调用和函数
计算机科学中的任何问题都可以通过再增加一层间接性来解决。除了间接层太多这个情况。
戴维·惠勒
本章内容有点难。我尽量把功能拆分成小块,但有时你不得不把整个食物吞下去。我们的下一个任务是函数。我们可以先从函数声明开始,但如果你不能调用它们,这没什么用。我们可以做调用,但没有东西可以被调用。而且虚拟机中支持这两者的所有运行时支持,如果它们没有连接到任何你可以看到的东西,那就没有那么有意义了。所以我们要把所有都做完。虽然很多,但我们做完后会感觉很好。
24 . 1函数对象
虚拟机中最有趣的结构变化是围绕堆栈的。我们已经拥有了用于局部变量和临时变量的堆栈,所以我们已经完成了一部分。但我们没有关于调用堆栈的概念。在我们能够取得很大进展之前,我们必须解决这个问题。但首先,让我们写一些代码。一旦开始移动,我总是感觉更好。如果没有某种函数表示形式,我们做不了太多,所以我们从那里开始。从虚拟机的角度来看,函数是什么?
函数有一个可以执行的主体,这意味着一些字节码。我们可以将整个程序及其所有函数声明编译成一个大的单片 Chunk。每个函数都会有一个指向其代码在 Chunk 中的第一个指令的指针。
这大致是编译到原生代码的工作方式,最终你得到一个完整的机器代码块。但对于我们的字节码虚拟机,我们可以做一些更高级的事情。我认为一个更清晰的模型是给每个函数一个自己的 Chunk。我们还需要一些其他元数据,所以让我们现在就全部塞到一个结构体中。
struct Obj* next; };
在 struct Obj 之后添加
typedef struct { Obj obj; int arity; Chunk chunk; ObjString* name; } ObjFunction;
struct ObjString {
函数在 Lox 中是一等公民,所以它们需要成为实际的 Lox 对象。因此 ObjFunction 具有所有对象类型共享的相同的 Obj 头。arity 字段存储函数期望的参数数量。然后,除了 chunk 之外,我们还存储函数的名称。这对报告可读的运行时错误会很有用。
这是“对象”模块第一次需要引用 Chunk,所以我们需要一个 include。
#include "common.h"
#include "chunk.h"
#include "value.h"
就像我们对字符串所做的那样,我们定义了一些辅助程序,以便在 C 中更容易使用 Lox 函数。这是一种比较简陋的面向对象风格。首先,我们将声明一个 C 函数来创建一个新的 Lox 函数。
uint32_t hash; };
在 struct ObjString 之后添加
ObjFunction* newFunction();
ObjString* takeString(char* chars, int length);
实现在这里
在 allocateObject() 之后添加
ObjFunction* newFunction() { ObjFunction* function = ALLOCATE_OBJ(ObjFunction, OBJ_FUNCTION); function->arity = 0; function->name = NULL; initChunk(&function->chunk); return function; }
我们使用我们的朋友 ALLOCATE_OBJ() 来分配内存并初始化对象的头部,以便虚拟机知道它是什么类型的对象。我们没有像对 ObjString 那样传递参数来初始化函数,而是将函数设置为一种空白状态—零元数、没有名称、没有代码。这些将在函数创建后稍后填充。
由于我们有了一种新的对象类型,我们需要在枚举中添加一种新的对象类型。
typedef enum {
在 enum ObjType 中
OBJ_FUNCTION,
OBJ_STRING, } ObjType;
当我们完成一个函数对象时,我们必须将它借用的位返回给操作系统。
switch (object->type) {
在 freeObject() 中
case OBJ_FUNCTION: { ObjFunction* function = (ObjFunction*)object; freeChunk(&function->chunk); FREE(ObjFunction, object); break; }
case OBJ_STRING: {
这个 switch case 负责 释放 ObjFunction 本身以及它拥有的任何其他内存。函数拥有它们的 chunk,所以我们调用 Chunk 的类似析构函数的函数。
Lox 允许你打印任何对象,而函数是一等公民,所以我们也需要处理它们。
switch (OBJ_TYPE(value)) {
在 printObject() 中
case OBJ_FUNCTION: printFunction(AS_FUNCTION(value)); break;
case OBJ_STRING:
这调用到
在 copyString() 之后添加
static void printFunction(ObjFunction* function) { printf("<fn %s>", function->name->chars); }
由于函数知道它的名称,它不妨说出来。
最后,我们有几个宏来将值转换为函数。首先,确保你的值确实是函数。
#define OBJ_TYPE(value) (AS_OBJ(value)->type)
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
#define IS_STRING(value) isObjType(value, OBJ_STRING)
假设这评估为 true,那么你可以使用这个安全地将 Value 强制转换为 ObjFunction 指针
#define IS_STRING(value) isObjType(value, OBJ_STRING)
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
#define AS_STRING(value) ((ObjString*)AS_OBJ(value))
有了这些,我们的对象模型就知道了如何表示函数。我现在感觉热身了。你准备好迎接一些更难的事情了吗?
24 . 2编译为函数对象
现在,我们的编译器假设它始终编译为一个单一的 chunk。随着每个函数的代码都存在于单独的 chunk 中,这变得更加复杂。当编译器遇到函数声明时,它需要在编译函数体时将代码发出到函数的 chunk 中。在函数体结束时,编译器需要返回到之前使用的 chunk。
这对函数体内的代码来说没问题,但对于不在函数体内的代码呢?Lox 程序的“顶层”也是指令代码,我们需要一个 chunk 来将其编译进去。我们可以通过将顶层代码也放在一个自动定义的函数中来简化编译器和虚拟机。这样,编译器就始终处于某种函数体内部,而虚拟机始终通过调用函数来运行代码。就好像整个程序都被包裹在一个隐式的 main() 函数中。
在我们开始处理用户定义函数之前,让我们进行重组以支持这个隐式的顶层函数。它从 Compiler 结构体开始。它没有直接指向编译器写入的 Chunk,而是引用了正在构建的函数对象。
typedef struct {
在 struct Compiler 中
ObjFunction* function; FunctionType type;
Local locals[UINT8_COUNT];
我们还有一个小的 FunctionType 枚举。这可以让编译器知道它是在编译顶层代码还是函数体。编译器的大部分内容并不关心这一点—这就是它是一个有用抽象的原因—但在一个或两个地方,这种区别是有意义的。我们以后会讨论其中一个。
在 struct Local 之后添加
typedef enum { TYPE_FUNCTION, TYPE_SCRIPT } FunctionType;
编译器中每个写入 Chunk 的地方都需要通过 function 指针进行。幸运的是,在很多章之前,我们封装了对 chunk 的访问,使用 currentChunk() 函数。我们只需要修复这个,编译器的其他部分就会很高兴。
Compiler* current = NULL;
在变量 current 之后添加
替换 5 行
static Chunk* currentChunk() { return ¤t->function->chunk; }
static void errorAt(Token* token, const char* message) {
当前 chunk 始终是我们正在编译的函数所拥有的 chunk。接下来,我们需要实际创建该函数。以前,虚拟机将一个 Chunk 传递给编译器,编译器用它来填充代码。现在,编译器将创建并返回一个包含已编译顶层代码—目前我们只支持这一点—的函数。
24 . 2 . 1在编译时创建函数
我们从 compile() 中开始穿针引线,它是编译器的主要入口点。
Compiler compiler;
在 compile() 中
替换 2 行
initCompiler(&compiler, TYPE_SCRIPT);
parser.hadError = false;
编译器的初始化方式有很多变化。首先,我们初始化新的 Compiler 字段。
函数 initCompiler()
替换 1 行
static void initCompiler(Compiler* compiler, FunctionType type) { compiler->function = NULL; compiler->type = type;
compiler->localCount = 0;
然后我们分配一个新的函数对象来编译。
compiler->scopeDepth = 0;
在 initCompiler() 中
compiler->function = newFunction();
current = compiler;
在编译器中创建 ObjFunction 似乎有点奇怪。函数对象是函数的运行时表示,但我们是在编译时创建它。可以这样理解,函数类似于字符串或数字字面量。它在编译时和运行时世界之间架起了一座桥梁。当我们谈到函数声明时,这些确实是字面量—它们是产生内置类型值的记法。所以编译器在编译期间创建函数对象。然后,在运行时,它们只是被调用。
这里还有另一段奇怪的代码
current = compiler;
在 initCompiler() 中
Local* local = ¤t->locals[current->localCount++]; local->depth = 0; local->name.start = ""; local->name.length = 0;
}
记住编译器的 locals 数组跟踪哪些堆栈槽位与哪些局部变量或临时变量相关联。从现在开始,编译器隐式地为虚拟机自己的内部使用声明了堆栈槽位零。我们给它一个空名称,这样用户就无法编写引用它的标识符。当它变得有用时,我会解释这是怎么回事。
那是初始化方面。我们还需要在另一端做一些改变,当我们完成一些代码的编译时。
函数 endCompiler()
替换 1 行
static ObjFunction* endCompiler() {
emitReturn();
以前,当 interpret() 调用编译器时,它会传入一个要写入的 Chunk。现在编译器自己创建函数对象,我们返回该函数。我们在这里从当前编译器中获取它
emitReturn();
在 endCompiler() 中
ObjFunction* function = current->function;
#ifdef DEBUG_PRINT_CODE
然后将其返回给 compile(),如下所示
#endif
在 endCompiler() 中
return function;
}
现在是时候在这个函数中进行另一个调整了。之前,我们添加了一些诊断代码,让虚拟机转储反汇编后的字节码,以便我们可以调试编译器。我们应该修复它,使其继续工作,因为现在生成的 chunk 被包装在一个函数中。
#ifdef DEBUG_PRINT_CODE
if (!parser.hadError) {
在 endCompiler() 中
替换 1 行
disassembleChunk(currentChunk(), function->name != NULL ? function->name->chars : "<script>");
} #endif
注意这里面的检查,看看函数的名称是否为 NULL?用户定义的函数有名称,但我们为顶层代码创建的隐式函数没有名称,我们需要在自己的诊断代码中优雅地处理这种情况。说到这里
static void printFunction(ObjFunction* function) {
在 printFunction() 中
if (function->name == NULL) { printf("<script>"); return; }
printf("<fn %s>", function->name->chars);
用户无法获得对顶层函数的引用并尝试打印它,但我们的 DEBUG_TRACE_EXECUTION 诊断 代码可以打印整个堆栈,并且确实会这样做。
将级别提升到 compile(),我们调整其签名。
#include "vm.h"
函数 compile()
替换 1 行
ObjFunction* compile(const char* source);
#endif
它不再接受一个块,而是返回一个函数。在实现中
函数 compile()
替换 1 行
ObjFunction* compile(const char* source) {
initScanner(source);
最后,我们开始编写一些实际的代码。我们将函数的最后部分更改为
while (!match(TOKEN_EOF)) {
declaration();
}
在 compile() 中
替换 2 行
ObjFunction* function = endCompiler(); return parser.hadError ? NULL : function;
}
我们从编译器中获取函数对象。如果没有编译错误,我们将返回它。否则,我们将通过返回 NULL 来发出错误信号。这样,VM 不会尝试执行可能包含无效字节码的函数。
最终,我们将更新 interpret() 以处理 compile() 的新声明,但首先我们还需要进行一些其他更改。
24 . 3调用帧
现在是时候进行一个大的概念性飞跃了。在我们实现函数声明和调用之前,我们需要准备好 VM 以便处理它们。我们需要担心两个主要问题
24 . 3 . 1分配局部变量
编译器为局部变量分配堆栈槽。当程序中的一组局部变量分布在多个函数中时,该怎么做呢?
一个选择是将它们完全分开。每个函数将在 VM 堆栈中获得它自己的专用槽集,它将永远拥有这些槽,即使该函数没有被调用。整个程序中的每个局部变量将在 VM 中保留一块内存,它自己拥有这块内存。
信不信由你,早期的编程语言实现就是以这种方式工作的。第一个 Fortran 编译器会为每个变量静态分配内存。显而易见的问题是效率极低。大多数函数在任何时候都没有处于调用状态,因此对它们保留未使用的内存是浪费的。
然而,更根本的问题是递归。在递归中,您可以同时处于对同一函数的多个调用中。每个函数都需要它自己的内存来存储它的局部变量。在 jlox 中,我们通过在每次调用函数或进入块时为环境动态分配内存来解决这个问题。在 clox 中,我们不想在每次函数调用时都付出这种性能代价。
相反,我们的解决方案介于 Fortran 的静态分配和 jlox 的动态方法之间。VM 中的值堆栈基于这样的观察结果:局部变量和临时变量以后进先出的方式进行操作。幸运的是,即使您将函数调用添加到混合中,这一点仍然适用。以下是一个示例
fun first() { var a = 1; second(); var b = 2; } fun second() { var c = 3; var d = 4; } first();
逐步执行程序,并查看在每个时间点哪些变量在内存中
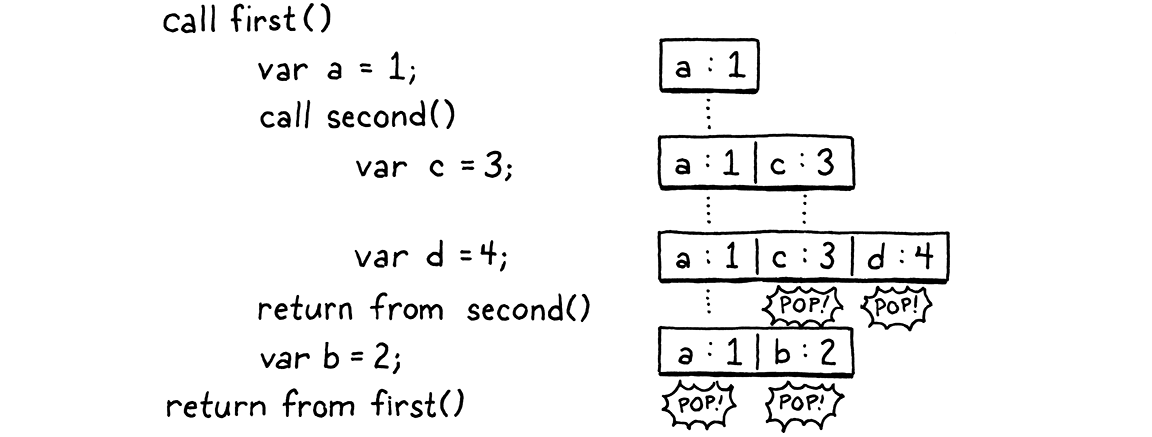
当执行流经两个调用时,每个局部变量都遵循这样的原则:在它之后声明的任何变量都将在第一个变量需要被丢弃之前被丢弃。即使跨越调用,这一点也是正确的。我们知道,在我们完成对 a 的操作之前,我们已经完成了对 c 和 d 的操作。看来我们应该能够在 VM 的值堆栈上分配局部变量。
理想情况下,我们仍然可以在编译时确定每个变量在堆栈中的位置。这样可以使用于处理变量的字节码指令保持简单和快速。在上面的示例中,我们可以想象以一种直接的方式做到这一点,但实际上并不总是可行。考虑以下情况
fun first() { var a = 1; second(); var b = 2; second(); } fun second() { var c = 3; var d = 4; } first();
在第一次调用 second() 时,c 和 d 将分别进入槽位 1 和 2。但在第二次调用中,我们需要为 b腾出空间,因此 c 和 d 需要分别位于槽位 2 和 3。因此,编译器无法在函数调用中为每个局部变量确定确切的槽位。但是,在给定函数内部,每个局部变量的相对位置是固定的。变量 d 始终位于 c 之后的槽位中。这是关键的见解。
当调用函数时,我们不知道堆栈的顶部将位于何处,因为它可以从不同的上下文中调用。但是,无论该顶部碰巧位于何处,我们都知道该函数的所有局部变量相对于该起始点的相对位置。因此,就像许多问题一样,我们通过一层间接来解决我们的分配问题。
在每次函数调用开始时,VM 会记录该函数自己的局部变量开始的第一个槽的位置。用于处理局部变量的指令通过相对于该位置的槽索引来访问它们,而不是像今天这样相对于堆栈底部来访问它们。在编译时,我们计算这些相对槽位。在运行时,我们通过添加函数调用的起始槽位来将该相对槽位转换为绝对堆栈索引。
就好像该函数在更大的堆栈中获得了一个“窗口”或“框架”,它可以在其中存储它的局部变量。调用帧的位置是在运行时确定的,但在该区域内部和相对于该区域,我们知道在哪里可以找到这些变量。
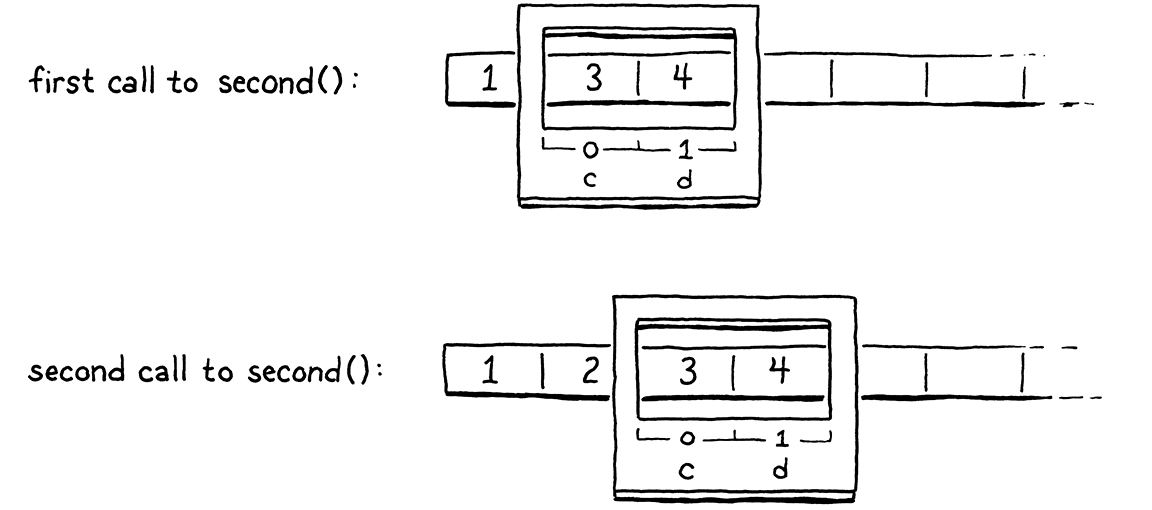
这个记录函数局部变量开始位置的传统名称是帧指针,因为它指向函数调用帧的开头。有时您会听到基指针,因为它指向函数的所有变量都驻留在其顶部的基堆栈槽。
这是我们需要跟踪的第一个数据。每次我们调用函数时,VM 都会确定该函数的变量开始的第一个堆栈槽的位置。
24 . 3 . 2返回地址
现在,VM 通过递增 ip 字段来遍历指令流。唯一有趣的行为是围绕控制流指令的,这些指令会将 ip 偏移更大的量。调用函数很简单—只需将 ip 设置为指向该函数的块中的第一条指令即可。但是,当函数完成时会发生什么?
VM 需要返回到调用该函数的块,并在调用后的下一条指令处恢复执行。因此,对于每个函数调用,我们需要跟踪调用完成后返回的位置。这被称为返回地址,因为它是在调用完成后 VM 返回到的指令的地址。
同样地,由于递归,单个函数可能存在多个返回地址,因此这是每个调用的属性,而不是函数本身的属性。
24 . 3 . 3调用堆栈
因此,对于每个活动的函数调用—每个尚未返回的调用—我们需要跟踪该函数的局部变量在堆栈中的起始位置,以及调用方应继续执行的位置。我们将把这些内容,以及其他一些内容,放在一个新的结构中。
#define STACK_MAX 256
typedef struct { ObjFunction* function; uint8_t* ip; Value* slots; } CallFrame;
typedef struct {
CallFrame 表示单个正在进行的函数调用。slots 字段指向 VM 的值堆栈中的第一个槽,该函数可以使用该槽。我给它一个复数名称,因为—由于 C 的奇怪的“指针有点像数组”的东西—我们将把它像数组一样对待。
返回地址的实现与我上面描述的略有不同。我们不是将返回地址存储在被调用者的帧中,而是由调用者存储它自己的 ip。当我们从函数中返回时,VM 将跳转到调用者的 CallFrame 的 ip 处,并从那里恢复执行。
我还将指向被调用函数的指针塞入这里。我们将使用它来查找常量以及其他一些事情。
每次调用函数时,我们都会创建一个这样的结构。我们可以动态地在堆上分配它们,但这很慢。函数调用是核心操作,因此它们需要尽可能快。幸运的是,我们可以进行与我们对变量进行的相同的观察:函数调用具有堆栈语义。如果 first() 调用 second(),那么对 second() 的调用将在 first() 完成之前完成。
因此,在 VM 中,我们预先创建了一个包含这些 CallFrame 结构的数组,并将它们视为堆栈,就像我们对值数组所做的那样。
typedef struct {
在 struct VM 中
替换 2 行
CallFrame frames[FRAMES_MAX]; int frameCount;
Value stack[STACK_MAX];
此数组替换了我们之前直接在 VM 中使用的 chunk 和 ip 字段。现在每个 CallFrame 都有它自己的 ip 和指向它正在执行的 ObjFunction 的指针。从那里,我们可以访问该函数的块。
VM 中的新 frameCount 字段存储 CallFrame 堆栈的当前高度—正在进行的函数调用的数量。为了使 clox 保持简单,数组的容量是固定的。这意味着,与许多语言实现一样,我们能够处理的最大调用深度是有限的。对于 clox,它在此处定义
#include "value.h"
替换 1 行
#define FRAMES_MAX 64 #define STACK_MAX (FRAMES_MAX * UINT8_COUNT)
typedef struct {
我们还根据它重新定义了值堆栈的大小,以确保即使在非常深的调用树中,我们也有足够多的堆栈槽。当 VM 启动时,CallFrame 堆栈是空的。
vm.stackTop = vm.stack;
在 resetStack() 中
vm.frameCount = 0;
}
“vm.h” 头文件需要访问 ObjFunction,因此我们添加一个包含。
#define clox_vm_h
替换 1 行
#include "object.h"
#include "table.h"
现在,我们准备移至 VM 的实现文件。我们面前有一些艰苦的工作要做。我们已将 ip 从 VM 结构中移出,并将其放入 CallFrame 中。我们需要修复 VM 中涉及 ip 的每一行代码以处理这种情况。此外,通过堆栈槽访问局部变量的指令需要更新,以便相对于当前 CallFrame 的 slots 字段进行访问。
我们将从顶部开始,逐步进行。
static InterpretResult run() {
在 run() 中
替换 4 行
CallFrame* frame = &vm.frames[vm.frameCount - 1]; #define READ_BYTE() (*frame->ip++) #define READ_SHORT() \ (frame->ip += 2, \ (uint16_t)((frame->ip[-2] << 8) | frame->ip[-1])) #define READ_CONSTANT() \ (frame->function->chunk.constants.values[READ_BYTE()])
#define READ_STRING() AS_STRING(READ_CONSTANT())
首先,我们将当前最顶层的 CallFrame 存储在主字节码执行函数中的一个局部变量中。然后,我们将字节码访问宏替换为通过该变量访问 ip 的版本。
现在,让我们开始处理每个需要细心呵护的指令。
case OP_GET_LOCAL: {
uint8_t slot = READ_BYTE();
在 run() 中
替换 1 行
push(frame->slots[slot]);
break;
以前,OP_GET_LOCAL 直接从 VM 的堆栈数组中读取给定的局部变量槽,这意味着它从堆栈底部开始索引该槽。现在,它访问当前帧的 slots 数组,这意味着它访问相对于该帧开头的给定编号槽。
设置局部变量的工作方式相同。
case OP_SET_LOCAL: {
uint8_t slot = READ_BYTE();
在 run() 中
替换 1 行
frame->slots[slot] = peek(0);
break;
跳转指令以前修改 VM 的 ip 字段。现在,它们对当前帧的 ip 做同样的事情。
case OP_JUMP: {
uint16_t offset = READ_SHORT();
在 run() 中
替换 1 行
frame->ip += offset;
break;
条件跳转也是一样。
case OP_JUMP_IF_FALSE: {
uint16_t offset = READ_SHORT();
在 run() 中
替换 1 行
if (isFalsey(peek(0))) frame->ip += offset;
break;
还有我们的向后跳转循环指令。
case OP_LOOP: {
uint16_t offset = READ_SHORT();
在 run() 中
替换 1 行
frame->ip -= offset;
break;
我们有一些诊断代码,它在执行时打印每条指令以帮助我们调试我们的 VM。这需要与新结构一起工作。
printf("\n");
在 run() 中
替换 2 行
disassembleInstruction(&frame->function->chunk, (int)(frame->ip - frame->function->chunk.code));
#endif
现在,我们从当前的 CallFrame 中读取,而不是传入 VM 的 chunk 和 ip 字段。
你知道吗,实际上这并不难。大多数指令只是使用宏,因此不需要修改。接下来,我们向上跳一级到调用 run() 的代码。
InterpretResult interpret(const char* source) {
在 interpret() 中。
替换 10 行。
ObjFunction* function = compile(source); if (function == NULL) return INTERPRET_COMPILE_ERROR; push(OBJ_VAL(function)); CallFrame* frame = &vm.frames[vm.frameCount++]; frame->function = function; frame->ip = function->chunk.code; frame->slots = vm.stack;
InterpretResult result = run();
我们终于将我们之前对编译器的更改与刚刚进行的后端更改连接起来。首先,我们将源代码传递给编译器。它会返回一个包含已编译顶级代码的新 ObjFunction。如果我们得到 NULL,则意味着存在一些编译时错误,编译器已经报告了这些错误。在这种情况下,我们将退出,因为我们无法运行任何内容。
否则,我们将该函数存储在堆栈上,并准备一个初始 CallFrame 来执行其代码。现在您可以看到为什么编译器为堆栈槽零分配了空间—它存储正在调用的函数。在新 CallFrame 中,我们指向该函数,将它的 ip 初始化为指向该函数字节码的开头,并将它的堆栈窗口设置为从 VM 的值堆栈的最底部开始。
这使解释器准备好开始执行代码。在完成之后,VM 以前会释放硬编码的 chunk。现在 ObjFunction 拥有该代码,我们不再需要这样做,因此 interpret() 的结尾很简单,就是下面这样。
frame->slots = vm.stack;
在 interpret() 中。
替换 4 行
return run();
}
引用旧 VM 字段的最后一段代码是 runtimeError()。我们将在本章后面重新讨论它,但现在让我们将其更改为以下内容。
fputs("\n", stderr);
在 runtimeError() 中。
替换 2 行
CallFrame* frame = &vm.frames[vm.frameCount - 1]; size_t instruction = frame->ip - frame->function->chunk.code - 1; int line = frame->function->chunk.lines[instruction];
fprintf(stderr, "[line %d] in script\n", line);
它不是直接从 VM 中读取 chunk 和 ip,而是从堆栈上的最上面的 CallFrame 中提取这些信息。这应该使该函数再次运行并像以前一样运行。
假设我们正确地完成了所有这些操作,我们让 clox 恢复到可运行状态。启动它,它会 . . . 执行它以前执行的操作。我们还没有添加任何新功能,因此这有点令人失望。但是所有基础设施都已到位,现在已经准备就绪。让我们利用它。
24 . 4函数声明
在我们可以进行调用表达式之前,我们需要一些东西可以调用,因此我们先进行函数声明。该 fun 以关键字开头。
static void declaration() {
在 declaration() 中。
替换 1 行
if (match(TOKEN_FUN)) { funDeclaration(); } else if (match(TOKEN_VAR)) {
varDeclaration();
这将控制权传递到此处。
在 block() 之后添加。
static void funDeclaration() { uint8_t global = parseVariable("Expect function name."); markInitialized(); function(TYPE_FUNCTION); defineVariable(global); }
函数是一等值,函数声明只是创建一个函数并将其存储在一个新声明的变量中。因此,我们像解析任何其他变量声明一样解析名称。顶级函数声明将函数绑定到全局变量。在块或其他函数内部,函数声明创建一个局部变量。
在前面的一章中,我解释了变量如何分两个阶段定义。这确保了您无法在变量自己的初始化器内部访问变量的值。这将很糟糕,因为变量还没有值。
函数不存在此问题。函数在其主体内部引用其自身名称是安全的。在完全定义函数之前,您无法调用函数并执行其主体,因此您永远不会看到变量处于未初始化状态。实际上,为了支持递归局部函数,允许这样做是有用的。
为了使它起作用,我们将在编译名称后立即将函数声明的变量标记为“已初始化”,然后再编译主体。这样,就可以在主体内部引用该名称,而不会产生错误。
不过,我们确实需要进行一项检查。
static void markInitialized() {
在 markInitialized() 中。
if (current->scopeDepth == 0) return;
current->locals[current->localCount - 1].depth =
以前,我们只在知道自己处于局部作用域时才调用 markInitialized()。现在,顶级函数声明也会调用此函数。当这种情况发生时,没有局部变量需要标记为已初始化—该函数绑定到全局变量。
接下来,我们编译函数本身—它的参数列表和块主体。为此,我们使用一个单独的辅助函数。该辅助函数生成将生成的函数对象留在堆栈顶部的代码。之后,我们调用 defineVariable() 将该函数存储回我们为其声明的变量中。
我将编译参数和主体的代码拆分为单独的代码,因为我们将在以后重用它来解析类内部的方法声明。让我们逐步构建它,从以下内容开始。
在 block() 之后添加。
static void function(FunctionType type) { Compiler compiler; initCompiler(&compiler, type); beginScope(); consume(TOKEN_LEFT_PAREN, "Expect '(' after function name."); consume(TOKEN_RIGHT_PAREN, "Expect ')' after parameters."); consume(TOKEN_LEFT_BRACE, "Expect '{' before function body."); block(); ObjFunction* function = endCompiler(); emitBytes(OP_CONSTANT, makeConstant(OBJ_VAL(function))); }
现在,我们不会担心参数。我们解析一对空括号,然后解析主体。主体以左大括号开头,我们在此解析它。然后,我们调用现有的 block() 函数,该函数知道如何编译块的其余部分,包括右大括号。
24 . 4 . 1编译器堆栈
有趣的部分是顶部的编译器内容和底部的编译器内容。Compiler 结构存储数据,例如哪些槽由哪些局部变量拥有,当前有多少个嵌套块等。所有这些都是特定于单个函数的。但现在前端需要处理在每个函数中彼此嵌套的多个函数的编译。
管理此问题的诀窍是为每个要编译的函数创建一个单独的编译器。当我们开始编译函数声明时,我们在 C 堆栈上创建一个新的编译器并对其进行初始化。initCompiler() 将该编译器设置为当前编译器。然后,在我们编译主体时,所有发出字节码的函数都写入新编译器函数拥有的 chunk 中。
在到达函数块主体的末尾后,我们调用 endCompiler()。这将产生新编译的函数对象,我们将该对象存储为周围函数的常量表中的一个常量。但是,等等,我们如何回到周围的函数?我们在 initCompiler() 覆盖当前编译器指针时丢失了它。
我们通过将一系列嵌套的 Compiler 结构视为堆栈来解决这个问题。与 VM 中的 Value 和 CallFrame 堆栈不同,我们不会使用数组。相反,我们使用链表。每个编译器都指向包围它的函数的编译器,一直回到顶级代码的根编译器。
} FunctionType;
在枚举 FunctionType 之后添加。
替换 1 行
typedef struct Compiler { struct Compiler* enclosing;
ObjFunction* function;
在 Compiler 结构内部,我们无法引用 Compiler typedef,因为该声明尚未完成。相反,我们给结构本身命名,并将其用于字段的类型。C 很奇怪。
在初始化一个新的编译器时,我们在该指针中捕获了即将不再是当前编译器的编译器。
static void initCompiler(Compiler* compiler, FunctionType type) {
在 initCompiler() 中
compiler->enclosing = current;
compiler->function = NULL;
然后,当一个编译器完成时,它通过将之前的编译器恢复为新的当前编译器,将其自身从堆栈中弹出。
#endif
在 endCompiler() 中
current = current->enclosing;
return function;
请注意,我们甚至不需要动态地分配 Compiler 结构。每个结构都存储为 C 堆栈中的一个局部变量—无论是在 compile() 中还是在 function() 中。Compiler 的链表贯穿 C 堆栈。我们能够获得无限数量的链表的原因是我们的编译器使用递归下降,因此当您有嵌套函数声明时,function() 最终会递归地调用自身。
24 . 4 . 2函数参数
如果您无法向函数传递参数,那么函数就没有多大用处,因此让我们接下来做参数。
consume(TOKEN_LEFT_PAREN, "Expect '(' after function name.");
在 function() 中。
if (!check(TOKEN_RIGHT_PAREN)) { do { current->function->arity++; if (current->function->arity > 255) { errorAtCurrent("Can't have more than 255 parameters."); } uint8_t constant = parseVariable("Expect parameter name."); defineVariable(constant); } while (match(TOKEN_COMMA)); }
consume(TOKEN_RIGHT_PAREN, "Expect ')' after parameters.");
语义上,参数只是一个在函数主体最外层词法作用域中声明的局部变量。我们使用现有的编译器支持来声明命名局部变量来解析和编译参数。与具有初始化器的局部变量不同,这里没有初始化参数值的代码。我们将在进行函数调用的参数传递时看到它们是如何初始化的。
趁我们现在还在讨论这个,我们通过计算解析了多少参数来记录函数的 arity。我们与函数一起存储的另一个元数据是它的名称。在编译函数声明时,我们会在解析函数名称后立即调用 initCompiler()。这意味着我们可以立即从前一个令牌中获取名称。
current = compiler;
在 initCompiler() 中
if (type != TYPE_SCRIPT) { current->function->name = copyString(parser.previous.start, parser.previous.length); }
Local* local = ¤t->locals[current->localCount++];
请注意,我们小心地创建了名称字符串的副本。请记住,lexeme 直接指向原始源代码字符串。该字符串可能在代码完成编译后被释放。我们在编译器中创建的函数对象比编译器存活时间更长,并持续到运行时。因此,它需要自己的堆分配名称字符串,它可以保留该字符串。
太棒了。现在我们可以编译函数声明,如下所示。
fun areWeHavingItYet() { print "Yes we are!"; } print areWeHavingItYet;
我们只是无法用它们做任何有用的事情。
24 . 5函数调用
在本节结束时,我们将开始看到一些有趣的行为。下一步是调用函数。我们通常不会这样想,但函数调用表达式有点像中缀 ( 运算符。在左侧,您有一个高优先级表达式,用于表示要调用的东西—通常只是一个标识符。然后是中间的 (,后面是逗号分隔的参数表达式,最后是 ),用于在末尾将其包装起来。
这种奇怪的语法视角解释了如何将语法挂钩到我们的解析表中。
ParseRule rules[] = {
在 unary() 之后添加。
替换 1 行
[TOKEN_LEFT_PAREN] = {grouping, call, PREC_CALL},
[TOKEN_RIGHT_PAREN] = {NULL, NULL, PREC_NONE},
当解析器在表达式后面遇到左括号时,它会调度到一个新的解析器函数。
在 binary() 之后添加。
static void call(bool canAssign) { uint8_t argCount = argumentList(); emitBytes(OP_CALL, argCount); }
我们已经消耗了(标记,所以接下来我们将使用单独的argumentList()辅助函数来编译参数。该函数返回它编译的参数数量。每个参数表达式都会生成代码,将它的值放在栈上,为调用做准备。之后,我们发出一个新的OP_CALL指令来调用函数,使用参数计数作为操作数。
我们使用这个朋友编译参数
在defineVariable()之后添加
static uint8_t argumentList() { uint8_t argCount = 0; if (!check(TOKEN_RIGHT_PAREN)) { do { expression(); argCount++; } while (match(TOKEN_COMMA)); } consume(TOKEN_RIGHT_PAREN, "Expect ')' after arguments."); return argCount; }
这段代码应该和 jlox 中的代码很像。我们一直咀嚼参数,直到我们在每个表达式之后找到逗号为止。一旦我们用完逗号,我们就消耗掉最后的右括号,就完成了。
嗯,几乎完成了。回到 jlox,我们添加了一个编译时检查,以确保你不会向调用传递超过 255 个参数。当时,我说那是因为 clox 会需要类似的限制。现在你可以看到为什么—因为我们将参数计数塞入字节码作为一个单字节操作数,我们只能达到 255。我们需要在这个编译器中也验证这一点。
expression();
在argumentList()中
if (argCount == 255) { error("Can't have more than 255 arguments."); }
argCount++;
这就是前端。让我们跳到后端,在中间快速停一下来声明新的指令。
OP_LOOP,
在枚举OpCode中
OP_CALL,
OP_RETURN,
24 . 5 . 1将参数绑定到形参
在我们开始实现之前,我们应该思考一下调用时的栈是什么样的,以及我们需要从那里做什么。当我们到达调用指令时,我们已经执行了被调用函数的表达式,以及它的参数。假设我们的程序如下所示
fun sum(a, b, c) { return a + b + c; } print 4 + sum(5, 6, 7);
如果我们在对sum()的调用中暂停 VM,正好在OP_CALL指令上,栈看起来像这样

从sum()本身的角度来想象一下。当编译器编译sum()时,它会自动分配插槽零。然后,在那之后,它会为形参a、b和c分配局部插槽,按顺序排列。为了执行对sum()的调用,我们需要用被调用的函数和它可以使用的一块栈插槽区域来初始化一个CallFrame。然后我们需要收集传递给函数的参数,并将它们放入对应形参的插槽中。
当 VM 开始执行sum()的主体时,我们希望它的栈窗口看起来像这样
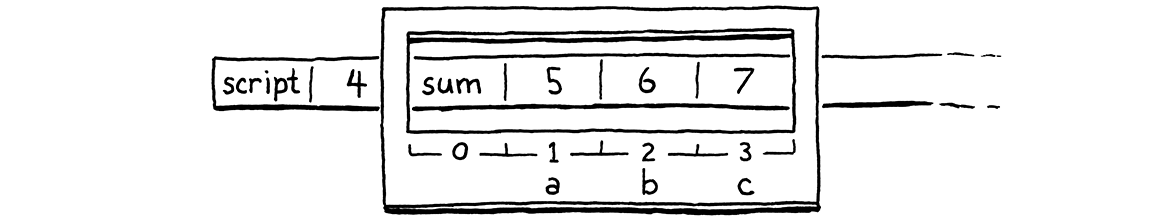
你有没有注意到,调用者设置的实参插槽和被调用者需要的形参插槽都处于完全正确的顺序?多么方便!这不是巧合。当我谈到每个CallFrame都有它自己的栈窗口时,我从来没有说过这些窗口必须是不相交的。没有什么能够阻止我们像这样重叠它们
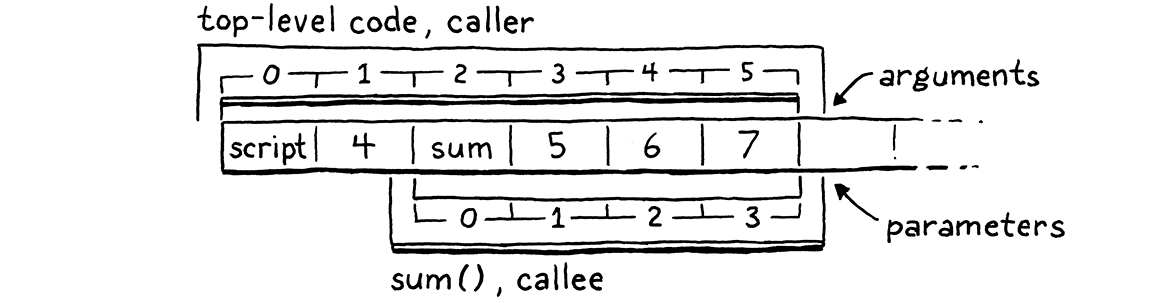
The调用者栈的顶部包含被调用的函数,后面是按顺序排列的实参。我们知道调用者在这些插槽之上没有其他正在使用的插槽,因为评估实参表达式时需要的任何临时值现在都被丢弃了。被调用者栈的底部重叠,以便形参插槽与实参值所在的地址完全对齐。
这意味着我们不需要做任何工作来“将实参绑定到形参”。没有在插槽之间或跨环境复制值。实参已经精确地位于它们应该在的位置。很难在性能上超过这一点。
现在该实现调用指令了。
}
在 run() 中
case OP_CALL: { int argCount = READ_BYTE(); if (!callValue(peek(argCount), argCount)) { return INTERPRET_RUNTIME_ERROR; } break; }
case OP_RETURN: {
我们需要知道被调用的函数以及传递给它的参数数量。我们从指令的操作数中获取后者。这也告诉我们从栈顶经过实参插槽后在哪里找到函数。我们将这些数据传递给一个单独的callValue()函数。如果该函数返回false,则表示调用导致某种运行时错误。当这种情况发生时,我们将中止解释器。
如果callValue()成功,将会有一个新的框架出现在被调用函数的CallFrame栈上。run()函数有它自己的缓存指针指向当前框架,所以我们需要更新它。
return INTERPRET_RUNTIME_ERROR;
}
在 run() 中
frame = &vm.frames[vm.frameCount - 1];
break;
由于字节码分派循环从该frame变量中读取,所以当 VM 去执行下一条指令时,它将从新调用的函数的CallFrame中读取ip,并跳转到它的代码。执行该调用的工作从这里开始
在peek()之后添加
static bool callValue(Value callee, int argCount) { if (IS_OBJ(callee)) { switch (OBJ_TYPE(callee)) { case OBJ_FUNCTION: return call(AS_FUNCTION(callee), argCount); default: break; // Non-callable object type. } } runtimeError("Can only call functions and classes."); return false; }
这里发生了的事情不仅仅是初始化一个新的CallFrame。因为 Lox 是动态类型的,所以没有什么能阻止用户编写像这样的错误代码
var notAFunction = 123; notAFunction();
如果发生这种情况,运行时需要安全地报告错误并停止。所以我们做的第一件事是检查我们尝试调用的值的类型。如果不是函数,我们就出错。否则,实际调用将发生在这里
在peek()之后添加
static bool call(ObjFunction* function, int argCount) { CallFrame* frame = &vm.frames[vm.frameCount++]; frame->function = function; frame->ip = function->chunk.code; frame->slots = vm.stackTop - argCount - 1; return true; }
这只是在栈上初始化下一个CallFrame。它存储指向被调用的函数的指针,并将框架的ip指向函数的字节码的开头。最后,它设置slots指针,为框架提供它自己的栈窗口。那里的算术运算确保栈上的实参与函数的形参对齐
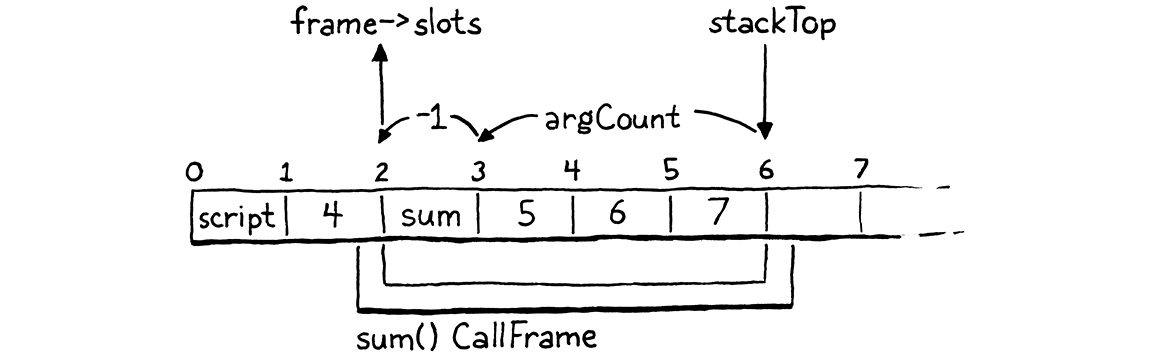
有趣的小- 1是为了解决编译器为我们以后添加方法而保留的栈插槽零。形参从插槽一开始,所以我们将窗口的起始位置提前一个插槽,使它们与实参对齐。
在我们继续之前,让我们将新的指令添加到反汇编器中。
return jumpInstruction("OP_LOOP", -1, chunk, offset);
在disassembleInstruction()中
case OP_CALL: return byteInstruction("OP_CALL", chunk, offset);
case OP_RETURN:
再做一个简短的旁路。既然我们有一个方便的函数来启动CallFrame,我们不妨用它来设置执行顶级代码的第一个框架。
push(OBJ_VAL(function));
在 interpret() 中。
替换 4 行
call(function, 0);
return run();
好的,现在回到调用 . . .
24 . 5 . 2运行时错误检查
重叠的栈窗口的工作原理是基于这样的假设:一个调用为函数的每个形参传递一个实参。但是,再次强调,因为 Lox 不是静态类型的,所以一个愚蠢的用户可能会传递太多或太少的参数。在 Lox 中,我们已经定义了这将是一个运行时错误,我们像这样报告它
static bool call(ObjFunction* function, int argCount) {
在call()中
if (argCount != function->arity) { runtimeError("Expected %d arguments but got %d.", function->arity, argCount); return false; }
CallFrame* frame = &vm.frames[vm.frameCount++];
非常直截了当。这就是为什么我们将每个函数的元数存储在它的ObjFunction内部。
我们还需要报告另一个错误,这个错误与用户的愚蠢行为关系不大,而更多的是与我们自己的问题有关。因为CallFrame数组的大小是固定的,所以我们需要确保深层调用链不会溢出它。
}
在call()中
if (vm.frameCount == FRAMES_MAX) { runtimeError("Stack overflow."); return false; }
CallFrame* frame = &vm.frames[vm.frameCount++];
在实践中,如果一个程序接近这个限制,那么它很可能是在某个失控的递归代码中存在 bug。
24 . 5 . 3打印栈跟踪
既然我们谈到了运行时错误,让我们花一点时间使它们更有用。在运行时错误上停止对于防止 VM 以某种无法定义的方式崩溃和烧毁至关重要。但仅仅中止并不能帮助用户修复导致该错误的代码。
帮助调试运行时故障的经典工具是栈跟踪—打印出程序崩溃时仍在执行的每个函数,以及程序崩溃时的执行位置。现在我们有了调用栈,并且方便地存储了每个函数的名称,我们可以在运行时错误破坏用户存在的和谐时显示整个栈。它看起来像这样
fputs("\n", stderr);
在 runtimeError() 中。
替换 4 行
for (int i = vm.frameCount - 1; i >= 0; i--) { CallFrame* frame = &vm.frames[i]; ObjFunction* function = frame->function; size_t instruction = frame->ip - function->chunk.code - 1; fprintf(stderr, "[line %d] in ", function->chunk.lines[instruction]); if (function->name == NULL) { fprintf(stderr, "script\n"); } else { fprintf(stderr, "%s()\n", function->name->chars); } }
resetStack(); }
在打印错误消息本身之后,我们从top(最近调用的函数)到底部(顶级代码)遍历调用栈。对于每个框架,我们找到对应于当前ip的该框架函数中的行号。然后,我们打印该行号以及函数名称。
例如,如果你运行这个错误的程序
fun a() { b(); } fun b() { c(); } fun c() { c("too", "many"); } a();
它会打印出
Expected 0 arguments but got 2. [line 4] in c() [line 2] in b() [line 1] in a() [line 7] in script
看起来还不错,对吧?
24 . 5 . 4从函数返回
我们越来越接近了。我们可以调用函数,VM 会执行它们。但是我们还不能从它们中返回。我们已经有一段时间拥有OP_RETURN指令了,但它总是有一些临时的代码挂在里面,只是为了让我们退出字节码循环。现在该进行真正的实现了。
case OP_RETURN: {
在 run() 中
替换 2 行
Value result = pop(); vm.frameCount--; if (vm.frameCount == 0) { pop(); return INTERPRET_OK; } vm.stackTop = frame->slots; push(result); frame = &vm.frames[vm.frameCount - 1]; break;
}
当一个函数返回值时,该值将在栈顶。我们即将丢弃被调用函数的整个栈窗口,所以我们弹出返回值并保存它。然后我们丢弃返回函数的CallFrame。如果这是最后一个CallFrame,则表示我们已经完成执行顶级代码。整个程序都完成了,所以我们从栈中弹出主脚本函数,然后退出解释器。
否则,我们丢弃被调用者用于其形参和局部变量的所有插槽。这包括调用者用于传递实参的相同插槽。既然调用已经完成,调用者不再需要它们了。这意味着栈顶最终会正好位于返回函数的栈窗口的开头。
我们将返回值推回栈上,位于新的、更低的位置。然后我们更新run()函数的缓存指针指向当前框架。就像我们开始调用时一样,在字节码分派循环的下一轮迭代中,VM 将从该框架中读取ip,执行将跳回调用者,回到它离开的地方,正好在OP_CALL指令之后。
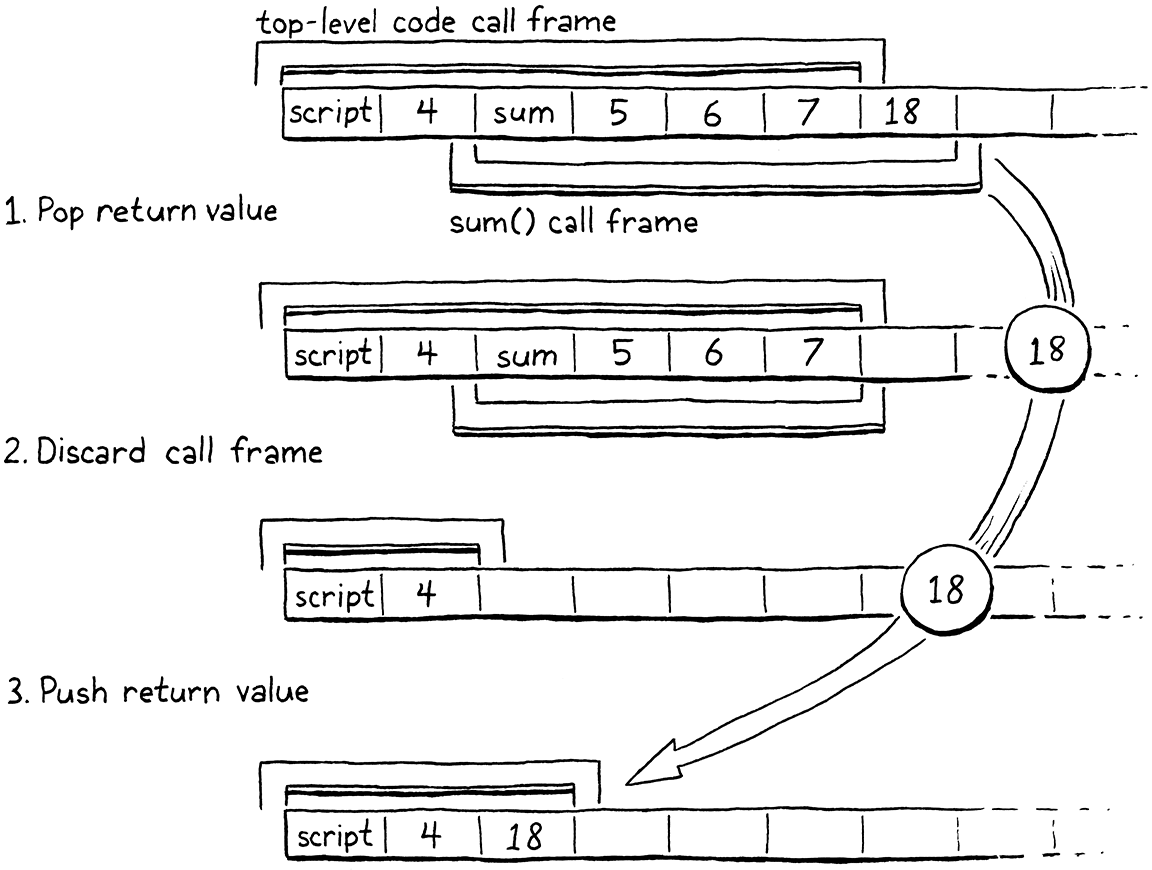
请注意,我们这里假设函数确实返回了一个值,但函数可以通过到达其主体末尾来隐式返回
fun noReturn() { print "Do stuff"; // No return here. } print noReturn(); // ???
我们还需要正确处理这种情况。该语言被指定在这种情况下隐式返回nil。为了实现这一点,我们添加了这个
static void emitReturn() {
在emitReturn()中
emitByte(OP_NIL);
emitByte(OP_RETURN); }
编译器调用emitReturn()来在函数体末尾写入OP_RETURN指令。现在,在此之前,它发出一个指令将nil推到栈上。这样,我们就有了工作的函数调用!它们甚至可以接受参数!看起来我们几乎知道自己在做什么。
24 . 6返回语句
如果你想要一个返回非隐式nil值的函数,你需要一个return语句。让我们让它工作起来。
ifStatement();
在statement()中
} else if (match(TOKEN_RETURN)) { returnStatement();
} else if (match(TOKEN_WHILE)) {
当编译器看到一个return关键字时,它会到这里
在 printStatement() 后添加
static void returnStatement() { if (match(TOKEN_SEMICOLON)) { emitReturn(); } else { expression(); consume(TOKEN_SEMICOLON, "Expect ';' after return value."); emitByte(OP_RETURN); } }
返回值表达式是可选的,因此解析器会查找分号标记来判断是否提供了值。如果没有返回值,该语句会隐式返回 nil。我们通过调用 emitReturn() 来实现这一点,它会发出 OP_NIL 指令。否则,我们会编译返回值表达式并使用 OP_RETURN 指令将其返回。
这是我们之前已经实现的同一个 OP_RETURN 指令—我们不需要任何新的运行时代码。这与 jlox 有很大不同。在 jlox 中,我们必须使用异常来在执行 return 语句时展开堆栈。这是因为你可以在一些嵌套块内部返回。由于 jlox 递归地遍历 AST,这意味着我们需要从许多 Java 方法调用中跳出。
我们的字节码编译器将所有这些都扁平化了。我们在解析期间执行递归下降,但在运行时,VM 的字节码调度循环是完全扁平的。在 C 级别没有任何递归发生。因此,即使在某些嵌套块内部返回,也与从函数主体末尾返回一样简单。
不过,我们还没有完全完成。新的 return 语句给我们带来了一个新的编译错误需要担心。返回对于从函数中返回很有用,但 Lox 程序的顶层也是命令式代码。你不能从那里 return。
return "What?!";
我们已经指定,在任何函数之外都有 return 语句是一个编译错误,我们通过以下方式实现
static void returnStatement() {
在 returnStatement() 中
if (current->type == TYPE_SCRIPT) { error("Can't return from top-level code."); }
if (match(TOKEN_SEMICOLON)) {
这是我们向编译器添加 FunctionType 枚举的原因之一。
24 . 7原生函数
我们的 VM 正在变得越来越强大。我们有了函数、调用、参数、返回值。你可以定义许多不同的函数,它们可以以有趣的方式相互调用。但是,最终,它们实际上什么也做不了。Lox 程序唯一可以做到的用户可见的事情,无论其复杂程度如何,都是打印。要添加更多功能,我们需要将它们公开给用户。
编程语言实现通过原生函数来接触和触碰物质世界。如果你想要编写可以检查时间、读取用户输入或访问文件系统的程序,我们需要添加原生函数—从 Lox 中调用但用 C 实现—来公开这些功能。
在语言层面上,Lox 已经相当完整—它有闭包、类、继承和其他有趣的东西。它感觉像是一种玩具语言的原因之一是它几乎没有原生功能。我们可以通过添加很长一段原生功能来将其变成真正的语言。
然而,磨练一堆操作系统操作实际上并没有什么教育意义。一旦你了解了如何将一段 C 代码绑定到 Lox,你就明白了。但你需要看一个,即使是一个单独的原生函数也需要我们构建所有用于将 Lox 与 C 连接起来的机制。所以我们会完成它,并完成所有艰苦的工作。然后,当完成之后,我们会添加一个很小的原生函数来证明它能工作。
我们需要新机制的原因是,从实现的角度来看,原生函数与 Lox 函数不同。当它们被调用时,它们不会推送 CallFrame,因为没有字节码代码供该帧指向。它们没有字节码块。相反,它们以某种方式引用了一段原生 C 代码。
我们在 clox 中通过将原生函数定义为完全不同的对象类型来处理这个问题。
} ObjFunction;
在 struct ObjFunction 后添加
typedef Value (*NativeFn)(int argCount, Value* args); typedef struct { Obj obj; NativeFn function; } ObjNative;
struct ObjString {
该表示比 ObjFunction 更简单—仅仅是 Obj 头部和一个指向实现原生行为的 C 函数的指针。原生函数接受参数数量和指向堆栈上第一个参数的指针。它通过该指针访问参数。完成之后,它会返回结果值。
与往常一样,新的对象类型会带有一些附属物。要创建一个 ObjNative,我们需要声明一个类似构造函数的函数。
ObjFunction* newFunction();
在 newFunction() 后添加
ObjNative* newNative(NativeFn function);
ObjString* takeString(char* chars, int length);
我们通过以下方式实现它
在 newFunction() 后添加
ObjNative* newNative(NativeFn function) { ObjNative* native = ALLOCATE_OBJ(ObjNative, OBJ_NATIVE); native->function = function; return native; }
构造函数接受一个 C 函数指针,将其包装在 ObjNative 中。它设置对象头部并存储该函数。对于头部,我们需要一个新的对象类型。
typedef enum {
OBJ_FUNCTION,
在 enum ObjType 中
OBJ_NATIVE,
OBJ_STRING, } ObjType;
VM 还需要知道如何释放原生函数对象。
}
在 freeObject() 中
case OBJ_NATIVE: FREE(ObjNative, object); break;
case OBJ_STRING: {
这里没什么内容,因为 ObjNative 不会拥有任何额外的内存。所有 Lox 对象支持的另一个功能是可以打印。
break;
在 printObject() 中
case OBJ_NATIVE: printf("<native fn>"); break;
case OBJ_STRING:
为了支持动态类型,我们有一个宏来检查值是否为原生函数。
#define IS_FUNCTION(value) isObjType(value, OBJ_FUNCTION)
#define IS_NATIVE(value) isObjType(value, OBJ_NATIVE)
#define IS_STRING(value) isObjType(value, OBJ_STRING)
假设返回 true,这个宏会从表示原生函数的 Value 中提取 C 函数指针
#define AS_FUNCTION(value) ((ObjFunction*)AS_OBJ(value))
#define AS_NATIVE(value) \ (((ObjNative*)AS_OBJ(value))->function)
#define AS_STRING(value) ((ObjString*)AS_OBJ(value))
所有这些负担让 VM 可以像对待任何其他对象一样对待原生函数。你可以将它们存储在变量中,传递它们,为它们举办生日派对等等。当然,我们真正关心的操作是调用它们—在调用表达式中使用它作为左操作数。
在 callValue() 中,我们添加了另一种类型情况。
case OBJ_FUNCTION:
return call(AS_FUNCTION(callee), argCount);
在 callValue() 中
case OBJ_NATIVE: { NativeFn native = AS_NATIVE(callee); Value result = native(argCount, vm.stackTop - argCount); vm.stackTop -= argCount + 1; push(result); return true; }
default:
如果被调用的对象是原生函数,我们会立即调用 C 函数。不需要处理 CallFrame 或者其他任何东西。我们只需要将它交给 C,获取结果,然后将其放回堆栈。这使得原生函数的速度尽可能快。
有了这个,用户应该可以调用原生函数,但是还没有可以调用的函数。如果没有类似于外部函数接口的东西,用户就不能定义自己的原生函数。这是我们作为 VM 实现者的工作。我们会从一个帮助程序开始,用来定义公开给 Lox 程序的新原生函数。
在 runtimeError() 后添加
static void defineNative(const char* name, NativeFn function) { push(OBJ_VAL(copyString(name, (int)strlen(name)))); push(OBJ_VAL(newNative(function))); tableSet(&vm.globals, AS_STRING(vm.stack[0]), vm.stack[1]); pop(); pop(); }
它接受一个指向 C 函数的指针和它在 Lox 中的名称。我们将该函数包装在一个 ObjNative 中,然后将其存储在一个具有给定名称的全局变量中。
你可能想知道为什么我们要将名称和函数推入和弹出堆栈。这看起来很奇怪,对吧?这是在涉及 垃圾 收集时你需要担心的东西。copyString() 和 newNative() 都会动态分配内存。这意味着一旦我们有了 GC,它们就有可能触发收集。如果发生这种情况,我们需要确保收集器知道我们还没有完成对名称和 ObjFunction 的操作,这样它就不会从我们手中释放它们。将它们存储在值堆栈上就可以做到这一点。
这感觉很傻,但完成所有这些工作之后,我们只打算添加一个很小的原生函数。
在变量 vm 后添加
static Value clockNative(int argCount, Value* args) { return NUMBER_VAL((double)clock() / CLOCKS_PER_SEC); }
这会返回程序开始运行以来的经过时间,单位是秒。它对于基准测试 Lox 程序非常有用。在 Lox 中,我们将其命名为 clock()。
initTable(&vm.strings);
在 initVM() 中
defineNative("clock", clockNative);
}
为了使用 C 标准库中的 clock() 函数,“vm” 模块需要一个包含文件。
#include <string.h>
#include <time.h>
#include "common.h"
这些内容很多,但我们做到了!输入以下内容并试一试
fun fib(n) { if (n < 2) return n; return fib(n - 2) + fib(n - 1); } var start = clock(); print fib(35); print clock() - start;
我们可以编写一个非常低效的递归斐波那契函数。更棒的是,我们可以衡量它的低效程度。当然,这不是计算斐波那契数的最聪明的方法。但它是一个很好的方法,可以对语言实现对函数调用的支持进行压力测试。在我的机器上,在 clox 中运行它比在 jlox 中运行快大约五倍。这是一个很大的改进。
挑战
-
读取和写入
ip字段是字节码循环中最频繁的操作之一。现在,我们通过指向当前 CallFrame 的指针访问它。这需要指针间接访问,这可能会迫使 CPU 绕过缓存并访问主内存。这可能是一个真正的性能瓶颈。理想情况下,我们应该将
ip保存在本地 CPU 寄存器中。C 不允许我们强制这样做,除非使用内联汇编,但我们可以对代码进行结构化以鼓励编译器进行这种优化。如果我们将ip直接存储在 C 局部变量中并将其标记为register,那么 C 编译器很有可能同意我们的请求。这意味着我们需要小心,在开始和结束函数调用时将局部
ip加载和存储回正确的 CallFrame。实现这个优化。编写几个基准测试,看看它对性能的影响。你认为额外的代码复杂度值得吗? -
原生函数调用速度快部分是因为我们没有验证调用是否传递了与函数期望的参数数量相同的参数。我们确实应该这样做,否则对原生函数的错误调用(没有足够参数)会导致函数读取未初始化的内存。添加参数检查。
-
现在,原生函数没有办法发出运行时错误。在真实的实现中,我们需要支持这一点,因为原生函数存在于 C 的静态类型世界中,但它们是从动态类型 Lox 世界中调用的。如果用户,比如,尝试将字符串传递给
sqrt(),那么该原生函数需要报告运行时错误。扩展原生函数系统以支持这一点。这种功能如何影响原生调用的性能?
-
添加一些更有用的原生函数。编写一些使用这些函数的程序。你添加了什么?它们如何影响语言的感受以及其实用性?