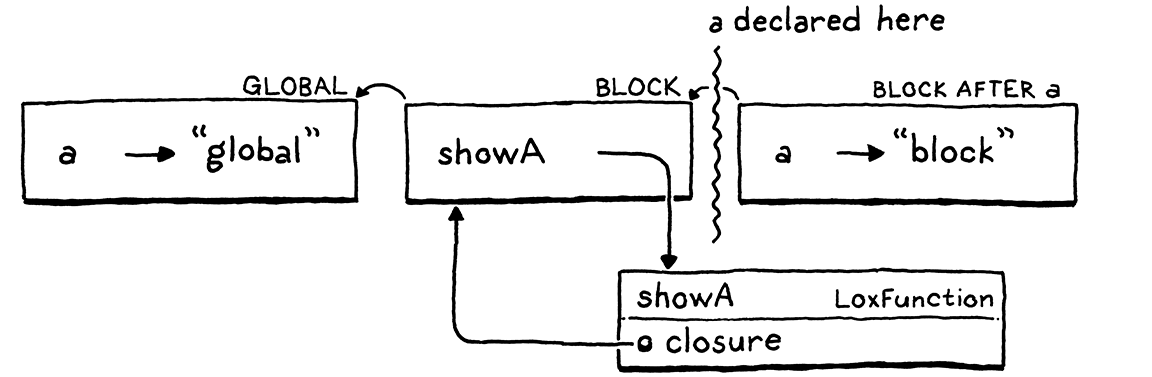
闭包会保留对声明函数时使用的 Environment 实例的引用。由于该代码块中的任何后续声明都会生成新的 Environment 对象,因此闭包不会看到新变量,我们的错误就会被修复。
这是一种解决问题的合法方法,也是在 Scheme 解释器中实现环境的经典方法。我们可以为 Lox 做到这一点,但这将意味着要回到过去,改变一大堆现有的代码。
我不会让你经历那样的痛苦。我们将保持我们表示环境的方式不变。与其使数据变得更静态地结构化,我们将在访问操作本身中烘焙静态解析。
11 . 2语义分析
我们的解释器解析一个变量—跟踪它引用的是哪个声明—每次计算变量表达式时。如果该变量被包裹在一个运行一千次的循环中,那么该变量将被重新解析一千次。
我们知道静态作用域意味着变量使用始终解析为相同的声明,而这可以通过查看文本来确定。既然如此,为什么我们每次都动态地这样做呢?这样做不仅会打开导致我们恼人的错误的漏洞,而且效率低下。
一个更好的解决方案是一次解决每个变量的使用。编写一段代码来检查用户的程序,找到提到的每个变量,并找出每个变量引用哪个声明。这个过程是语义分析的一个例子。解析器只告诉程序是否在语法上正确(语法分析),语义分析更进一步,开始弄清楚程序的各个部分实际上是什么意思。在本例中,我们的分析将解析变量绑定。我们不仅会知道一个表达式是一个变量,还会知道它是哪个变量。
我们有很多方法可以存储变量与其声明之间的绑定。当我们使用 Lox 的 C 解释器时,我们将有更高效的方式来存储和访问局部变量。但对于 jlox,我想将我们对现有代码库造成的附带损害降到最低。我讨厌扔掉一大堆基本上可以正常工作的代码。
相反,我们将以一种充分利用现有 Environment 类的方式存储解析结果。回想一下在有问题的示例中如何解释对 a 的访问。
在第一次(正确)评估中,我们在链中查看了三个环境,然后找到了 a 的全局声明。然后,当内部 a 后来在块作用域中声明时,它会遮蔽全局变量。
下一次查找遍历链,在第二个环境中找到 a 并停止。每个环境对应于一个声明变量的单一词法作用域。如果我们可以确保变量查找始终遍历环境链中的相同数量的链接,那么它将确保每次都在相同作用域中找到相同的变量。
为了“解析”变量使用,我们只需要计算声明的变量在环境链中将有多少个“跳跃”。有趣的问题是何时进行此计算—或者,换句话说,在解释器实现的哪个位置我们插入它的代码?
由于我们正在根据源代码的结构计算一个静态属性,所以显而易见的答案是在解析器中。这是传统的做法,也是我们稍后在 clox 中将其放置的位置。它在这里也可以工作,但我想要一个借口来向你展示另一种技术。我们将编写我们的解析器作为单独的一遍。
11 . 2 . 1变量解析遍
在解析器生成语法树之后,但在解释器开始执行它之前,我们将对树进行单次遍历以解析它包含的所有变量。解析和执行之间额外的遍很常见。如果 Lox 有静态类型,我们可以将类型检查器放入其中。优化通常也以这种方式在单独的遍中实现。基本上,任何不依赖于仅在运行时可用的状态的工作都可以用这种方式完成。
我们的变量解析遍就像一个迷你解释器。它遍历树,访问每个节点,但静态分析不同于动态执行
-
没有副作用。当静态分析访问打印语句时,它不会真正打印任何内容。对本机函数或其他扩展到外部世界的操作的调用将被存根化并且没有影响。
-
没有控制流。循环只访问一次。
if语句中会访问两个分支。逻辑运算符不会短路。
11 . 3Resolver 类
就像 Java 中的一切一样,我们的变量解析遍体现在一个类中。
新建文件
package com.craftinginterpreters.lox; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Stack; class Resolver implements Expr.Visitor<Void>, Stmt.Visitor<Void> { private final Interpreter interpreter; Resolver(Interpreter interpreter) { this.interpreter = interpreter; } }
由于解析器需要访问语法树中的每个节点,因此它实现了我们已经在位的访问者抽象。在解析变量方面,只有几种类型的节点是有趣的
-
块语句为它包含的语句引入了新的作用域。
-
函数声明为其主体引入了新的作用域并在该作用域中绑定其参数。
-
变量声明在当前作用域中添加一个新变量。
-
变量和赋值表达式需要解析它们的变量。
其他节点没有做任何特殊的事情,但我们仍然需要为它们实现 visit 方法来遍历它们的子树。即使+表达式本身没有要解析的变量,它的任何操作数也可能存在。
11 . 3 . 1解析块
我们从块开始,因为它们创建了所有魔法发生的地方的局部作用域。
在Resolver() 之后添加
@Override public Void visitBlockStmt(Stmt.Block stmt) { beginScope(); resolve(stmt.statements); endScope(); return null; }
这将开始一个新的作用域,遍历块内部的语句,然后丢弃作用域。有趣的部分存在于这些帮助方法中。我们从简单的一个开始。
在Resolver() 之后添加
void resolve(List<Stmt> statements) { for (Stmt statement : statements) { resolve(statement); } }
这遍历一个语句列表并解析每个语句。它依次调用
在visitBlockStmt() 之后添加
private void resolve(Stmt stmt) { stmt.accept(this); }
趁我们正在这里,让我们添加另一个稍后需要用来解析表达式的重载。
在resolve(Stmt stmt) 之后添加
private void resolve(Expr expr) { expr.accept(this); }
这些方法类似于 Interpreter 中的 evaluate() 和 execute() 方法—它们反过来对给定的语法树节点应用访问者模式。
真正有趣的行为围绕着作用域。新的块作用域创建如下
在resolve() 之后添加
private void beginScope() { scopes.push(new HashMap<String, Boolean>()); }
词法作用域在解释器和解析器中都嵌套。它们表现得像一个栈。解释器使用链表实现该栈—Environment 对象链。在解析器中,我们使用实际的 Java Stack。
private final Interpreter interpreter;
在类Resolver 中
private final Stack<Map<String, Boolean>> scopes = new Stack<>();
Resolver(Interpreter interpreter) {
此字段跟踪当前处于作用域中的作用域栈。栈中的每个元素都是一个 Map,代表一个单一的块作用域。与 Environment 一样,键是变量名。值为布尔值,原因我将在稍后解释。
作用域栈仅用于局部块作用域。在全局作用域的顶层声明的变量不会被解析器跟踪,因为它们在 Lox 中更动态。在解析变量时,如果我们在局部作用域栈中找不到它,我们假设它一定是全局的。
由于作用域存储在显式栈中,因此退出一个作用域很简单。
在beginScope() 之后添加
private void endScope() { scopes.pop(); }
现在我们可以推入和弹出空作用域的栈。让我们在其中放入一些东西。
11 . 3 . 2解析变量声明
解析变量声明将一个新条目添加到当前最内部作用域的映射中。这似乎很简单,但我们需要做一个小舞步。
在visitBlockStmt() 之后添加
@Override public Void visitVarStmt(Stmt.Var stmt) { declare(stmt.name); if (stmt.initializer != null) { resolve(stmt.initializer); } define(stmt.name); return null; }
为了处理类似这样的奇怪边缘情况,我们将绑定分为两个步骤,声明然后定义
var a = "outer"; { var a = a; }
当局部变量的初始化程序引用一个与被声明变量具有相同名称的变量时会发生什么?我们有几个选择
-
运行初始化程序,然后将新变量置于作用域中。在这里,新的局部
a将使用“outer”初始化,即全局变量的值。换句话说,之前的声明将被糖化为var temp = a; // Run the initializer. var a; // Declare the variable. a = temp; // Initialize it.
-
将新变量置于作用域中,然后运行初始化程序。这意味着你可以在变量初始化之前观察它,因此我们需要弄清楚它当时将是什么值。可能是
nil。这意味着新的局部a将被重新初始化为它自己的隐式初始化值nil。现在,糖化将如下所示var a; // Define the variable. a = a; // Run the initializer.
-
在初始化程序中引用变量将导致错误。如果初始化程序提到了正在初始化的变量,让解释器在编译时或运行时失败。
前两种选项中的任何一个看起来像是用户真正想要的吗?遮蔽很少见,通常是一个错误,因此根据被遮蔽变量的值初始化一个遮蔽变量似乎不太可能是故意的。
第二个选项更没有用。新变量将始终具有 nil 值。以名称提及它没有任何意义。你可以使用显式的 nil 代替。
由于前两种选项可能会掩盖用户错误,因此我们将选择第三种。此外,我们将使其成为编译错误而不是运行时错误。这样,用户在运行任何代码之前都会收到有关问题的提醒。
为了做到这一点,当我们访问表达式时,我们需要知道我们是否在某个变量的初始化程序内部。我们通过将绑定分为两个步骤来做到这一点。第一步是声明它。
在endScope() 之后添加
private void declare(Token name) { if (scopes.isEmpty()) return; Map<String, Boolean> scope = scopes.peek(); scope.put(name.lexeme, false); }
声明将变量添加到最内部的作用域中,以便它遮蔽任何外部作用域,并且让我们知道变量存在。我们通过将变量名绑定到作用域映射中的 false 来将其标记为“尚未准备就绪”。与作用域映射中键关联的值表示我们是否已完成解析该变量的初始化程序。
在声明变量之后,我们在同一个作用域中解析它的初始化程序表达式,新变量现在存在但在该作用域中不可用。一旦初始化程序表达式完成,该变量就已准备好投入使用。我们通过定义它来做到这一点。
在declare() 之后添加
private void define(Token name) { if (scopes.isEmpty()) return; scopes.peek().put(name.lexeme, true); }
我们将作用域映射中的变量值设置为 true 以将其标记为已完全初始化并可供使用。它活了!
11 . 3 . 3解析变量表达式
变量声明—以及我们将要提到的函数声明—写入作用域映射。当我们解析变量表达式时,将读取这些映射。
在visitVarStmt() 之后添加
@Override public Void visitVariableExpr(Expr.Variable expr) { if (!scopes.isEmpty() && scopes.peek().get(expr.name.lexeme) == Boolean.FALSE) { Lox.error(expr.name, "Can't read local variable in its own initializer."); } resolveLocal(expr, expr.name); return null; }
首先,我们检查变量是否在其自己的初始化程序内部被访问。这就是作用域映射中的值发挥作用的地方。如果变量存在于当前作用域中,但它的值为 false,则表示我们已声明它但尚未定义它。我们报告该错误。
在进行该检查之后,我们使用此帮助程序实际解析变量本身
在define() 之后添加
private void resolveLocal(Expr expr, Token name) { for (int i = scopes.size() - 1; i >= 0; i--) { if (scopes.get(i).containsKey(name.lexeme)) { interpreter.resolve(expr, scopes.size() - 1 - i); return; } } }
出于充分的理由,这看起来很像 Environment 中用于评估变量的代码。我们从最内部的作用域开始,向外工作,在每个映射中查找匹配的名称。如果我们找到变量,我们将其解析,传入当前最内部作用域与找到变量的作用域之间的作用域数量。因此,如果在当前作用域中找到变量,我们传入 0。如果它在紧邻的封闭作用域中,则为 1。你明白了。
如果我们遍历所有块作用域并且从未找到该变量,我们将将其解析,并假设它是全局变量。我们将在稍后介绍 resolve() 方法的实现。现在,让我们继续处理其他语法节点。
11 . 3 . 4解析赋值表达式
引用变量的另一个表达式是赋值。解析一个看起来像这样
在visitVarStmt() 之后添加
@Override public Void visitAssignExpr(Expr.Assign expr) { resolve(expr.value); resolveLocal(expr, expr.name); return null; }
首先,我们解析表达式以获取分配的值,以防它包含对其他变量的引用。然后,我们使用现有的 `resolveLocal()` 方法来解析要分配的变量。
11 . 3 . 5解析函数声明
最后,是函数。函数既绑定名称,也引入作用域。函数本身的名称在声明函数的周围作用域中绑定。当我们进入函数体时,我们也将它的参数绑定到该内部函数作用域中。
在visitBlockStmt() 之后添加
@Override public Void visitFunctionStmt(Stmt.Function stmt) { declare(stmt.name); define(stmt.name); resolveFunction(stmt); return null; }
类似于 `visitVariableStmt()`,我们在当前作用域中声明和定义函数的名称。然而,与变量不同的是,我们在解析函数体之前急切地定义了名称。这使得函数可以在它自己的函数体内递归地引用自身。
然后,我们使用以下方法解析函数体
在resolve() 之后添加
private void resolveFunction(Stmt.Function function) { beginScope(); for (Token param : function.params) { declare(param); define(param); } resolve(function.body); endScope(); }
它是一个单独的方法,因为我们稍后在添加类时也会用它来解析 Lox 方法。它为函数体创建一个新作用域,然后为每个函数的参数绑定变量。
准备就绪后,它将在该作用域中解析函数体。这与解释器处理函数声明的方式不同。在 _运行时_,声明函数不会对函数体做任何处理。函数体只有在稍后调用该函数时才会被处理。在 _静态_ 分析中,我们立即遍历函数体。
11 . 3 . 6解析其他语法树节点
这涵盖了语法的有趣部分。我们处理了每个声明、读取或写入变量的地方,以及每个创建或销毁作用域的地方。即使它们不受变量解析的影响,我们也需要对所有其他语法树节点进行访问方法,以便递归到它们的子树中。 对不起 这部分很无聊,但请耐心等待。我们将以“自上而下”的方式进行,从语句开始。
表达式语句包含单个表达式以供遍历。
在visitBlockStmt() 之后添加
@Override public Void visitExpressionStmt(Stmt.Expression stmt) { resolve(stmt.expression); return null; }
if 语句有一个用于条件的表达式,以及一个或两个用于分支的语句。
在 `visitFunctionStmt()` 后添加
@Override public Void visitIfStmt(Stmt.If stmt) { resolve(stmt.condition); resolve(stmt.thenBranch); if (stmt.elseBranch != null) resolve(stmt.elseBranch); return null; }
在这里,我们看到了解析与解释的不同之处。当我们解析 `if` 语句时,没有控制流。我们解析条件和 _两个_ 分支。动态执行只执行 _正在_ 运行的分支,而静态分析是保守的—它分析了 _可能_ 会运行的任何分支。由于运行时可以访问任一分支,因此我们解析了这两个分支。
像表达式语句一样,`print` 语句包含一个子表达式。
在 `visitIfStmt()` 后添加
@Override public Void visitPrintStmt(Stmt.Print stmt) { resolve(stmt.expression); return null; }
对 return 语句也是一样的。
在 `visitPrintStmt()` 后添加
@Override public Void visitReturnStmt(Stmt.Return stmt) { if (stmt.value != null) { resolve(stmt.value); } return null; }
与 `if` 语句一样,在 `while` 语句中,我们解析它的条件,并恰好解析一次函数体。
在visitVarStmt() 之后添加
@Override public Void visitWhileStmt(Stmt.While stmt) { resolve(stmt.condition); resolve(stmt.body); return null; }
这涵盖了所有语句。接下来是表达式 . . .
我们熟悉的二元表达式。我们遍历并解析两个操作数。
在 `visitAssignExpr()` 后添加
@Override public Void visitBinaryExpr(Expr.Binary expr) { resolve(expr.left); resolve(expr.right); return null; }
调用类似—我们遍历参数列表并解析它们。被调用的内容也是一个表达式(通常是变量表达式),所以它也会被解析。
在 `visitBinaryExpr()` 后添加
@Override public Void visitCallExpr(Expr.Call expr) { resolve(expr.callee); for (Expr argument : expr.arguments) { resolve(argument); } return null; }
括号很简单。
在 `visitCallExpr()` 后添加
@Override public Void visitGroupingExpr(Expr.Grouping expr) { resolve(expr.expression); return null; }
字面量最简单。
在 `visitGroupingExpr()` 后添加
@Override public Void visitLiteralExpr(Expr.Literal expr) { return null; }
字面量表达式不包含任何变量,也不包含任何子表达式,因此不需要进行任何操作。
由于静态分析不做控制流或短路,逻辑表达式与其他二元运算符完全相同。
在 `visitLiteralExpr()` 后添加
@Override public Void visitLogicalExpr(Expr.Logical expr) { resolve(expr.left); resolve(expr.right); return null; }
最后,是最后一个节点。我们解析它的一个操作数。
在 `visitLogicalExpr()` 后添加
@Override public Void visitUnaryExpr(Expr.Unary expr) { resolve(expr.right); return null; }
有了所有这些访问方法,Java 编译器应该会满足 Resolver 完全实现了 Stmt.Visitor 和 Expr.Visitor 的要求。现在是休息、吃点零食、或许小睡一下的好时机。
11 . 4解释解析的变量
让我们看看我们的解析器有什么用。每次它访问一个变量时,它都会告诉解释器当前作用域与定义变量的作用域之间有多少个作用域。在运行时,这与解释器可以在当前作用域与包含变量值的封闭作用域之间找到的 _环境_ 数量完全一致。解析器通过调用以下方法将该数字传递给解释器
在 `execute()` 后添加
void resolve(Expr expr, int depth) { locals.put(expr, depth); }
我们希望将解析信息存储在某个地方,以便在稍后执行变量或赋值表达式时使用它,但存储在哪里?一个显而易见的地方是直接在语法树节点本身中。这是一种不错的做法,也是许多编译器存储此类分析结果的地方。
我们可以这样做,但它需要修改我们的语法树生成器。相反,我们将采用另一种常见的方法,将它存储在旁边,在一个将每个语法树节点与其解析数据关联的映射中。
像 IDE 这样的交互式工具通常会增量地重新解析和重新解析用户程序的各个部分。当这些状态隐藏在语法树的枝叶中时,可能很难找到所有需要重新计算的状态位。将这些数据存储在节点之外的一个好处是,它使我们能够轻松地_丢弃_ 它—只需清除映射即可。
private Environment environment = globals;
在 `Interpreter` 类中
private final Map<Expr, Integer> locals = new HashMap<>();
Interpreter() {
你可能会认为我们需要某种嵌套树结构来避免在多个表达式引用同一个变量时出现混乱,但每个表达式节点都是具有自身唯一标识的独立 Java 对象。单个单片映射可以轻松地将它们分开。
与往常一样,使用集合需要我们导入几个名称。
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
还有
import java.util.List;
import java.util.Map;
class Interpreter implements Expr.Visitor<Object>,
11 . 4 . 1访问解析的变量
我们的解释器现在可以访问每个变量的解析位置。最后,我们开始使用它。我们用以下方法替换变量表达式的访问方法
public Object visitVariableExpr(Expr.Variable expr) {
在 `visitVariableExpr()` 中
替换 1 行
return lookUpVariable(expr.name, expr);
}
它委托给
在 `visitVariableExpr()` 后添加
private Object lookUpVariable(Token name, Expr expr) { Integer distance = locals.get(expr); if (distance != null) { return environment.getAt(distance, name.lexeme); } else { return globals.get(name); } }
这里发生了几件事。首先,我们在映射中查找解析的距离。请记住,我们只解析了_局部_ 变量。全局变量的处理方式有所不同,并且不会出现在映射中(因此名称为 `locals`)。因此,如果我们在映射中找不到距离,则它一定是全局的。在这种情况下,我们在全局环境中直接动态查找它。如果该变量未定义,则会抛出运行时错误。
如果我们_确实_ 获取了距离,那么我们有一个局部变量,并且可以利用静态分析的结果。我们不是调用 `get()`,而是调用 Environment 上的这个新方法
在define() 之后添加
Object getAt(int distance, String name) { return ancestor(distance).values.get(name); }
`getAt()` 相当于 `get()`,它动态地遍历封闭环境链,搜索每个环境以查看变量是否可能隐藏在那里。但现在我们确切地知道链中的哪个环境包含该变量。我们使用以下辅助方法访问它
在define() 之后添加
Environment ancestor(int distance) { Environment environment = this; for (int i = 0; i < distance; i++) { environment = environment.enclosing; } return environment; }
它向上遍历父级链固定的次数,然后返回那里的环境。一旦我们有了它,`getAt()` 就会简单地返回该环境映射中变量的值。它甚至不需要检查变量是否在那里—我们知道它会存在,因为解析器之前已经找到了它。
11 . 4 . 2将值分配给解析的变量
我们还可以通过将值分配给变量来使用变量。访问赋值表达式的更改类似。
public Object visitAssignExpr(Expr.Assign expr) {
Object value = evaluate(expr.value);
在 `visitAssignExpr()` 中
替换 1 行
Integer distance = locals.get(expr);
if (distance != null) {
environment.assignAt(distance, expr.name, value);
} else {
globals.assign(expr.name, value);
}
return value;
同样,我们查找变量的作用域距离。如果未找到,我们假设它是全局的,并像以前一样处理它。否则,我们调用这个新方法
在 `getAt()` 后添加
void assignAt(int distance, Token name, Object value) { ancestor(distance).values.put(name.lexeme, value); }
`assignAt()` 相当于 `assign()`,它遍历固定数量的环境,然后将新值填充到该映射中。
这些是 Interpreter 的唯一更改。这就是我选择解析数据表示方式的原因,这种方式对我们的侵入性最小。所有其他节点都将继续像以前一样工作。即使修改环境的代码也保持不变。
11 . 4 . 3运行解析器
但是,我们确实需要_运行_ 解析器。我们将新的传递插入解析器执行完操作之后。
// Stop if there was a syntax error.
if (hadError) return;
在 `run()` 中
Resolver resolver = new Resolver(interpreter); resolver.resolve(statements);
interpreter.interpret(statements);
如果存在任何解析错误,我们不会运行解析器。如果代码存在语法错误,它将永远不会运行,因此解析它没有太大意义。如果语法正确,我们告诉解析器执行其操作。解析器引用解释器,并在遍历变量时直接将解析数据插入解释器中。当解释器下次运行时,它将拥有它需要的一切。
至少,如果解析器_成功_,就会如此。但解析期间的错误怎么办呢?
11 . 5解析错误
由于我们正在执行语义分析传递,因此我们有机会使 Lox 的语义更加精确,并帮助用户在运行代码之前及早捕获错误。来看看这个不好的家伙
fun bad() { var a = "first"; var a = "second"; }
我们确实允许在_全局_ 作用域中声明多个具有相同名称的变量,但在局部作用域中这样做可能是一个错误。如果他们知道变量已经存在,他们会将值分配给它,而不是使用 `var`。如果他们_不知道_ 它是否存在,他们可能并不打算覆盖之前的变量。
我们可以在解析过程中静态地检测到这个错误。
Map<String, Boolean> scope = scopes.peek();
在 `declare()` 中
if (scope.containsKey(name.lexeme)) { Lox.error(name, "Already a variable with this name in this scope."); }
scope.put(name.lexeme, false);
当我们在局部作用域中声明一个变量时,我们已经知道该作用域中之前声明的所有变量的名称。如果我们看到冲突,我们将报告错误。
11 . 5 . 1无效的 return 错误
这是另一个令人讨厌的小脚本
return "at top level";
它执行了一个 `return` 语句,但它甚至不在任何函数中。它是顶层代码。我不知道用户_认为_ 会发生什么,但我认为我们不想让 Lox 允许这样做。
我们可以扩展解析器来静态地检测到这种情况。就像我们在遍历语法树时跟踪作用域一样,我们也可以跟踪当前访问的代码是否位于函数声明内部。
private final Stack<Map<String, Boolean>> scopes = new Stack<>();
在类Resolver 中
private FunctionType currentFunction = FunctionType.NONE;
Resolver(Interpreter interpreter) {
我们使用这种奇怪的枚举类型,而不是直接使用布尔值。
在Resolver() 之后添加
private enum FunctionType { NONE, FUNCTION }
现在看起来可能有点蠢,但我们稍后会添加几个更多的情况,到那时它就会更有意义。当我们解析函数声明时,我们会将它传递进去。
define(stmt.name);
在 visitFunctionStmt() 中
替换 1 行
resolveFunction(stmt, FunctionType.FUNCTION);
return null;
在 resolveFunction() 中,我们接受该参数并将其存储在字段中,然后再解析函数体。
方法 resolveFunction()
替换 1 行
private void resolveFunction( Stmt.Function function, FunctionType type) { FunctionType enclosingFunction = currentFunction; currentFunction = type;
beginScope();
我们首先将字段的先前值存储在一个局部变量中。记住,Lox 允许使用局部函数,因此您可以任意深度地嵌套函数声明。我们需要跟踪的不仅是是否在函数中,还要跟踪我们位于 多少个 函数内部。
我们可以为此使用显式堆栈来存储 FunctionType 值,但我们将会利用 JVM。我们将先前值存储在 Java 堆栈上的一个局部变量中。当我们完成对函数体的解析后,我们将字段恢复到该值。
endScope();
在 resolveFunction() 中
currentFunction = enclosingFunction;
}
现在我们总是可以知道是否在函数声明内部,因此我们在解析 return 语句时会进行检查。
public Void visitReturnStmt(Stmt.Return stmt) {
在 visitReturnStmt() 中
if (currentFunction == FunctionType.NONE) { Lox.error(stmt.keyword, "Can't return from top-level code."); }
if (stmt.value != null) {
很酷,对吧?
还有一个部分。在将所有内容整合到一起的主 Lox 类中,我们小心地避免在遇到任何解析错误时运行解释器。该检查在解析器之前运行,因此我们不会尝试解析语法上无效的代码。
但我们还需要在遇到解析错误时跳过解释器,因此我们添加了 另一个 检查。
resolver.resolve(statements);
在 `run()` 中
// Stop if there was a resolution error.
if (hadError) return;
interpreter.interpret(statements);
您可以想象在这里进行许多其他分析。例如,如果我们在 Lox 中添加了 break 语句,我们可能希望确保它们仅在循环内部使用。
我们可以更进一步,对并非 错误 但可能没有用的代码发出警告。例如,许多 IDE 会在遇到 return 语句后的不可达代码,或其值从未被读取的局部变量时发出警告。所有这些都很容易添加到我们的静态访问阶段,或作为 单独 的阶段。
但是,现在,我们将坚持使用这种有限的分析。重要的是我们修复了那个奇怪的恼人的边缘情况错误,尽管它可能令人惊讶的是修复它需要这么多工作。
挑战
-
为什么在其他变量必须等到初始化之后才能使用时,我们可以提前定义绑定到函数名称的变量呢?
-
您所知道的其他语言是如何处理在初始化器中引用相同名称的局部变量的,例如
var a = "outer"; { var a = a; }
是运行时错误吗?编译错误吗?允许吗?它们是否对全局变量的处理有所不同?您是否同意他们的选择?请说明您的答案。
-
扩展解析器,如果局部变量从未使用过,则报告错误。
-
我们的解析器计算出 哪个 环境中发现了该变量,但它仍然在该映射中按名称进行查找。更有效率的环境表示将局部变量存储在数组中,并通过索引进行查找。
扩展解析器,为每个在作用域中声明的局部变量关联一个唯一的索引。在解析变量访问时,同时查找变量所在的范围及其索引,并存储它。在解释器中,使用它通过索引快速访问变量,而不是使用映射。