来回跳跃
我们脑海中想象的顺序就像一张网,或是一把梯子,是为了达到某种目的而构建的。但后来你必须扔掉梯子,因为你发现,即使它有用,它也是毫无意义的。
翁贝托·艾柯,玫瑰的名字
我们花了很长时间才走到这一步,但我们终于准备好为我们的虚拟机添加控制流了。在为 jlox 构建的树遍历解释器中,我们用 Java 的控制流实现了 Lox 的控制流。为了执行 Lox 的 if 语句,我们使用 Java 的 if 语句来运行选定的分支。这行得通,但并不完全令人满意。JVM 本身或原生 CPU 是如何实现 if 语句的?现在我们有了自己的字节码 VM 可以用来搞,我们可以回答这个问题了。
当我们谈论“控制流”时,我们指的是什么?我们所说的“流”指的是程序执行过程中在程序文本中的移动方式。就好像计算机内部有一个小机器人,在我们的代码中来回穿梭,执行这里那里的代码片段。流就是机器人所走的路径,而通过控制机器人,我们就可以驱动它执行哪些代码片段。
在 jlox 中,机器人的关注点—当前的代码片段—是隐式的,它基于存储在各种 Java 变量中的 AST 节点以及我们正在运行的 Java 代码。在 clox 中,它就明确得多了。VM 的 ip 字段存储当前字节码指令的地址。该字段的值就是“我们所在的位置”。
执行过程通常通过递增 ip 来进行。但是,我们可以随意修改这个变量。为了实现控制流,只需要以更有趣的方式更改 ip 即可。最简单的控制流结构是没有任何 else 子句的 if 语句
if (condition) print("condition was truthy");
VM 会评估条件表达式的字节码。如果结果为真值,那么它会继续执行,并执行主体中的 print 语句。有趣的情况是当条件为假值时。在这种情况下,执行会跳过 then 分支,并继续执行下一条语句。
为了跳过一段代码,我们只需将 ip 字段设置为该代码之后字节码指令的地址。为了有条件地跳过一些代码,我们需要一条指令,它会查看堆栈顶部的值。如果它是假值,则它会将给定的偏移量添加到 ip 中,以跳过一系列指令。否则,它将不执行任何操作,并让执行继续到下一条指令,就像往常一样。
当我们编译成字节码时,代码中显式的嵌套块结构会消失,只剩下一个扁平的指令序列。Lox 是一种结构化编程语言,但 clox 字节码不是。正确的—或错误的,这取决于你的看法—字节码指令集可以跳到一个块的中间,或者从一个作用域跳到另一个作用域。
VM 会很乐意执行这些操作,即使结果会导致堆栈处于未知的、不一致的状态。因此,尽管字节码是无结构的,但我们会注意确保我们的编译器只生成干净的代码,这些代码会维护与 Lox 本身相同的结构和嵌套。
这正是真实 CPU 的行为方式。即使我们可能使用强制结构化控制流的高级语言来对它们进行编程,编译器也会将其降低到原始跳转。在底层,事实证明 goto 是唯一的真实控制流。
无论如何,我无意变得哲学化。重要的是,如果我们拥有那个有条件的跳转指令,就足以实现 Lox 的 if 语句,只要它没有 else 子句。所以让我们开始着手去做吧。
23 . 1 if 语句
经过这么多章,你应该知道怎么做。任何新功能都从前端开始,然后逐步通过管道。if 语句,嗯,是一个语句,所以我们要把它挂接到解析器上。
if (match(TOKEN_PRINT)) {
printStatement();
在 statement() 中
} else if (match(TOKEN_IF)) { ifStatement();
} else if (match(TOKEN_LEFT_BRACE)) {
当我们看到 if 关键字时,我们会将编译工作交由这个函数处理
添加在 expressionStatement() 之后
static void ifStatement() { consume(TOKEN_LEFT_PAREN, "Expect '(' after 'if'."); expression(); consume(TOKEN_RIGHT_PAREN, "Expect ')' after condition."); int thenJump = emitJump(OP_JUMP_IF_FALSE); statement(); patchJump(thenJump); }
首先,我们编译条件表达式,用括号括起来。在运行时,这会将条件值留在堆栈顶部。我们将用它来确定是执行 then 分支还是跳过它。
然后,我们发出一个新的 OP_JUMP_IF_FALSE 指令。它有一个操作数,用于指定要偏移 ip 的距离—要跳过的字节码数量。如果条件为假值,它会将 ip 调整相应的值。类似于这样
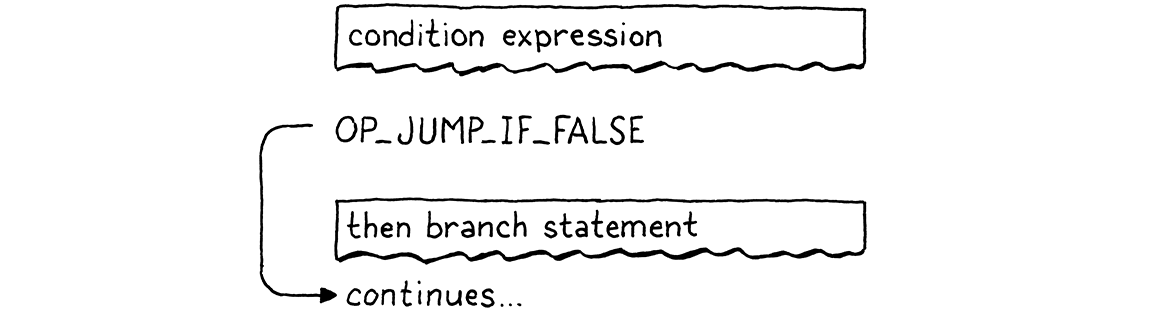
但是我们遇到了一个问题。当我们编写 OP_JUMP_IF_FALSE 指令的操作数时,我们怎么知道要跳多远?我们还没有编译 then 分支,所以我们不知道它包含多少字节码。
为了解决这个问题,我们使用一个经典技巧,称为回填。我们先发出跳转指令,并为跳转偏移量操作数设置一个占位符。我们会记录这个半成品指令的位置。接下来,我们编译 then 分支。完成之后,我们就知道要跳多远了。因此,我们回去用真实的值替换那个占位符偏移量,因为现在我们可以计算它了。有点像把补丁缝在已编译代码的现有织物上。

我们将这个技巧编码成两个辅助函数。
添加在 emitBytes() 之后
static int emitJump(uint8_t instruction) { emitByte(instruction); emitByte(0xff); emitByte(0xff); return currentChunk()->count - 2; }
第一个函数发出一个字节码指令,并为跳转偏移量操作数写入一个占位符。我们将操作码作为参数传递,因为稍后我们将有两个不同的指令使用这个辅助函数。我们使用两个字节来表示跳转偏移量操作数。一个 16 位的偏移量让我们可以跳过最多 65,535 字节的代码,这应该足够满足我们的需求了。
该函数返回已发出指令在块中的偏移量。编译完 then 分支后,我们将该偏移量传递给这个函数
添加在 emitConstant() 之后
static void patchJump(int offset) { // -2 to adjust for the bytecode for the jump offset itself. int jump = currentChunk()->count - offset - 2; if (jump > UINT16_MAX) { error("Too much code to jump over."); } currentChunk()->code[offset] = (jump >> 8) & 0xff; currentChunk()->code[offset + 1] = jump & 0xff; }
该函数回到字节码中,用计算出的跳转偏移量替换指定位置的操作数。我们会在发出我们想要跳转的下一条指令之前调用 patchJump(),因此它使用当前的字节码计数来确定要跳多远。对于 if 语句,这意味着我们在编译完 then 分支之后,但在编译下一条语句之前进行调用。
这就是我们编译时所需要做的全部工作。让我们定义新的指令。
OP_PRINT,
在枚举 OpCode 中
OP_JUMP_IF_FALSE,
OP_RETURN,
在 VM 中,我们这样实现它
break;
}
在 run() 中
case OP_JUMP_IF_FALSE: { uint16_t offset = READ_SHORT(); if (isFalsey(peek(0))) vm.ip += offset; break; }
case OP_RETURN: {
这是我们添加的第一条包含 16 位操作数的指令。为了从块中读取它,我们使用一个新的宏。
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
在 run() 中
#define READ_SHORT() \ (vm.ip += 2, (uint16_t)((vm.ip[-2] << 8) | vm.ip[-1]))
#define READ_STRING() AS_STRING(READ_CONSTANT())
它从块中提取接下来的两个字节,并用它们构建一个 16 位无符号整数。像往常一样,在完成宏的操作后,我们将清理它。
#undef READ_BYTE
在 run() 中
#undef READ_SHORT
#undef READ_CONSTANT
在读取偏移量之后,我们检查堆栈顶部的条件值。如果它是假值,我们将这个跳转偏移量应用到 ip 上。否则,我们保持 ip 不变,执行将自动继续到跳转指令之后的下一条指令。
如果条件为假值,我们不需要执行任何其他操作。我们已经偏移了 ip,因此当外部指令调度循环再次执行时,它将在那个新的指令处继续执行,跳过 then 分支中的所有代码。
请注意,跳转指令不会从堆栈中弹出条件值。因此,我们还没有完全完成,因为这会导致一个额外的值在堆栈中漂浮。我们很快就会清理它。暂时忽略这个问题,我们现在确实在 Lox 中实现了了一个有效的 if 语句,只需要一个简单的指令来在 VM 中支持它。
23 . 1 . 1 else 子句
没有 else 子句支持的 if 语句就像没有戈麦斯的莫蒂西亚·亚当斯。因此,在编译完 then 分支后,我们会查找 else 关键字。如果我们找到了它,我们会编译 else 分支。
patchJump(thenJump);
在 ifStatement() 中
if (match(TOKEN_ELSE)) statement();
}
当条件为假值时,我们会跳过 then 分支。如果有 else 分支,ip 将会落在它的代码开头。但这还不够。以下流程会导致
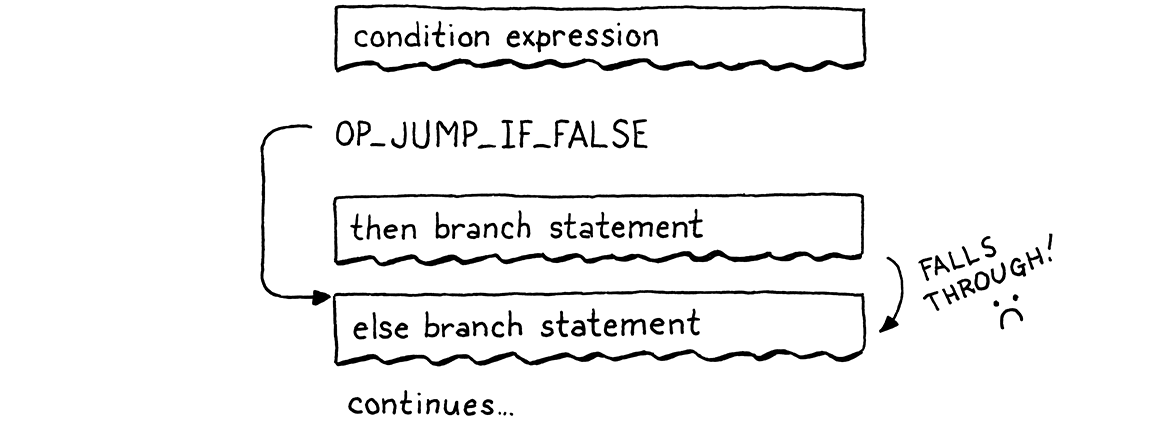
如果条件为真值,我们会像预期的那样执行 then 分支。但在那之后,执行会直接进入 else 分支。糟糕!当条件为真时,在我们运行完 then 分支后,我们需要跳过 else 分支。这样,无论哪种情况,我们都只执行一个分支,就像这样

要实现这一点,我们需要从 then 分支的末尾进行另一次跳转。
statement();
在 ifStatement() 中
int elseJump = emitJump(OP_JUMP);
patchJump(thenJump);
我们在 else 语句块的末尾修补该偏移量。
if (match(TOKEN_ELSE)) statement();
在 ifStatement() 中
patchJump(elseJump);
}
在执行 then 分支后,这将跳转到 else 分支后的下一条语句。与其他跳转不同,此跳转是无条件的。我们总是执行它,因此我们需要另一个指令来表达这一点。
OP_PRINT,
在枚举 OpCode 中
OP_JUMP,
OP_JUMP_IF_FALSE,
我们这样解释它
break;
}
在 run() 中
case OP_JUMP: { uint16_t offset = READ_SHORT(); vm.ip += offset; break; }
case OP_JUMP_IF_FALSE: {
这里没什么特别的—唯一的区别是它不检查条件,并且始终应用偏移量。
现在我们有了 then 和 else 分支,因此我们已经很接近了。最后一步是清理我们在堆栈上留下的那个条件值。请记住,每个语句都需要具有零堆栈效应—语句执行完成后,堆栈的高度应该与之前一样。
我们可以让 OP_JUMP_IF_FALSE 指令弹出条件本身,但很快我们将在逻辑运算符中使用相同的指令,而我们不希望弹出条件。相反,我们将让编译器在编译 if 语句时发出几个显式的 OP_POP 指令。我们需要确保通过生成的代码的每个执行路径都会弹出条件。
当条件为真时,我们在 then 分支内的代码之前弹出它。
int thenJump = emitJump(OP_JUMP_IF_FALSE);
在 ifStatement() 中
emitByte(OP_POP);
statement();
否则,我们在 else 分支的开头弹出它。
patchJump(thenJump);
在 ifStatement() 中
emitByte(OP_POP);
if (match(TOKEN_ELSE)) statement();
此处的这条小指令也意味着每个 if 语句都有一个隐式的 else 分支,即使用户没有编写 else 子句。在他们省略了 else 子句的情况下,该分支所做的只是丢弃条件值。
完整的正确流程如下
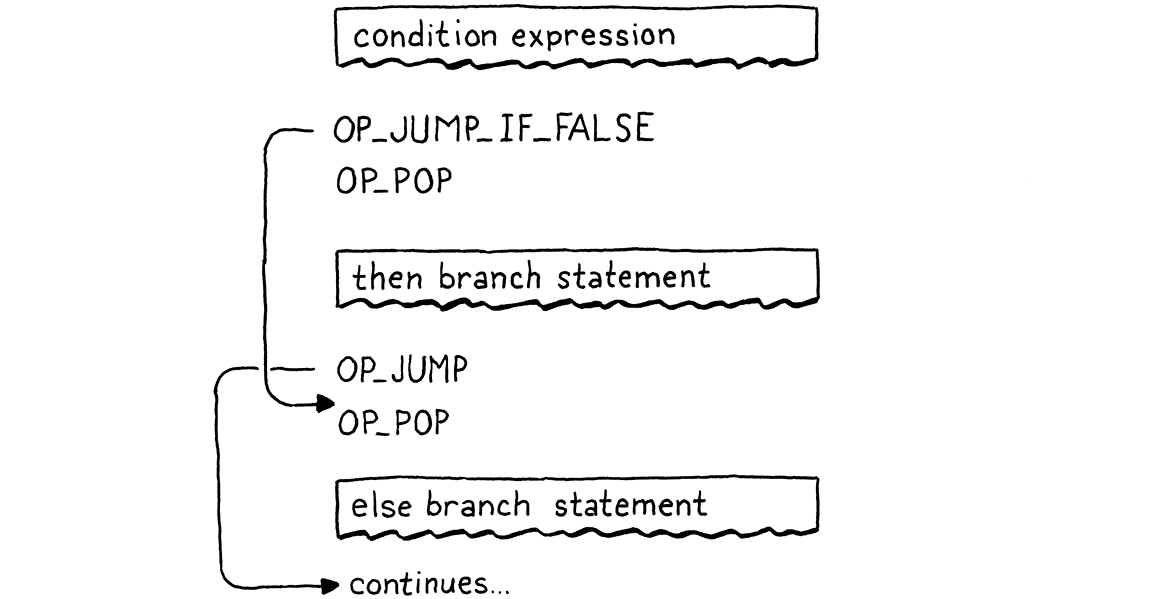
如果你跟踪一下,你会发现它总是执行一个分支,并确保首先弹出条件。剩下的只是一个小小的反汇编支持。
return simpleInstruction("OP_PRINT", offset);
在 disassembleInstruction() 中
case OP_JUMP: return jumpInstruction("OP_JUMP", 1, chunk, offset); case OP_JUMP_IF_FALSE: return jumpInstruction("OP_JUMP_IF_FALSE", 1, chunk, offset);
case OP_RETURN:
这两个指令使用新的格式,带有 16 位操作数,因此我们添加了一个新的实用函数来反汇编它们。
在 byteInstruction() 之后添加
static int jumpInstruction(const char* name, int sign, Chunk* chunk, int offset) { uint16_t jump = (uint16_t)(chunk->code[offset + 1] << 8); jump |= chunk->code[offset + 2]; printf("%-16s %4d -> %d\n", name, offset, offset + 3 + sign * jump); return offset + 3; }
好了,这就是一个完整的控制流结构。如果这是一部 80 年代的电影,蒙太奇音乐会响起,其余的控制流语法会自行解决。唉,80 年代已经过去很久了,所以我们必须自己动手。
23 . 2逻辑运算符
你可能还记得 jlox 中的这一点,但逻辑运算符 and 和 or 不仅仅是另一对二元运算符,比如 + 和 -。因为它们会短路,并且可能不会根据左侧操作数的值来计算其右侧操作数,所以它们的工作方式更像控制流表达式。
它们基本上是 if 语句的稍微变体,带有 else 子句。解释它们的最简单方法就是向你展示编译器代码以及它在生成的字节码中产生的控制流。从 and 开始,我们将其挂钩到此处的表达式解析表中
[TOKEN_NUMBER] = {number, NULL, PREC_NONE},
替换 1 行
[TOKEN_AND] = {NULL, and_, PREC_AND},
[TOKEN_CLASS] = {NULL, NULL, PREC_NONE},
这将转交给一个新的解析器函数。
在 defineVariable() 之后添加
static void and_(bool canAssign) { int endJump = emitJump(OP_JUMP_IF_FALSE); emitByte(OP_POP); parsePrecedence(PREC_AND); patchJump(endJump); }
在调用此函数时,左侧表达式已经编译。这意味着在运行时,它的值将在堆栈的顶部。如果该值为假,那么我们知道整个 and 必须为假,因此我们跳过右侧操作数,并将左侧的值作为整个表达式的结果。否则,我们将丢弃左侧值,并计算右侧操作数,它将成为整个 and 表达式的结果。
那四行代码正好产生了这一点。流程如下
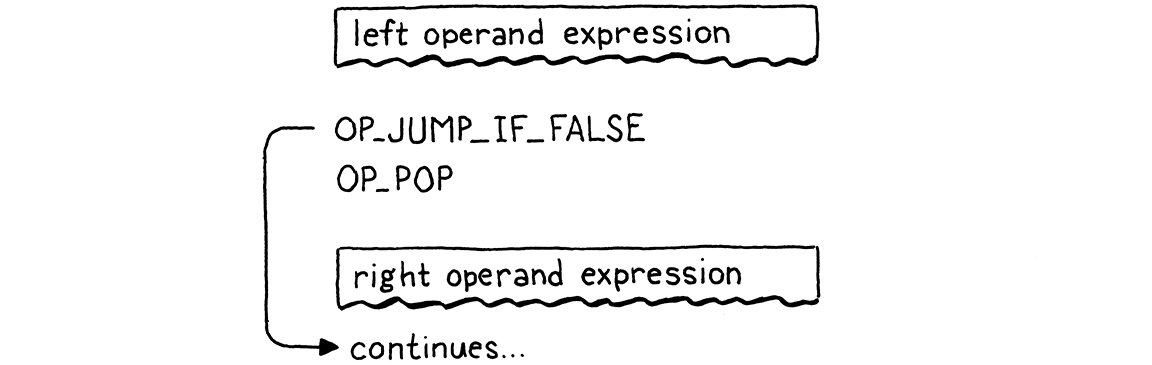
现在你可以明白为什么 OP_JUMP_IF_FALSE 保留堆栈顶部的值。当 and 的左侧为假时,该值会保留下来,成为整个表达式的结果。
23 . 2 . 1逻辑或运算符
or 运算符稍微复杂一些。首先我们将它添加到解析表中。
[TOKEN_NIL] = {literal, NULL, PREC_NONE},
替换 1 行
[TOKEN_OR] = {NULL, or_, PREC_OR},
[TOKEN_PRINT] = {NULL, NULL, PREC_NONE},
当该解析器消耗中缀 or 标记时,它会调用以下内容
在 number() 之后添加
static void or_(bool canAssign) { int elseJump = emitJump(OP_JUMP_IF_FALSE); int endJump = emitJump(OP_JUMP); patchJump(elseJump); emitByte(OP_POP); parsePrecedence(PREC_OR); patchJump(endJump); }
在 or 表达式中,如果左侧为真,那么我们将跳过右侧操作数。因此,我们需要在值为真时跳转。我们可以添加单独的指令,但为了展示我们的编译器如何自由地将语言的语义映射到它想要的任何指令序列,我使用我们已经存在的跳转指令来实现它。
当左侧为假时,它会跳过下一条语句。该语句是无条件跳过右侧操作数代码的语句。这个小技巧实际上是在值为真时执行跳转。流程如下

说实话,这不是最好的方法。要调度更多的指令,并且有更多的开销。or 没有理由比 and 慢。但看到可以在不添加任何新指令的情况下实现这两种运算符确实很有趣。请原谅我的放纵。
好的,这就是 Lox 中的三个分支结构。我的意思是,这些是仅向前跳过代码的控制流功能。其他语言通常具有一些多路分支语句,如 switch,以及可能是一个条件表达式,如 ?:,但 Lox 保持简单。
23 . 3While 语句
这将我们带到循环语句,它们向后跳转,以便可以多次执行代码。Lox 只有两个循环结构,while 和 for。while 循环(非常)简单,所以我们从那里开始。
ifStatement();
在 statement() 中
} else if (match(TOKEN_WHILE)) { whileStatement();
} else if (match(TOKEN_LEFT_BRACE)) {
当我们到达 while 标记时,我们会调用
在 printStatement() 之后添加
static void whileStatement() { consume(TOKEN_LEFT_PAREN, "Expect '(' after 'while'."); expression(); consume(TOKEN_RIGHT_PAREN, "Expect ')' after condition."); int exitJump = emitJump(OP_JUMP_IF_FALSE); emitByte(OP_POP); statement(); patchJump(exitJump); emitByte(OP_POP); }
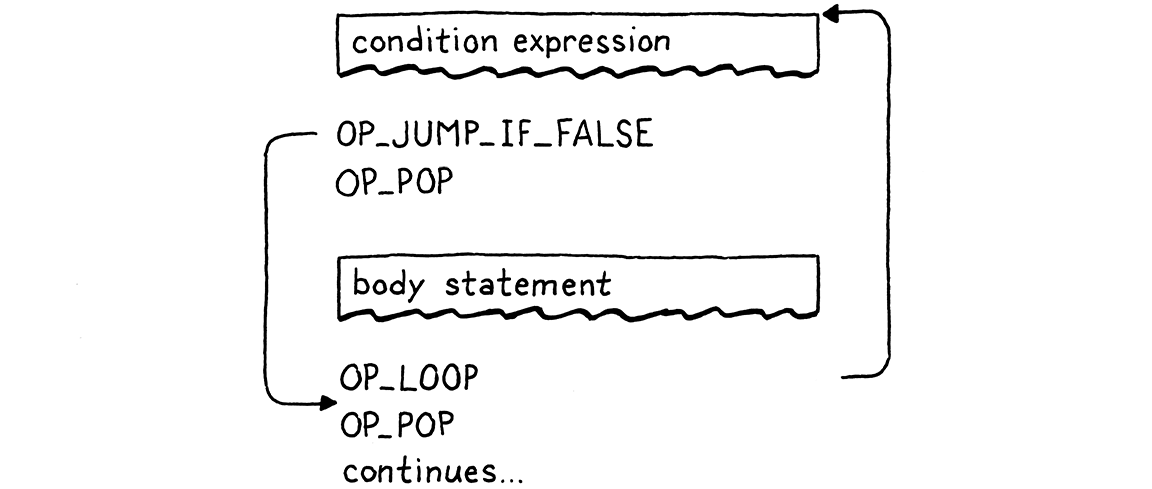
这大部分都反映了 if 语句—我们编译条件表达式,并将其包含在强制性括号中。后面跟着一个跳转指令,如果条件为假,该指令会跳过随后的主体语句。
我们在编译主体后修补跳转,并注意在任何一条路径上都从堆栈中弹出条件值。与 if 语句唯一的区别是循环。看起来像这样
statement();
在 whileStatement() 中
emitLoop(loopStart);
patchJump(exitJump);
在主体之后,我们调用此函数来发出“循环”指令。该指令需要知道要跳回多远。在向前跳转时,我们必须分两步发出指令,因为在发出跳转指令之前,我们不知道要跳多远。现在我们没有这个问题。我们已经编译了我们要跳回的代码点—它就在要编译的条件表达式之前。
我们只需要在编译时捕获该位置即可。
static void whileStatement() {
在 whileStatement() 中
int loopStart = currentChunk()->count;
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'while'.");
在执行 while 循环的主体后,我们会一直跳回到条件之前。这样一来,我们就会在每次迭代中重新计算条件表达式。我们将块的当前指令计数存储在 loopStart 中,以记录我们要编译的条件表达式之前的字节码偏移量。然后,我们将它传递给这个辅助函数
添加在 emitBytes() 之后
static void emitLoop(int loopStart) { emitByte(OP_LOOP); int offset = currentChunk()->count - loopStart + 2; if (offset > UINT16_MAX) error("Loop body too large."); emitByte((offset >> 8) & 0xff); emitByte(offset & 0xff); }
它有点像 emitJump() 和 patchJump() 的组合。它发出一个新的循环指令,该指令无条件地向后跳转给定偏移量。与跳转指令一样,在发出指令后,我们有一个 16 位操作数。我们计算从当前指令到我们要跳回的 loopStart 点的偏移量。+ 2 用于考虑 OP_LOOP 指令自身操作数的大小,我们也需要跳过它们。
从 VM 的角度来看,OP_LOOP 和 OP_JUMP 之间实际上没有语义差异。两者都只是将偏移量添加到 ip 中。我们可以对两者使用一条指令,并为其提供一个带符号的偏移量操作数。但我认为,使用现有操作码空间比手动将带符号的 16 位整数打包到两个字节中所需的烦人位操作要容易一些,所以为什么不使用它呢?
新的指令在这里
OP_JUMP_IF_FALSE,
在枚举 OpCode 中
OP_LOOP,
OP_RETURN,
在 VM 中,我们这样实现它
}
在 run() 中
case OP_LOOP: { uint16_t offset = READ_SHORT(); vm.ip -= offset; break; }
case OP_RETURN: {
与 OP_JUMP 唯一的区别是减法而不是加法。反汇编也类似。
return jumpInstruction("OP_JUMP_IF_FALSE", 1, chunk, offset);
在 disassembleInstruction() 中
case OP_LOOP: return jumpInstruction("OP_LOOP", -1, chunk, offset);
case OP_RETURN:
这就是我们的 while 语句。它包含两个跳转—一个条件向前跳转,在条件不满足时跳出循环,以及一个无条件循环向后跳转,在我们执行主体后执行。流程如下
23 . 4For 语句
Lox 中的另一个循环语句是来自 C 的久负盛名的 for 循环。与 while 循环相比,它要复杂得多。它有三个子句,所有这些子句都是可选的
-
初始化器可以是变量声明或表达式。它在语句开始时只执行一次。
-
条件子句是一个表达式。就像在
while循环中一样,当它计算结果为假时,我们会退出循环。 -
增量表达式在每次循环迭代结束时只执行一次。
在 jlox 中,解析器将 for 循环反糖化为 while 循环的合成 AST,并在循环之前和主体结束时添加一些额外内容。我们将做类似的事情,尽管我们不会经历像 AST 这样的过程。相反,我们的字节码编译器将使用我们已经存在的跳转和循环指令。
我们将逐一介绍实现过程,从 for 关键字开始。
printStatement();
在 statement() 中
} else if (match(TOKEN_FOR)) { forStatement();
} else if (match(TOKEN_IF)) {
它调用一个辅助函数。如果我们只支持子句为空的 for 循环,比如 for (;;),那么我们可以这样实现它
添加在 expressionStatement() 之后
static void forStatement() { consume(TOKEN_LEFT_PAREN, "Expect '(' after 'for'."); consume(TOKEN_SEMICOLON, "Expect ';'."); int loopStart = currentChunk()->count; consume(TOKEN_SEMICOLON, "Expect ';'."); consume(TOKEN_RIGHT_PAREN, "Expect ')' after for clauses."); statement(); emitLoop(loopStart); }
在顶部有很多强制性标点符号。然后我们编译主体。就像我们对 while 循环所做的那样,我们记录主体的顶部的字节码偏移量,并在主体之后发出一个循环,跳回到该点。我们现在已经有了工作正常的无限循环实现。
23 . 4 . 1初始化器子句
现在我们将添加第一个子句,即初始化器。它只执行一次,在主体之前执行,因此编译很简单。
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'for'.");
在 forStatement() 中
替换 1 行
if (match(TOKEN_SEMICOLON)) { // No initializer. } else if (match(TOKEN_VAR)) { varDeclaration(); } else { expressionStatement(); }
int loopStart = currentChunk()->count;
语法有点复杂,因为我们允许变量声明或表达式。我们使用 `var` 关键字的存在来判断是哪一种。对于表达式的情况,我们调用 `expressionStatement()` 而不是 `expression()`。它会查找分号,我们在这里也需要它,并且还会发出 `OP_POP` 指令来丢弃该值。我们不希望初始化程序在堆栈上留下任何东西。
如果 `for` 语句声明了一个变量,那么该变量应该作用于循环体。我们通过将整个语句包装在作用域中来确保这一点。
static void forStatement() {
在 forStatement() 中
beginScope();
consume(TOKEN_LEFT_PAREN, "Expect '(' after 'for'.");
然后我们在结尾处关闭它。
emitLoop(loopStart);
在 forStatement() 中
endScope();
}
23 . 4 . 2条件子句
接下来是条件表达式,它可以用于退出循环。
int loopStart = currentChunk()->count;
在 forStatement() 中
替换 1 行
int exitJump = -1; if (!match(TOKEN_SEMICOLON)) { expression(); consume(TOKEN_SEMICOLON, "Expect ';' after loop condition."); // Jump out of the loop if the condition is false. exitJump = emitJump(OP_JUMP_IF_FALSE); emitByte(OP_POP); // Condition. }
consume(TOKEN_RIGHT_PAREN, "Expect ')' after for clauses.");
由于该子句是可选的,我们需要查看它是否真的存在。如果省略了该子句,则下一个标记必须是一个分号,因此我们寻找它来判断。如果没有分号,则必须存在条件表达式。
在这种情况下,我们对其进行编译。然后,就像在 `while` 中一样,我们发出一个条件跳转,如果条件为假,则退出循环。由于跳转会在堆栈上保留该值,因此我们在执行主体之前弹出它。这样可以确保我们在条件为真时丢弃该值。
在循环体之后,我们需要修补该跳转。
emitLoop(loopStart);
在 forStatement() 中
if (exitJump != -1) { patchJump(exitJump); emitByte(OP_POP); // Condition. }
endScope(); }
我们只在存在条件子句时才执行此操作。如果没有,则没有跳转需要修补,也没有条件值在堆栈上需要弹出。
23 . 4 . 3增量子句
我把最好的留到最后,增量子句。它在文本上出现在主体之前,但在之后执行。如果我们解析成 AST 并单独传递生成代码,则可以简单地遍历 `for` 语句 AST 的主体字段,然后是增量子句。
不幸的是,我们不能稍后编译增量子句,因为我们的编译器只对代码进行单次传递。相反,我们将跳过增量,运行主体,跳回增量,运行它,然后进入下一轮迭代。
我知道,有点奇怪,但嘿,它比在 C 中手动管理内存中的 AST 好,对吧?以下是代码
}
在 forStatement() 中
替换 1 行
if (!match(TOKEN_RIGHT_PAREN)) { int bodyJump = emitJump(OP_JUMP); int incrementStart = currentChunk()->count; expression(); emitByte(OP_POP); consume(TOKEN_RIGHT_PAREN, "Expect ')' after for clauses."); emitLoop(loopStart); loopStart = incrementStart; patchJump(bodyJump); }
statement();
同样,它是可选的。由于这是最后一个子句,当省略时,下一个标记将是右括号。当存在增量时,我们需要现在对其进行编译,但它不应该立即执行。因此,首先,我们发出一个无条件跳转,它跳过增量子句的代码,到达循环主体。
接下来,我们编译增量表达式本身。这通常是一个赋值。无论是什么,我们只执行它的副作用,因此我们还会发出一个弹出操作来丢弃它的值。
最后的部分有点棘手。首先,我们发出一个循环指令。这是将我们带回 `for` 循环顶部的主要循环—如果存在条件表达式,则在条件表达式之前。该循环发生在增量之后,因为增量在每次循环迭代结束时执行。
然后我们将 `loopStart` 更改为指向增量表达式开始的偏移量。稍后,当我们在主体语句之后发出循环指令时,这将导致它跳转到增量表达式,而不是循环的顶部,就像在没有增量时一样。这就是我们将增量编织在一起并在主体之后运行的方式。
它很复杂,但一切都奏效了。一个包含所有子句的完整循环编译成这样的流程
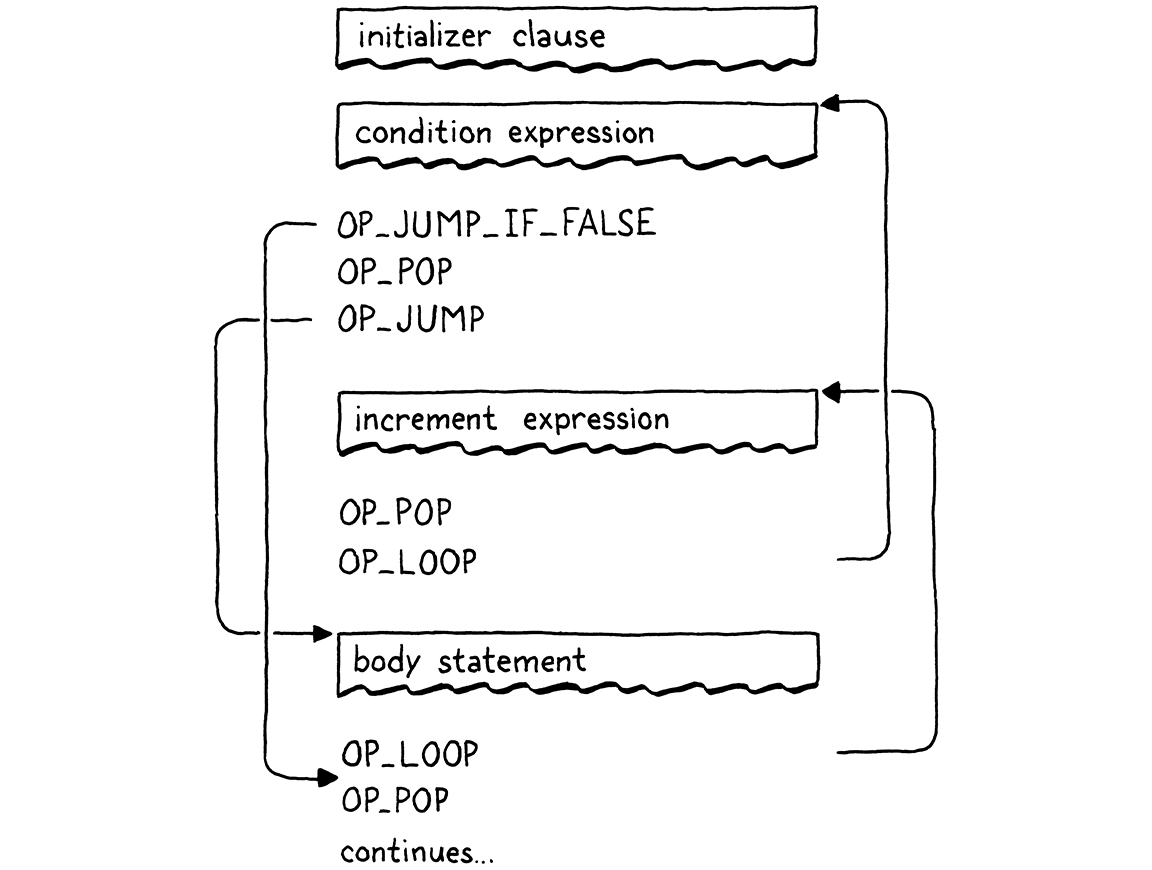
与在 jlox 中实现 `for` 循环一样,我们不需要接触运行时。它全部编译成 VM 已经支持的原始控制流操作。在本章中,我们向前迈出了一大步飞跃—clox 现在是图灵完备的。我们还涵盖了许多新的语法:三种语句和两种表达式形式。即便如此,它只使用了三个新的简单指令。对于我们的 VM 架构来说,这是一个非常好的努力与回报的比例。
挑战
-
除了 `if` 语句之外,大多数 C 语言家族的语言都具有多路 `switch` 语句。在 clox 中添加一个。语法是
switchStmt → "switch" "(" expression ")" "{" switchCase* defaultCase? "}" ; switchCase → "case" expression ":" statement* ; defaultCase → "default" ":" statement* ;
要执行 `switch` 语句,首先计算带括号的 switch 值表达式。然后遍历 case。对于每个 case,计算它的值表达式。如果 case 值等于 switch 值,则执行 case 下面的语句,然后退出 `switch` 语句。否则,尝试下一个 case。如果没有 case 匹配,并且存在 `default` 子句,则执行其语句。
为了简化,我们省略了 fallthrough 和 `break` 语句。每个 case 在其语句完成后会自动跳转到 switch 语句的末尾。
-
在 jlox 中,我们面临着为 `break` 语句添加支持的挑战。这次,让我们做 `continue`
continueStmt → "continue" ";" ;
一个 `continue` 语句直接跳转到最近的封闭循环的顶部,跳过循环体的其余部分。在 `for` 循环中,`continue` 跳转到增量子句(如果有)。如果没有封闭在循环中的 `continue` 语句,则为编译时错误。
确保考虑作用域。当执行 `continue` 时,在循环体或嵌套在循环中的块内声明的局部变量应该如何处理?
-
控制流结构自 Algol 68 以来基本上没有改变。从那时起,语言发展专注于使代码更具声明性,更高级,因此命令式控制流没有受到太多关注。
为了好玩,尝试为 Lox 发明一个有用的新型控制流功能。它可以是对现有形式的改进,也可以是全新的东西。在实践中,很难在这个低表达水平上想出足够有用的东西来抵消迫使用户学习不熟悉符号和行为的成本,但这是一个练习设计技能的好机会。
设计说明:考虑 Goto Harmful
发现 Lox 中所有美丽的结构化控制流实际上都是编译成原始的非结构化跳转,就像在 Scooby Doo 中,怪物从脸上撕掉面具的那一刻。它一直都是 goto!只是在这种情况下,怪物在面具下面。我们都知道 goto 是邪恶的。但是 . . . 为什么呢?
确实,你可以使用 goto 编写非常难以维护的代码。但我认为今天大多数程序员都没有亲眼目睹过。这种风格已经很久没有流行了。如今,它是我们在篝火旁讲恐怖故事时用来吓唬人的恶灵。
我们很少面对那个怪物的原因是 Edsger Dijkstra 用他在 Communications of the ACM(1968 年 3 月)上发表的著名信件“Go To Statement Considered Harmful”杀死了它。关于结构化编程的争论已经持续了一段时间,双方都有支持者,但我认为 Dijkstra 在有效地结束争论方面功不可没。今天大多数新语言都没有非结构化跳转语句。
一篇只有一页半的信件几乎单枪匹马地摧毁了语言特性,这真是太令人印象深刻了。如果你还没有读过,我鼓励你阅读。这是计算机科学史上的一篇开创性的作品,是我们部落的祖先之歌。此外,它也是练习阅读学术 CS 写作的好方法,这是需要培养的一项有用技能。
我读了很多遍,以及一些批评、回复和评论。我最后的感觉,充其量是喜忧参半。从非常高的层次上讲,我同意他的观点。他的总体论点是这样的
-
作为程序员,我们编写程序—静态文本—但我们关心的是实际运行的程序—它的动态行为。
-
我们更擅长推理静态事物,而不是动态事物。(他没有提供任何证据来支持这个说法,但我接受了。)
-
因此,我们越能使程序的动态执行反映其文本结构,越好。
这是一个良好的开端。将我们的注意力吸引到我们编写的代码和它在机器内部运行的代码之间的分离是一个有趣的见解。然后他试图定义程序文本和执行之间的“对应关系”。对于一个几乎一生都在主张提高编程严谨性的人来说,他的定义非常含糊。他说
现在让我们考虑如何描述一个进程的进展。(你可以以非常具体的方式思考这个问题:假设一个进程被认为是一系列时间上的动作,在执行任意动作后被停止,我们需要修复哪些数据才能使我们能够重新执行该进程,直到到达完全相同的点?)
想象一下。你有两台计算机,运行相同的程序,使用完全相同的输入—所以完全是确定性的。你在其执行中的任意点暂停其中一台。你需要发送哪些数据到另一台计算机,以便能够在与第一台计算机完全相同的点暂停它?
如果你的程序只允许简单的语句,比如赋值,那就很容易。你只需要知道你执行的最后一条语句之后的点。基本上是一个断点,我们 VM 中的 `ip`,或者错误消息中的行号。添加像 `if` 和 `switch` 这样的分支控制流不会增加任何东西。即使标记指向分支内部,我们仍然可以判断我们身在何处。
一旦你添加了函数调用,你就需要更多的东西。你可能在函数中间暂停了第一台计算机,但该函数可能从多个地方调用。为了在整个程序执行中的完全相同的点暂停第二台计算机,你需要在对该函数的正确调用处暂停它。
所以你不仅需要知道当前语句,而且对于还没有返回的函数调用,你需要知道调用点的地址。换句话说,一个调用栈,虽然我认为 Dijkstra 写这篇文章时还没有这个术语。太酷了。
他注意到循环会让事情变得更难。如果你在循环体中间暂停,你就不知道已经运行了多少次迭代。所以他说你还需要保留一个迭代计数。而且,由于循环可以嵌套,你需要一个这些计数的栈(大概与调用栈指针交织在一起,因为你也可以在外部调用中的循环中)。
这就是事情变得奇怪的地方。所以我们现在真正要构建一些东西,你期望他解释 goto 如何破坏这一切。相反,他只是说
无限制地使用 goto 语句会立即导致一个后果,即变得极其难以找到一个有意义的坐标集来描述进程的进度。
他没有证明这很难,也没有说明为什么。他只是说。他说了一种方法不令人满意
当然,使用 goto 语句,人们仍然可以通过一个计数器来唯一地描述进度,该计数器统计自程序启动以来执行的操作次数(即一种规范化时钟)。困难在于,这种坐标虽然是唯一的,但完全没有帮助。
但是 . . . 这实际上是循环计数器所做的,而他对那些循环计数器没有意见。并不是说每个循环都是一个简单的“从 0 到 10 的每个整数”递增计数。很多是带有复杂条件语句的 while 循环。
以一个熟悉的例子来说,考虑 clox 中心的核心字节码执行循环。Dijkstra 认为该循环是易于处理的,因为我们可以简单地统计循环运行的次数来推断其进度。但是该循环在用户的编译 Lox 程序中的每个执行的指令都会运行一次。知道它执行了 6201 个字节码指令真的能告诉我们 VM 维护人员关于解释器状态的任何有意义的东西吗?
事实上,这个具体的例子指出了一个更深层的真相。Böhm 和 Jacopini 证明了使用 goto 的任何控制流都可以转换成只使用顺序、循环和分支的控制流。我们的字节码解释器循环是该证明的一个生动的例子:它在不使用任何 goto 的情况下实现了 clox 字节码指令集的非结构化控制流。
这似乎为 Dijkstra 的说法提供了一个反驳:你可以通过将使用 goto 的程序转换为不使用 goto 的程序来定义对应关系,然后使用来自该程序的对应关系,该对应关系—在他看来—是可以接受的,因为它只使用分支和循环。
但是,老实说,我的论点在这里也很薄弱。我认为我们俩基本上都在进行假装的数学运算,并使用虚假的逻辑来进行本来应该是一种经验性的、以人为中心的论证。Dijkstra 确实说了一些使用 goto 的代码非常糟糕。其中很多可以使用结构化控制流转换为更清晰的代码。
通过从语言中完全消除 goto,你绝对可以阻止使用 goto 编写糟糕的代码。强制用户使用结构化控制流,并使使用这些结构编写类似 goto 的代码成为一项艰巨的任务,这可能是提高我们所有人工作效率的最佳选择。
但我有时会想知道我们是否把孩子和洗澡水一起倒掉了。在没有 goto 的情况下,我们经常求助于更复杂的结构化模式。“循环中的 switch”就是一个典型的例子。另一个是使用一个守卫变量来退出一系列嵌套循环
// See if the matrix contains a zero. bool found = false; for (int x = 0; x < xSize; x++) { for (int y = 0; y < ySize; y++) { for (int z = 0; z < zSize; z++) { if (matrix[x][y][z] == 0) { printf("found"); found = true; break; } } if (found) break; } if (found) break; }
这真的比
for (int x = 0; x < xSize; x++) { for (int y = 0; y < ySize; y++) { for (int z = 0; z < zSize; z++) { if (matrix[x][y][z] == 0) { printf("found"); goto done; } } } } done:
我想我真正不喜欢的是,我们今天正在基于恐惧做出语言设计和工程决策。如今很少有人对 goto 的问题和优点有深入的理解。相反,我们只是认为它“被认为是有害的”。就我个人而言,我从未发现教条是高质量创造性工作的一个好的起点。