语句和状态
我的一生,我的心一直在渴望一个我无法言喻的东西。 安德烈·布勒东,疯狂的爱
我们到目前为止的解释器更像是编程一个真正的语言,而更像是计算器上的按钮。对我来说,“编程”意味着用更小的部分构建一个系统。我们还不能做到这一点,因为我们没有办法将一个名称绑定到某些数据或函数。如果没有一种引用这些部分的方法,我们就无法组合软件。
为了支持绑定,我们的解释器需要内部状态。当你在一开始定义一个变量并在最后使用它时,解释器必须在这段时间内保存该变量的值。所以在这章中,我们将赋予我们的解释器一个大脑,它不仅可以处理,还可以记住。
状态和 语句紧密相连。因为根据定义,语句不会求值为一个值,所以它们需要做其他事情才能有用。这就是所谓的**副作用**。它可能意味着生成用户可见的输出或修改解释器中的一些状态,这些状态可以稍后被检测到。后者使它们非常适合定义变量或其他命名实体。
在这章中,我们将完成所有这些。我们将定义产生输出的语句 (print) 并创建状态 (var)。我们将添加表达式来访问和赋值给变量。最后,我们将添加块和局部范围。这在单章中要塞进很多东西,但我们将逐个地咀嚼它。
8 . 1语句
我们首先通过扩展 Lox 的语法来添加语句。它们与表达式没有太大区别。我们从两种最简单的类型开始
-
一个表达式语句允许你在期望语句的地方放置一个表达式。它们存在于求值具有副作用的表达式。你可能没有注意到它们,但你在 C、Java 和其他语言中一直使用它们。任何时候你看到一个函数或方法调用后面跟着一个
;,你正在查看一个表达式语句。 -
一个
print语句求值一个表达式并将结果显示给用户。我承认,将打印直接烘焙到语言中,而不是将其作为库函数,这很奇怪。这样做是对我们正在逐章构建这个解释器,并且希望能够在完成之前与它进行交互这一事实的妥协。为了使打印成为库函数,我们将不得不等到我们拥有定义和调用函数的所有机制 之前 才能看到任何副作用。
新的语法意味着新的语法规则。在这章中,我们终于获得了解析整个 Lox 脚本的能力。由于 Lox 是一种命令式、动态类型的语言,脚本的“顶层”只是一个语句列表。新的规则是
program → statement* EOF ; statement → exprStmt | printStmt ; exprStmt → expression ";" ; printStmt → "print" expression ";" ;
第一个规则现在是 program,它是语法的起点,代表一个完整的 Lox 脚本或 REPL 输入。程序是一个语句列表,后面跟着特殊的“文件结束”标记。强制性的结束标记确保解析器消耗整个输入,并且不会在脚本结束时静默地忽略错误的未消耗标记。
现在,statement 只有我们描述的两种语句类型的两种情况。我们将在本章稍后和后面的章节中添加更多内容。下一步是将这个语法变成我们可以存储在内存中的东西—语法树。
8 . 1 . 1语句语法树
在语法中没有任何地方允许同时使用表达式和语句。例如,+ 的操作数始终是表达式,而不是语句。while 循环的主体始终是一个语句。
由于两种语法是分离的,所以我们不需要一个它们都继承的单个基类。将表达式和语句拆分为单独的类层次结构可以使 Java 编译器帮助我们找到像将语句传递给期望表达式的 Java 方法这样的愚蠢错误。
这意味着一个新的语句基类。正如我们之前的长辈一样,我们将使用神秘的名称“Stmt”。为了有更大的 远见,我已经设计了我们的小型 AST 元编程脚本来预期这一点。这就是为什么我们将“Expr”作为参数传递给 defineAst()。现在,我们添加另一个调用来定义 Stmt 及其 子类。
"Unary : Token operator, Expr right"
));
在 main() 中
defineAst(outputDir, "Stmt", Arrays.asList(
"Expression : Expr expression",
"Print : Expr expression"
));
}
运行 AST 生成器脚本,看看生成的“Stmt.java”文件,其中包含我们需要的表达式和 print 语句的语法树类。不要忘记将该文件添加到你的 IDE 项目或 makefile 或者任何东西中。
8 . 1 . 2解析语句
解析器用来解析并返回单个表达式的 parse() 方法只是一个临时 hack,让上一章能够运行。现在我们的语法有了正确的起始规则 program,我们可以将 parse() 变成真正的程序。
方法 parse()
替换 7 行
List<Stmt> parse() { List<Stmt> statements = new ArrayList<>(); while (!isAtEnd()) { statements.add(statement()); } return statements; }
这解析了一系列语句,尽可能多地解析,直到遇到输入的结尾。这基本上是将 program 规则直接翻译成递归下降风格。由于我们现在使用的是 ArrayList,我们必须对 Java 冗长之神做一个小小的祈祷。
package com.craftinginterpreters.lox;
import java.util.ArrayList;
import java.util.List;
程序是一个语句列表,我们使用这个方法解析其中一个语句
在 expression() 后添加
private Stmt statement() { if (match(PRINT)) return printStatement(); return expressionStatement(); }
虽然有点简陋,但我们稍后会用更多的语句类型来填充它。我们通过查看当前标记来确定匹配了哪个特定的语句规则。print 标记显然意味着它是一个 print 语句。
如果下一个标记不像是任何已知类型的语句,我们假设它必须是一个表达式语句。这在解析语句时通常是最后的落脚点,因为很难从第一个标记主动识别一个表达式。
每种语句类型都有自己的方法。首先是 print
在 statement() 后添加
private Stmt printStatement() { Expr value = expression(); consume(SEMICOLON, "Expect ';' after value."); return new Stmt.Print(value); }
由于我们已经匹配并消耗了 print 标记本身,所以这里不需要再这样做。我们解析后续的表达式,消耗终止的分号,并发出语法树。
如果我们没有匹配到 print 语句,我们一定有一个
在 printStatement() 后添加
private Stmt expressionStatement() { Expr expr = expression(); consume(SEMICOLON, "Expect ';' after expression."); return new Stmt.Expression(expr); }
类似于前一个方法,我们解析一个表达式,后面跟着一个分号。我们将该 Expr 包装到合适的 Stmt 类型中,并返回它。
8 . 1 . 3执行语句
我们正在微观地经历前两章,逐步完成前端。我们的解析器现在可以生成语句语法树,所以下一阶段也是最后阶段是解释它们。与表达式一样,我们使用访问者模式,但我们有一个新的访问者接口 Stmt.Visitor 来实现,因为语句有自己的基类。
我们将它添加到 Interpreter 实现的接口列表中。
替换 1 行
class Interpreter implements Expr.Visitor<Object>, Stmt.Visitor<Void> {
void interpret(Expr expression) {
与表达式不同,语句不会产生值,所以访问方法的返回类型是 Void,而不是 Object。我们有两种语句类型,我们需要为每种类型添加一个访问方法。最简单的是表达式语句。
在 evaluate() 后添加
@Override public Void visitExpressionStmt(Stmt.Expression stmt) { evaluate(stmt.expression); return null; }
我们使用现有的 evaluate() 方法求值内部表达式,并 丢弃该值。然后我们返回 null。Java 要求这样做,才能满足特殊的首字母大写的 Void 返回类型。很奇怪,但你又能怎么办呢?
print 语句的访问方法并没有太大区别。
在 visitExpressionStmt() 后添加
@Override public Void visitPrintStmt(Stmt.Print stmt) { Object value = evaluate(stmt.expression); System.out.println(stringify(value)); return null; }
在丢弃表达式的值之前,我们使用我们在上一章中介绍的 stringify() 方法将其转换为字符串,然后将其转储到 stdout。
我们的解释器现在能够访问语句,但我们有一些工作要做,才能将它们提供给它。首先,修改 Interpreter 类中旧的 interpret() 方法,使其接受一个语句列表—换句话说,就是一个程序。
方法 interpret()
替换 8 行
void interpret(List<Stmt> statements) { try { for (Stmt statement : statements) { execute(statement); } } catch (RuntimeError error) { Lox.runtimeError(error); } }
这将替换旧的代码,该代码接受单个表达式。新代码依赖于这个小型的辅助方法
在 evaluate() 后添加
private void execute(Stmt stmt) { stmt.accept(this); }
这就是语句与我们为表达式使用的 evaluate() 方法的类似物。由于我们现在正在使用列表,所以我们需要让 Java 知道这一点。
package com.craftinginterpreters.lox;
import java.util.List;
class Interpreter implements Expr.Visitor<Object>,
主 Lox 类仍在尝试解析单个表达式并将它传递给解释器。我们将解析行修改如下
Parser parser = new Parser(tokens);
在 run() 中
替换 1 行
List<Stmt> statements = parser.parse();
// Stop if there was a syntax error.
然后用以下内容替换对解释器的调用
if (hadError) return;
在 run() 中
替换 1 行
interpreter.interpret(statements);
}
基本上只是将新的语法连接起来。好的,启动解释器,试一试。在这一点上,值得在文本文件中草拟一个小的 Lox 程序,作为脚本运行。例如
print "one"; print true; print 2 + 1;
它看起来几乎像一个真正的程序!请注意,REPL 也要求您输入完整的语句,而不是简单的表达式。不要忘记分号。
8 . 2全局变量
现在我们有了语句,可以开始处理状态了。在我们深入到词法作用域的所有复杂性之前,我们将从最简单的变量类型—全局变量开始。我们需要两种新的构造。
-
变量声明语句将一个新的变量引入世界。
var beverage = "espresso";
这将创建一个新的绑定,将一个名称(这里是“beverage”)与一个值(这里是字符串
"espresso")关联起来。 -
完成后,变量表达式将访问该绑定。当标识符“beverage”用作表达式时,它会查找绑定到该名称的值并返回它。
print beverage; // "espresso".
稍后,我们将添加赋值和块作用域,但这足以让我们开始行动。
8 . 2 . 1变量语法
与之前一样,我们将从前到后逐步完成实现,从语法开始。变量声明是语句,但它们与其他语句不同,我们将把语句语法分成两部分来处理它们。这是因为语法限制了某些语句允许出现的位置。
控制流语句中的子句—比如 if 语句的 then 和 else 分支,或者 while 的主体—都是单个语句。但是,该语句不允许是声明名称的语句。以下是允许的:
if (monday) print "Ugh, already?";
但是以下是不允许的:
if (monday) var beverage = "espresso";
我们可以允许后者,但这会让人困惑。beverage 变量的作用域是什么?它在 if 语句之后是否仍然存在?如果是,它在周一以外的日子里的值是什么?变量在那些日子里存在吗?
像这样的代码很奇怪,所以 C、Java 和它们的同类语言都不允许它。就好像语句存在两个级别的“优先级”。某些允许出现语句的地方—比如在块内部或顶层—允许任何类型的语句,包括声明。其他地方只允许那些不声明名称的“更高优先级”语句。
为了适应这种区别,我们为声明名称的语句类型添加了另一个规则。
program → declaration* EOF ; declaration → varDecl | statement ; statement → exprStmt | printStmt ;
声明语句位于新的 declaration 规则下。现在,它只包括变量,但稍后将包括函数和类。任何允许声明的地方也允许非声明语句,因此 declaration 规则将一直延续到 statement。显然,您可以在脚本的顶层声明东西,因此 program 将路由到新的规则。
声明变量的规则如下所示:
varDecl → "var" IDENTIFIER ( "=" expression )? ";" ;
像大多数语句一样,它以一个前导关键字开头。在本例中,是 var。然后是一个标识符标记,用于表示要声明的变量的名称,后面跟着一个可选的初始化表达式。最后,我们用分号将其装饰一下。
为了访问变量,我们定义了一种新的基本表达式类型。
primary → "true" | "false" | "nil" | NUMBER | STRING | "(" expression ")" | IDENTIFIER ;
该 IDENTIFIER 子句匹配单个标识符标记,该标记被理解为要访问的变量的名称。
这些新的语法规则会得到相应的语法树。在 AST 生成器中,我们为变量声明添加了一个新的语句节点。
"Expression : Expr expression",
"Print : Expr expression",
在 main() 中
将 “,” 添加到上一行
"Var : Token name, Expr initializer"
));
它存储名称标记,以便我们知道它在声明什么,以及初始化表达式。(如果没有初始化程序,该字段将为 null。)
然后,我们为访问变量添加一个表达式节点。
"Literal : Object value",
"Unary : Token operator, Expr right",
在 main() 中
将 “,” 添加到上一行
"Variable : Token name"
));
它只是变量名称标记的包装器。就是这样。和往常一样,别忘了运行 AST 生成器脚本,以便获得更新的“Expr.java”和“Stmt.java”文件。
8 . 2 . 2解析变量
在我们解析变量语句之前,我们需要调整一些代码,以便在语法中为新的 declaration 规则腾出空间。程序的顶层现在是一系列声明,因此解析器的入口点方法发生了变化。
List<Stmt> parse() {
List<Stmt> statements = new ArrayList<>();
while (!isAtEnd()) {
在 parse() 中
替换 1 行
statements.add(declaration());
}
return statements;
}
它调用了这个新方法
在 expression() 后添加
private Stmt declaration() { try { if (match(VAR)) return varDeclaration(); return statement(); } catch (ParseError error) { synchronize(); return null; } }
嘿,你还记得在前面章节中,我们为执行错误恢复而构建的基础设施吗?我们终于可以将其连接起来了。
这个 declaration() 方法是我们解析块或脚本中一系列语句时反复调用的方法,因此它是解析器进入恐慌模式时进行同步的合适位置。该方法的整个主体都包含在一个 try 块中,用于捕获解析器开始错误恢复时抛出的异常。这会让它恢复到尝试解析下一个语句或声明的开头。
真正的解析工作发生在 try 块内部。首先,它会查看我们是否位于变量声明处,方法是查找前导 var 关键字。如果没有,它会继续执行现有的 statement() 方法,该方法解析 print 和表达式语句。
还记得 statement() 如何在没有其他语句匹配的情况下尝试解析表达式语句吗?以及 expression() 如何在无法解析当前标记处的表达式时报告语法错误吗?这系列调用确保我们会在未解析到有效的声明或语句时报告错误。
当解析器匹配 var 标记时,它会分支到
在 printStatement() 后添加
private Stmt varDeclaration() { Token name = consume(IDENTIFIER, "Expect variable name."); Expr initializer = null; if (match(EQUAL)) { initializer = expression(); } consume(SEMICOLON, "Expect ';' after variable declaration."); return new Stmt.Var(name, initializer); }
与往常一样,递归下降代码遵循语法规则。解析器已经匹配了 var 标记,因此接下来它需要并消耗标识符标记,用于表示变量名称。
然后,如果它看到 = 标记,它就知道存在初始化表达式,并解析它。否则,它将初始化程序设置为 null。最后,它消耗语句结尾所需的句号。所有这些都将包装在 Stmt.Var 语法树节点中,我们很酷。
解析变量表达式甚至更容易。在 primary() 中,我们寻找标识符标记。
return new Expr.Literal(previous().literal);
}
在 primary() 中
if (match(IDENTIFIER)) {
return new Expr.Variable(previous());
}
if (match(LEFT_PAREN)) {
这样我们就为声明和使用变量提供了一个可用的前端。剩下的就是将其输入解释器。在我们开始之前,我们需要谈谈变量在内存中的存储位置。
8 . 3环境
将变量与值关联的绑定需要存储在某个地方。自从 Lisp 的人发明了括号以来,这个数据结构就被称为环境。
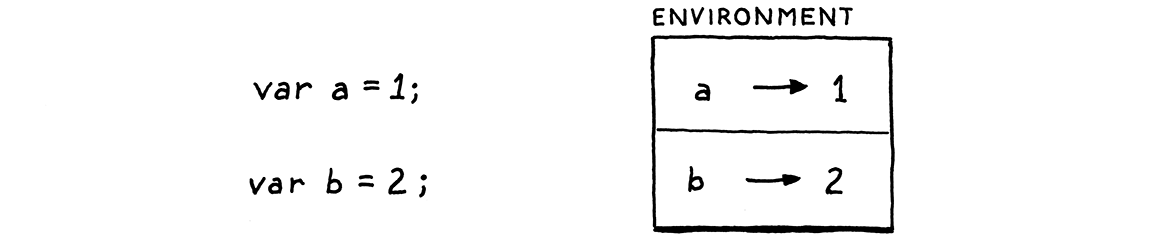
您可以将其想象成一个映射,其中键是变量名,值是变量的,呃,值。事实上,我们将在 Java 中这样实现它。我们可以将该映射和管理它的代码直接放入 Interpreter 中,但由于它形成了一个清晰的概念,我们将将其提取到自己的类中。
新建一个文件并添加
新建文件
package com.craftinginterpreters.lox; import java.util.HashMap; import java.util.Map; class Environment { private final Map<String, Object> values = new HashMap<>(); }
其中有一个 Java Map 用于存储绑定。它使用裸字符串作为键,而不是标记。标记表示源文本中特定位置的代码单元,但是当谈到查找变量时,所有具有相同名称的标识符标记都应该引用同一个变量(暂时忽略作用域)。使用原始字符串可确保所有这些标记都引用相同的映射键。
我们需要支持两种操作。首先,变量定义将一个新名称绑定到一个值。
在 class Environment 中
void define(String name, Object value) { values.put(name, value); }
这并不难,但我们做了一个有趣的语义选择。当我们在映射中添加键时,我们不会检查它是否已经存在。这意味着该程序可以正常工作
var a = "before"; print a; // "before". var a = "after"; print a; // "after".
变量语句不仅可以定义一个新变量,还可以用来重新定义一个已有的变量。我们可以选择将此定义为错误。用户可能并不想重新定义一个已有的变量。(如果他们确实想重新定义,他们可能会使用赋值,而不是 var。)将重新定义定义为错误将帮助他们找到该错误。
但是,这样做与 REPL 的交互性不好。在 REPL 会话中,不用去记你已经定义了哪些变量是一件好事。我们可以允许在 REPL 中重新定义变量,但在脚本中不允许,但这样用户就必须学习两套规则,并且从一种形式复制粘贴到另一种形式的代码可能无法正常工作。
因此,为了保持两种模式的一致性,我们将允许它—至少对于全局变量而言。一旦变量存在,我们就需要一种方法来查找它。
class Environment {
private final Map<String, Object> values = new HashMap<>();
在 class Environment 中
Object get(Token name) { if (values.containsKey(name.lexeme)) { return values.get(name.lexeme); } throw new RuntimeError(name, "Undefined variable '" + name.lexeme + "'."); }
void define(String name, Object value) {
这在语义上更有意思。如果找到了变量,它只是返回与它绑定的值。但如果没有找到呢?我们还有另一个选择
-
将其定义为语法错误。
-
将其定义为运行时错误。
-
允许它并返回一些默认值,比如
nil。
Lox 很宽松,但我认为最后一个选项过于宽容。将其定义为语法错误—编译时错误—似乎是一个明智的选择。使用未定义的变量是一个错误,越早检测到错误越好。
问题在于使用变量和引用变量不同。如果你将一段代码包含在一个函数中,你可以在这段代码中引用变量,而不会立即对其进行求值。如果我们将其设置为在提及变量之前声明变量会导致静态错误,那么定义递归函数就会变得困难很多。
我们可以通过在检查函数体之前声明函数自身的名称来容纳单一递归—一个调用自身的函数—。但是,这对于相互递归的过程(相互调用)没有帮助。考虑以下情况:
fun isOdd(n) { if (n == 0) return false; return isEven(n - 1); } fun isEven(n) { if (n == 0) return true; return isOdd(n - 1); }
当我们查看isOdd()的函数体时,isEven()函数还没有被定义,而该函数体中调用了isEven()函数。如果我们交换两个函数的顺序,那么当我们查看isEven()的函数体时,isOdd()函数还没有被定义。
由于将其设置为静态错误会使递归声明过于困难,因此我们将错误推迟到运行时。只要你没有求值引用,就可以在定义变量之前引用它。这使偶数和奇数程序可以正常工作,但你会在以下代码中遇到运行时错误:
print a; var a = "too late!";
与表达式求值代码中的类型错误一样,我们通过抛出异常来报告运行时错误。异常包含变量的标记,因此我们可以告诉用户他们在代码中的哪个位置出了问题。
8 . 3 . 1解释全局变量
Interpreter类获取新Environment类的实例。
class Interpreter implements Expr.Visitor<Object>,
Stmt.Visitor<Void> {
在Interpreter类中
private Environment environment = new Environment();
void interpret(List<Stmt> statements) {
我们将它直接存储为Interpreter中的一个字段,以便变量在解释器运行期间一直保持在内存中。
我们有两个新的语法树,所以有两个新的访问方法。第一个用于声明语句。
在visitPrintStmt()之后添加
@Override public Void visitVarStmt(Stmt.Var stmt) { Object value = null; if (stmt.initializer != null) { value = evaluate(stmt.initializer); } environment.define(stmt.name.lexeme, value); return null; }
如果变量有初始化器,我们对其进行求值。如果没有,我们需要做出另一个选择。我们可以通过要求初始化器将其设置为解析器中的语法错误。但是,大多数语言并没有这样做,所以在Lox中这样做感觉有点过于苛刻。
我们可以将其设置为运行时错误。我们可以让你定义一个未初始化的变量,但如果你在给它赋值之前访问它,就会发生运行时错误。这不是一个坏主意,但大多数动态类型语言并没有这样做。相反,我们将保持简单,说如果Lox没有显式初始化变量,则将其设置为nil。
var a; print a; // "nil".
因此,如果没有初始化器,我们将值设置为null,它是Lox的nil值的Java表示。然后我们告诉环境将变量绑定到该值。
接下来,我们求值一个变量表达式。
在visitUnaryExpr()之后添加
@Override public Object visitVariableExpr(Expr.Variable expr) { return environment.get(expr.name); }
这只是转发到环境,环境会进行繁重的工作,以确保变量已定义。这样,我们就有了基本的变量工作。试试这个
var a = 1; var b = 2; print a + b;
我们还不能重用代码,但我们可以开始构建重用数据的程序。
8 . 4赋值
可以创建一种语言,该语言具有变量,但不允许你重新赋值—或修改—它们。Haskell就是一个例子。SML仅支持可变引用和数组—变量不能重新赋值。Rust通过要求mut修饰符来启用赋值,从而引导你远离修改。
修改变量是一种副作用,正如其名称所示,一些语言人士认为副作用是肮脏的或不优雅的。代码应该是纯粹的数学,它生成值—像水晶一样,永恒不变的值—就像神圣创造的行为一样。而不是一些肮脏的自动机,它一次一个命令式咕哝地将数据块塑造成形。
Lox并不那么严苛。Lox是一种命令式语言,修改是其固有的一部分。添加对赋值的支持不需要太多工作。全局变量已经支持重新定义,因此大部分机制现在都已经存在了。主要缺少的是显式的赋值符号。
8 . 4 . 1赋值语法
这个小小的=语法比看起来要复杂。与大多数C衍生的语言一样,赋值是一个表达式,而不是一个语句。与C一样,它是最低优先级表达式形式。这意味着规则在expression和equality(下一个最低优先级表达式)之间插入。
expression → assignment ; assignment → IDENTIFIER "=" assignment | equality ;
这表明assignment要么是标识符后面跟着=和一个用于值的表达式,要么是equality(以及因此所有其他)表达式。稍后,当我们在对象上添加属性设置器时,assignment将变得更加复杂,例如:
instance.field = "value";
简单的一部分是添加新的语法树节点。
defineAst(outputDir, "Expr", Arrays.asList(
在 main() 中
"Assign : Token name, Expr value",
"Binary : Expr left, Token operator, Expr right",
它有一个用于要分配的变量的标记,以及一个用于新值的表达式。在运行AstGenerator以获取新的Expr.Assign类之后,交换解析器现有expression()方法的函数体,使其与更新后的规则相匹配。
private Expr expression() {
在expression()中
替换 1 行
return assignment();
}
这里就变得棘手了。单标记超前递归下降解析器无法看到足够远,直到它遍历左侧并遇到=时才能确定它正在解析赋值。你可能想知道它为什么需要这样做。毕竟,我们在完成对左操作数的解析之前,并不知道我们正在解析+表达式。
区别在于赋值的左侧不是一个求值为值的表达式。它是一种伪表达式,它求值为可以分配到的“东西”。考虑以下情况:
var a = "before"; a = "value";
在第二行中,我们没有求值a(这将返回字符串“before”)。我们找出a引用的变量,以便我们知道将右侧表达式的值存储在何处。这些两个结构的经典术语是左值和右值。我们迄今为止所见过的所有生成值的表达式都是右值。左值“求值为”一个存储位置,你可以将值赋值到该位置。
我们希望语法树反映出左值不会像普通表达式一样被求值。这就是为什么Expr.Assign节点具有用于左侧的Token,而不是Expr。问题是,解析器在遇到=之前并不知道它正在解析左值。在一个复杂的左值中,这可能发生在许多标记之后。
makeList().head.next = node;
我们只有单个标记超前,那么该怎么做呢?我们使用一个小技巧,它看起来像这样
在expressionStatement()之后添加
private Expr assignment() { Expr expr = equality(); if (match(EQUAL)) { Token equals = previous(); Expr value = assignment(); if (expr instanceof Expr.Variable) { Token name = ((Expr.Variable)expr).name; return new Expr.Assign(name, value); } error(equals, "Invalid assignment target."); } return expr; }
解析赋值表达式的代码大部分与其他二元运算符(如+)类似。我们解析左侧,它可以是任何更高优先级的表达式。如果我们找到=,我们解析右侧,然后将其全部包装在一个赋值表达式树节点中。
与二元运算符的一个细微区别在于,我们不循环构建相同运算符的序列。由于赋值是右结合的,我们改为递归调用assignment()来解析右侧。
技巧在于,在我们创建赋值表达式树节点之前,我们查看左侧表达式,并确定它是哪种类型的赋值目标。我们将右值表达式节点转换为左值表示形式。
这种转换有效,因为事实证明,每个有效的赋值目标恰好也是有效的语法,作为普通表达式。考虑一个复杂的字段赋值,例如:
newPoint(x + 2, 0).y = 3;
该赋值的左侧也可以作为有效的表达式工作。
newPoint(x + 2, 0).y;
第一个示例设置了字段,第二个获取了它。
这意味着我们可以像对待表达式一样解析左侧,然后事后生成一个语法树,将其转换为赋值目标。如果左侧表达式不是一个有效的赋值目标,我们将使用语法错误失败。这确保了我们对以下代码报告错误:
a + b = c;
目前,唯一有效的目标是简单的变量表达式,但我们以后会添加字段。这个技巧的结果是一个赋值表达式树节点,它知道它正在分配给什么,并且有一个用于正在分配的值的表达式子树。所有这些都只需要一个标记超前,不需要回溯。
8 . 4 . 2赋值语义
我们有一个新的语法树节点,因此我们的解释器获得了一个新的访问方法。
在visitVarStmt()之后添加
@Override public Object visitAssignExpr(Expr.Assign expr) { Object value = evaluate(expr.value); environment.assign(expr.name, value); return value; }
出于显而易见的原因,它类似于变量声明。它求值右侧以获取值,然后将其存储在命名的变量中。它没有在Environment上使用define(),而是调用了这个新方法
在get()之后添加
void assign(Token name, Object value) { if (values.containsKey(name.lexeme)) { values.put(name.lexeme, value); return; } throw new RuntimeError(name, "Undefined variable '" + name.lexeme + "'."); }
赋值和定义之间的关键区别在于赋值不允许创建新的变量。在我们的实现中,这意味着如果环境的变量映射中不存在该键,则在运行时会报错。
visit() 方法最后返回的是赋值的值。这是因为赋值是一个表达式,可以嵌套在其他表达式中,例如
var a = 1; print a = 2; // "2".
我们的解释器现在可以创建、读取和修改变量了。它与早期 BASIC 语言一样复杂。全局变量很简单,但是当任何两个代码块都可以意外地踩到彼此的状态时,编写一个大型程序就没什么乐趣了。我们想要局部变量,这意味着是时候引入作用域了。
8 . 5作用域
作用域定义了一个区域,在这个区域中,一个名称映射到一个特定的实体。多个作用域允许同一个名称在不同的上下文中引用不同的内容。在我的房子里,“Bob” 通常指的是我。但在你的城镇里,你可能认识一个不同的 Bob。相同的名称,但由于你在哪里说它而有所不同。
词法作用域(或不常听到的静态作用域)是一种特定类型的作用域,其中程序本身的文本显示了作用域的开始和结束位置。在 Lox 中,就像大多数现代语言一样,变量是词法作用域的。当你看到一个使用某个变量的表达式时,你只需要静态地阅读代码就可以确定它指的是哪个变量声明。
例如
{
var a = "first";
print a; // "first".
}
{
var a = "second";
print a; // "second".
}
在这里,我们有两个块,每个块都声明了一个变量 a。你和我都能够从代码中看出,第一个 print 语句中使用 a 指的是第一个 a,第二个指的是第二个。

这与动态作用域形成对比,在动态作用域中,你不知道一个名称在执行代码之前指的是什么。Lox 没有动态作用域的变量,但对象的方法和字段是动态作用域的。
class Saxophone { play() { print "Careless Whisper"; } } class GolfClub { play() { print "Fore!"; } } fun playIt(thing) { thing.play(); }
当 playIt() 调用 thing.play() 时,我们不知道我们是否要听到“Careless Whisper”或“Fore!”。这取决于你传递给函数的是 Saxophone 还是 GolfClub,而我们直到运行时才知道这一点。
作用域和环境是近亲。前者是理论概念,后者是实现它的机制。当我们的解释器遍历代码时,影响作用域的语法树节点会改变环境。在像 Lox 这样的 C 式语法中,作用域由花括号括起来的块控制。(这就是为什么我们称之为块作用域)。
{
var a = "in block";
}
print a; // Error! No more "a".
一个块的开始引入了一个新的局部作用域,该作用域在执行传递闭合的 } 时结束。在块中声明的任何变量都会消失。
8 . 5 . 1嵌套和遮蔽
实现块作用域的第一步可能是这样的
-
当我们访问块中的每个语句时,跟踪声明的任何变量。
-
在最后一个语句执行之后,告诉环境删除所有这些变量。
这对于前面的例子来说是有效的。但是请记住,局部作用域的一个动机是封装—程序中一个角落的一块代码不应干扰其他块。请看这个例子
// How loud? var volume = 11; // Silence. volume = 0; // Calculate size of 3x4x5 cuboid. { var volume = 3 * 4 * 5; print volume; }
看看我们使用 volume 的局部声明来计算长方体体积的块。在块退出后,解释器将删除全局 volume 变量。这不是正确的。当我们退出块时,我们应该删除块内部声明的任何变量,但如果有一个在块外部声明的同名变量,这是一个不同的变量。它不应该被触碰。
当一个局部变量与外层作用域中的变量同名时,它会遮蔽外部变量。块内的代码再也看不见它了—它隐藏在内部变量投下的“阴影”中—但它仍然在那里。
当我们进入一个新的块作用域时,我们需要保留外层作用域中定义的变量,以便在我们退出内部块时它们仍然存在。我们通过为每个块定义一个新的环境来实现这一点,该环境只包含该作用域中定义的变量。当我们退出块时,我们丢弃它的环境并恢复上一个环境。
我们还需要处理未被遮蔽的外层变量。
var global = "outside"; { var local = "inside"; print global + local; }
这里,global 存在于外部全局环境中,local 在块的环境中定义。在 print 语句中,这两个变量都在作用域内。为了找到它们,解释器必须不仅搜索当前最内部的环境,还要搜索任何外层环境。
我们通过将环境链接在一起来实现这一点。每个环境都包含对立即外层环境的引用。当我们查找一个变量时,我们从最内部开始向外遍历这个链,直到找到这个变量。从内部作用域开始,就是我们使局部变量遮蔽外部变量的方式。
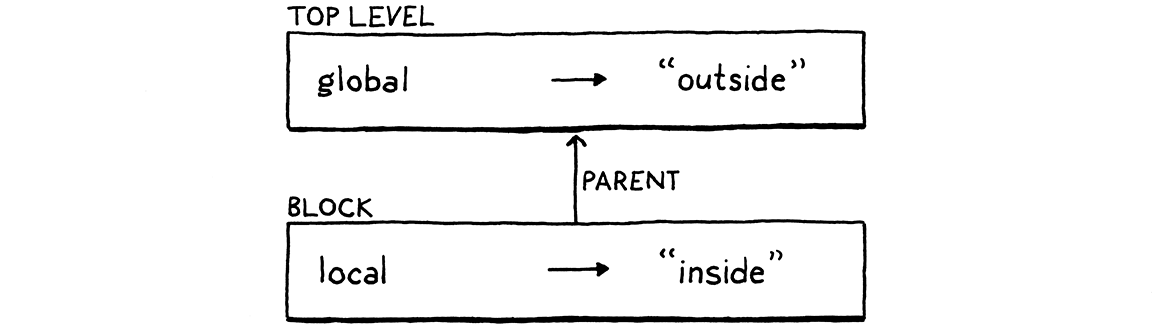
在我们将块语法添加到语法之前,我们将增强我们的 Environment 类,使其支持这种嵌套。首先,我们给每个环境添加一个对其外层环境的引用。
class Environment {
在 class Environment 中
final Environment enclosing;
private final Map<String, Object> values = new HashMap<>();
这个字段需要被初始化,所以我们添加了几个构造函数。
在 class Environment 中
Environment() { enclosing = null; } Environment(Environment enclosing) { this.enclosing = enclosing; }
无参数构造函数用于全局作用域的环境,它终止了链。另一个构造函数创建一个新的局部作用域,该作用域嵌套在给定的外部作用域中。
我们不必修改 define() 方法—新的变量总是声明在当前最内部的作用域中。但是变量查找和赋值使用的是现有变量,它们需要遍历链才能找到它们。首先,查找
return values.get(name.lexeme);
}
在 get() 中
if (enclosing != null) return enclosing.get(name);
throw new RuntimeError(name,
"Undefined variable '" + name.lexeme + "'.");
如果在该环境中没有找到变量,我们只需尝试外层环境。依次类推,这样最终会遍历整个链。如果我们到达一个没有外层环境的环境并且仍然没有找到变量,那么我们就放弃并像以前一样报告错误。
赋值的机制相同。
values.put(name.lexeme, value);
return;
}
在 assign() 中
if (enclosing != null) { enclosing.assign(name, value); return; }
throw new RuntimeError(name,
同样,如果变量不在该环境中,它会递归地检查外层环境。
8 . 5 . 2块语法和语义
现在环境嵌套了,我们准备将块添加到语言中。请看语法
statement → exprStmt | printStmt | block ; block → "{" declaration* "}" ;
一个块是一个(可能是空的)语句或声明序列,用花括号括起来。块本身是一个语句,可以出现在任何允许语句出现的位置。 语法树 节点如下所示
defineAst(outputDir, "Stmt", Arrays.asList(
在 main() 中
"Block : List<Stmt> statements",
"Expression : Expr expression",
它包含块内的语句列表。解析很简单。与其他语句一样,我们通过其开头的标记—在本例中为 {—来检测块的开始。在 statement() 方法中,我们添加
if (match(PRINT)) return printStatement();
在 statement() 中
if (match(LEFT_BRACE)) return new Stmt.Block(block());
return expressionStatement();
所有实际的工作都在这里完成
在expressionStatement()之后添加
private List<Stmt> block() { List<Stmt> statements = new ArrayList<>(); while (!check(RIGHT_BRACE) && !isAtEnd()) { statements.add(declaration()); } consume(RIGHT_BRACE, "Expect '}' after block."); return statements; }
我们创建一个空列表,然后解析语句并将它们添加到列表中,直到我们到达块的末尾,用闭合的 } 标记。请注意,循环还显式地检查了 isAtEnd()。我们必须小心,即使在解析无效代码时也要避免无限循环。如果用户忘记了闭合的 },解析器需要避免陷入困境。
这就是语法部分。对于语义,我们在 Interpreter 中添加另一个 visit 方法。
在 execute() 后添加
@Override public Void visitBlockStmt(Stmt.Block stmt) { executeBlock(stmt.statements, new Environment(environment)); return null; }
要执行一个块,我们为块的作用域创建一个新的环境,并将其传递给这个其他方法
在 execute() 后添加
void executeBlock(List<Stmt> statements, Environment environment) { Environment previous = this.environment; try { this.environment = environment; for (Stmt statement : statements) { execute(statement); } } finally { this.environment = previous; } }
这个新方法在一个给定的 环境 上下文中执行语句列表。到目前为止,Interpreter 中的 environment 字段始终指向同一个环境—全局环境。现在,该字段代表当前环境。它是与要执行的代码包含的最内部作用域相对应的环境。
要在一个给定作用域中执行代码,该方法会更新解释器的 environment 字段,访问所有语句,然后恢复以前的值。根据 Java 的最佳实践,它使用 finally 子句恢复以前的环境。这样,即使抛出异常,它也会被恢复。
令人惊讶的是,这是我们为了完全支持局部变量、嵌套和遮蔽而需要做的所有事情。现在就尝试一下吧
var a = "global a"; var b = "global b"; var c = "global c"; { var a = "outer a"; var b = "outer b"; { var a = "inner a"; print a; print b; print c; } print a; print b; print c; } print a; print b; print c;
我们的小解释器现在可以记住东西了。我们正在慢慢接近一个类似于功能齐全的编程语言的东西。
挑战
-
REPL 不再支持输入单个表达式并自动打印其结果值。这很糟糕。向 REPL 添加支持,允许用户输入语句和表达式。如果他们输入语句,则执行它。如果他们输入表达式,则对其进行求值并显示结果值。
-
也许你希望 Lox 在变量初始化方面更明确。与其隐式地将变量初始化为
nil,不如将其设置为运行时错误,以访问尚未初始化或赋值的变量,如// No initializers. var a; var b; a = "assigned"; print a; // OK, was assigned first. print b; // Error!
-
以下程序做什么?
var a = 1; { var a = a + 2; print a; }
你期待它做什么?它是否符合你的预期?你熟悉的其他语言中的类似代码做了什么?你认为用户会期望它做什么?
设计说明:隐式变量声明
Lox 在声明新变量和为现有变量赋值方面具有不同的语法。 一些语言将这些语法合并成仅赋值语法。 为不存在的变量赋值会自动创建该变量。 这就是所谓的 **隐式变量声明**,它存在于 Python、Ruby 和 CoffeeScript 等语言中。 JavaScript 具有显式声明变量的语法,但也可以在赋值时创建新变量。 Visual Basic 有 一个选项可以启用或禁用隐式变量。
当相同的语法可以赋值或创建变量时,每种语言都必须决定在不清楚用户意图的情况下会发生什么。 特别是,每种语言都必须选择隐式声明如何与遮蔽交互,以及隐式声明的变量进入哪个作用域。
-
在 Python 中,赋值始终在当前函数的作用域内创建一个变量,即使在函数外部声明了具有相同名称的变量。
-
Ruby 通过对局部变量和全局变量采用不同的命名规则来避免一些歧义。 但是,Ruby 中的块(更像是闭包,而不是 C 中的“块”)有自己的作用域,所以它仍然存在这个问题。 在 Ruby 中,如果存在具有相同名称的变量,则赋值会将值赋给当前块之外的现有变量。 否则,它会在当前块的作用域内创建一个新变量。
-
CoffeeScript 在很多方面借鉴了 Ruby,与之类似。 它明确地禁止了遮蔽,方法是说赋值始终将值赋给外部作用域中的变量(如果存在),一直到最外层的全局作用域。 否则,它会在当前函数作用域内创建变量。
-
在 JavaScript 中,赋值会修改任何包含作用域中的现有变量(如果找到)。 如果没有,它会在 *全局* 作用域中隐式地创建一个新变量。
隐式声明的主要优点是简单。 语法更少,也没有“声明”的概念需要学习。 用户可以只开始赋值,语言会自动搞定。
像 C 这样的旧的静态类型语言受益于显式声明,因为它们为用户提供了一个地方来告诉编译器每个变量的类型以及为其分配多少存储空间。 在动态类型、垃圾回收语言中,这实际上是不必要的,因此您可以通过使声明隐式来避免它。 这感觉更像“脚本”,更像“你知道我的意思”。
但这是一个好主意吗? 隐式声明存在一些问题。
-
用户可能打算将值赋给一个现有变量,但可能拼错了。 解释器不知道这一点,因此它会继续默默地创建一些新变量,用户想要赋值的变量仍然保留其旧值。 这在 JavaScript 中尤其令人讨厌,因为打字错误会创建一个 *全局* 变量,这可能会干扰其他代码。
-
JS、Ruby 和 CoffeeScript 使用存在具有相同名称的现有变量(即使在外部作用域)来确定赋值是创建一个新变量还是为现有变量赋值。 这意味着在周围作用域中添加一个新变量会改变现有代码的含义。 曾经的局部变量可能会默默地变成对该新外部变量的赋值。
-
在 Python 中,你可能 *想要* 将值赋给当前函数外部的某个变量,而不是在当前函数内创建一个新变量,但你不能。
随着时间的推移,我知道的具有隐式变量声明的语言最终添加了更多功能和复杂性来解决这些问题。
-
如今,JavaScript 中全局变量的隐式声明被普遍认为是一个错误。 “严格模式”禁用了它,并将其变成一个编译错误。
-
Python 添加了一个
global语句,让你可以从函数内部显式地将值赋给全局变量。 后来,随着函数式编程和嵌套函数变得越来越流行,他们添加了一个类似的nonlocal语句来将值赋给包含函数中的变量。 -
Ruby 扩展了其块语法,允许声明某些变量显式地局部于块,即使在外部作用域中存在相同的名称。
考虑到这些,我认为简洁性的论点大部分都消失了。 有一种观点认为隐式声明是正确的 *默认*,但我个人认为这种说法没有说服力。
我的观点是,在过去,当大多数脚本语言都是高度命令式的,代码相当平坦时,隐式声明是有意义的。 随着程序员越来越习惯于深度嵌套、函数式编程和闭包,他们越来越想访问外部作用域中的变量。 这使得用户更有可能遇到难以判断是打算创建新变量还是重用周围变量的棘手情况。
所以,我更喜欢显式声明变量,这也是 Lox 要求这样做的原因。