垃圾回收
我想要,我想要,
我想要,我想要,
我想要成为垃圾。The Whip,“Trash”
我们说 Lox 是一种“高级”语言,因为它解放了程序员,让他们不必再担心与他们正在解决的问题无关的细节。用户成为了管理者,向机器下达抽象目标,并让底层的计算机去弄清楚如何实现这些目标。
动态内存分配是自动化执行的完美候选。它对于一个正常工作的程序是必要的,手工执行既繁琐又容易出错。不可避免的错误会造成灾难性的后果,导致崩溃、内存损坏或安全漏洞。这是机器擅长而人类却感到厌烦的既有风险又乏味的工作。
这就是为什么 Lox 是一种托管语言,这意味着语言实现会代表用户管理内存分配和释放。当用户执行需要动态内存的操作时,VM 会自动分配内存。程序员不必担心释放任何内存。机器会确保程序正在使用的任何内存都在需要时保持可用。
Lox 营造了一种错觉,让计算机仿佛拥有无限的内存。用户可以不断分配内存,而无需考虑所有这些字节来自何处。当然,计算机还没有真正拥有无限的内存。因此,托管语言维护这种错觉的方式是,在程序员背后默默地回收程序不再需要的内存。执行此操作的组件称为垃圾回收器。
26 . 1可达性
这提出了一个令人惊讶地难以回答的问题:VM 如何判断哪些内存不需要?内存只有在将来被读取时才需要,但除了拥有时光机,实现如何才能判断程序将会执行哪些代码以及将会使用哪些数据?剧透一下:VM 无法穿越时空。相反,语言做了一个保守的近似:它认为,如果内存可能在将来被读取,则该内存仍然在使用中。
这听起来过于保守。难道内存的任何位都可能被读取吗?实际上,至少在像 Lox 这样的内存安全语言中,情况并非如此。以下是一个例子
var a = "first value"; a = "updated"; // GC here. print a;
假设我们在第二行的赋值完成后运行 GC。字符串“first value”仍然驻留在内存中,但用户程序无法以任何方式访问它。一旦 a 被重新赋值,程序就失去了对该字符串的任何引用。我们可以安全地将其释放。如果用户程序可以以某种方式引用某个值,则该值是可达的。否则,就像这里的字符串“first value”一样,它是不可达的。
许多值可以直接由 VM 访问。看看以下代码
var global = "string"; { var local = "another"; print global + local; }
在两个字符串连接后,但 print 语句执行之前,暂停程序。VM 可以通过查看全局变量表,找到 global 的条目,从而访问 "string"。它可以通过遍历值栈,找到 local 局部变量的槽位,从而访问 "another"。它甚至可以访问连接后的字符串 "stringanother",因为该临时值也在我们暂停程序时位于 VM 的栈上。
所有这些值都称为根节点。根节点是 VM 可以直接访问,而无需经过其他对象中的引用即可访问的任何对象。大多数根节点是全局变量或位于栈上,但正如我们将看到的,VM 还将一些对象引用存储在其他地方。
其他值可以通过另一个值内部的引用找到。字段是类实例中最明显的案例,但我们还没有实现它们。即使没有它们,我们的 VM 仍然具有间接引用。考虑以下代码
fun makeClosure() { var a = "data"; fun f() { print a; } return f; } { var closure = makeClosure(); // GC here. closure(); }
假设我们在标记行暂停程序并运行垃圾回收器。当收集器完成,程序恢复时,它会调用闭包,闭包反过来会打印 "data"。所以,收集器需要不释放该字符串。但当我们暂停程序时,栈是这样的

"data" 字符串不在栈上。它已经被从栈上提升,并移动到闭包使用的闭包上值数组中。闭包本身位于栈上。但要访问该字符串,我们需要遍历闭包及其上值数组。由于用户程序可以这样做,所以所有这些间接可访问的对象也被视为可达的。
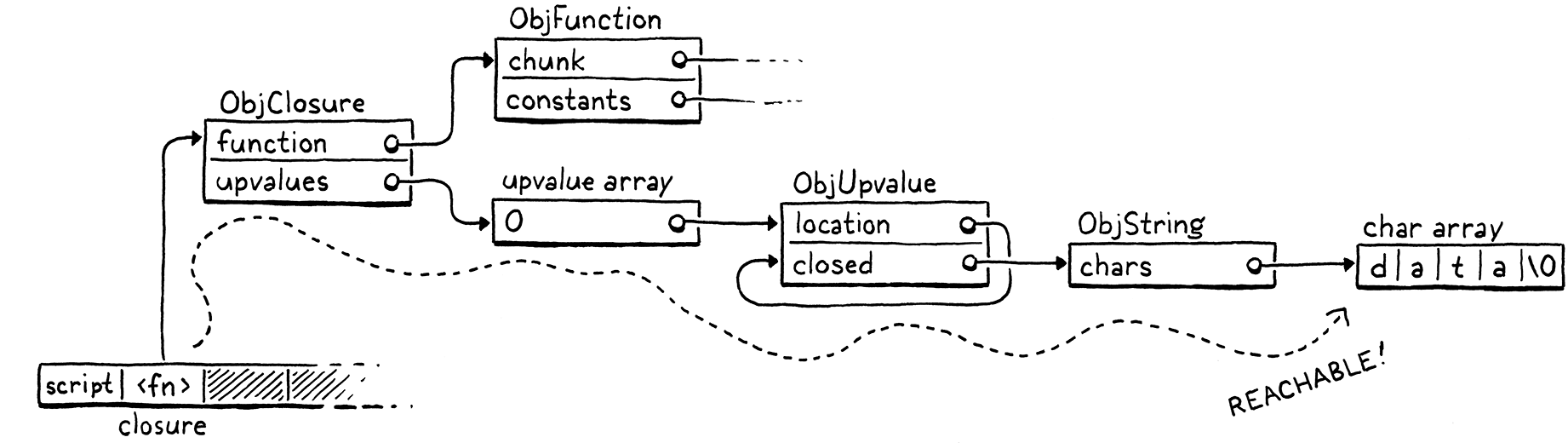
这为我们提供了一个可达性的归纳定义
-
所有根节点都是可达的。
-
从可达对象引用的任何对象本身也是可达的。
这些是仍然“存活”的需要保留在内存中的值。任何不满足此定义的值都可以由收集器回收。这对递归规则暗示了我们可以用来释放不需要的内存的递归算法
-
从根节点开始,遍历对象引用,找到所有可达对象的完整集合。
-
释放该集合中不存在的任何对象。
当今使用着许多不同的垃圾回收算法,但它们都大致遵循相同的结构。有些算法可能交织执行步骤或混合步骤,但两个基本操作是相同的。它们主要区别在于执行每个步骤的方式。
26 . 2标记-清除垃圾回收
第一种托管语言是 Lisp,它是继 Fortran 之后发明的第二种“高级”语言。John McCarthy 考虑过使用手动内存管理或引用计数,但他最终决定使用(并创造了)垃圾回收—一旦程序内存不足,它会返回并查找可以回收的未使用存储空间。
他设计了第一个也是最简单的垃圾回收算法,称为标记-清除或简称标记-清除。它的描述在 Lisp 的最初论文中用三个简短的段落概括。尽管它古老而简单,但相同的基本算法是许多现代内存管理器的基础。CS 的某些领域似乎是永恒的。
顾名思义,标记-清除算法分为两个阶段
-
标记阶段:我们从根节点开始,遍历或跟踪所有这些根节点引用的对象。这是对所有可达对象的经典图遍历。每次访问一个对象时,我们都会标记它。(实现之间在记录标记的方式上有所不同。)
-
清除阶段:一旦标记阶段完成,堆中的所有可达对象都将被标记。这意味着任何未标记的对象都是不可达的,可以进行回收。我们遍历所有未标记的对象,并释放每个对象。
它看起来像这样
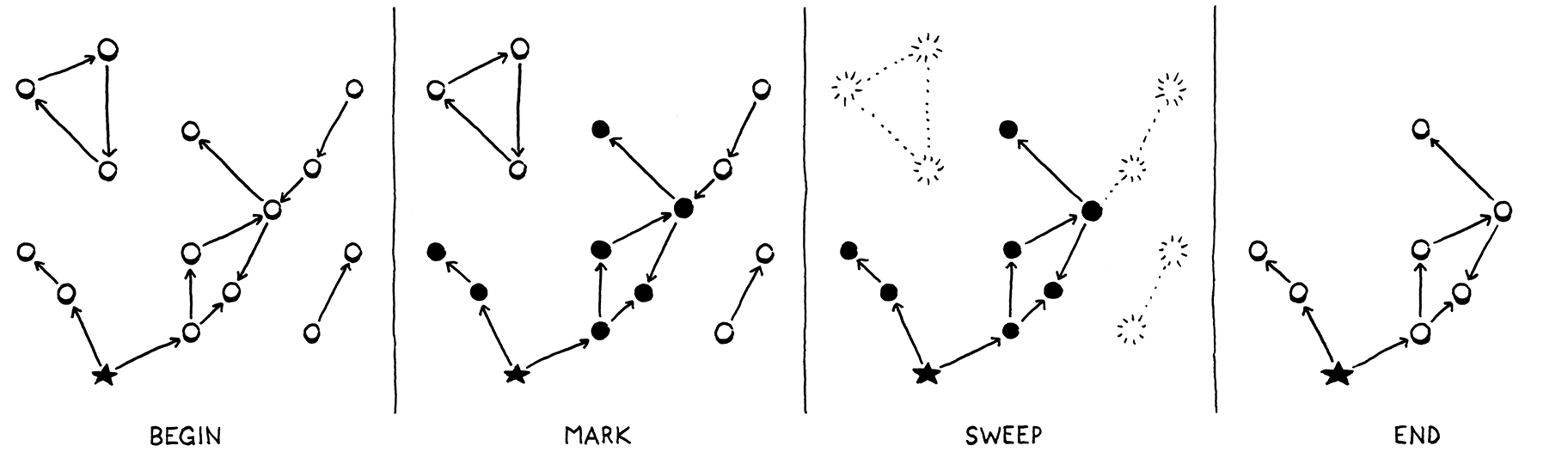
这就是我们将要实现的。每当我们决定回收一些字节时,我们都会跟踪所有内容,标记所有可达对象,释放未标记的内容,然后恢复用户的程序。
26 . 2 . 1回收垃圾
整章都是关于实现这个函数
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
在 reallocate() 之后添加
void collectGarbage();
void freeObjects();
我们将从这个空壳开始逐步构建一个完整的实现
在 freeObject() 之后添加
void collectGarbage() { }
你可能会问的第一个问题是,这个函数何时被调用?事实证明,这是一个微妙的问题,我们将在本章稍后花一些时间讨论。现在,我们将回避这个问题,并在过程中构建一个方便的诊断工具。
#define DEBUG_TRACE_EXECUTION
#define DEBUG_STRESS_GC
#define UINT8_COUNT (UINT8_MAX + 1)
我们将为垃圾回收器添加一个可选的“压力测试”模式。当此标志被定义时,GC 会尽可能频繁地运行。显然,这对性能来说是灾难性的。但它非常适合找出只在 GC 在特定时间触发时才会出现的内存管理错误。如果每个时间都触发 GC,那么你很可能会找到这些错误。
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
在 reallocate() 中
if (newSize > oldSize) { #ifdef DEBUG_STRESS_GC collectGarbage(); #endif }
if (newSize == 0) {
每当我们调用 reallocate() 来获取更多内存时,我们都会强制运行收集。if 检查的原因是 reallocate() 也被用来释放或缩小分配。我们不想为此触发 GC—特别是由于 GC 本身会调用 reallocate() 来释放内存。
在分配之前进行收集是将 GC 连接到 VM 的经典方法。你已经在调用内存管理器,因此这是一个方便的挂钩点。此外,分配是你真正需要一些释放内存以便重用的唯一时间。如果你不使用分配来触发 GC,你必须确保可以循环分配内存的每个代码位置都有一种触发收集器的方法。否则,VM 可能会进入一种饥饿状态,它需要更多内存,但永远无法收集任何内存。
26 . 2 . 2调试日志
既然我们谈论诊断,让我们添加更多内容。我在垃圾收集器中发现的一个真正的挑战是它们不透明。到目前为止,我们一直在运行大量 Lox 程序,这些程序没有使用任何 GC。一旦我们添加了它,我们如何判断它是否有用?只有当我们编写耗尽大量内存的程序时才能知道吗?我们如何调试它呢?
一个照亮 GC 内部工作原理的简单方法是使用一些日志记录。
#define DEBUG_STRESS_GC
#define DEBUG_LOG_GC
#define UINT8_COUNT (UINT8_MAX + 1)
启用此功能后,clox 会在处理动态内存时将信息打印到控制台。
我们需要几个包含项。
#include "vm.h"
#ifdef DEBUG_LOG_GC #include <stdio.h> #include "debug.h" #endif
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
我们还没有收集器,但现在可以开始添加一些日志记录。我们想了解何时开始收集运行。
void collectGarbage() {
在 collectGarbage() 中
#ifdef DEBUG_LOG_GC printf("-- gc begin\n"); #endif
}
最终,我们将在收集过程中记录一些其他操作,因此我们还想了解何时结束。
printf("-- gc begin\n");
#endif
在 collectGarbage() 中
#ifdef DEBUG_LOG_GC printf("-- gc end\n"); #endif
}
我们还没有收集器的代码,但我们有用于分配和释放的函数,因此现在可以对它们进行检测。
vm.objects = object;
在 allocateObject() 中
#ifdef DEBUG_LOG_GC printf("%p allocate %zu for %d\n", (void*)object, size, type); #endif
return object;
以及在对象生命周期结束时
static void freeObject(Obj* object) {
在 freeObject() 中
#ifdef DEBUG_LOG_GC printf("%p free type %d\n", (void*)object, object->type); #endif
switch (object->type) {
使用这两个标志,我们应该能够看到我们在完成本章剩余部分时取得了进展。
26 . 3标记根节点
对象像夜空中闪烁的星星一样散布在堆中。一个对象到另一个对象的引用形成一个连接,这些星座就是标记阶段遍历的图。标记从根节点开始。
#ifdef DEBUG_LOG_GC
printf("-- gc begin\n");
#endif
在 collectGarbage() 中
markRoots();
#ifdef DEBUG_LOG_GC
大多数根节点是直接位于 VM 栈中的局部变量或临时变量,因此我们从遍历它开始。
在 freeObject() 之后添加
static void markRoots() { for (Value* slot = vm.stack; slot < vm.stackTop; slot++) { markValue(*slot); } }
为了标记 Lox 值,我们使用这个新函数
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
在 reallocate() 之后添加
void markValue(Value value);
void collectGarbage();
它的实现在这里
在 reallocate() 之后添加
void markValue(Value value) { if (IS_OBJ(value)) markObject(AS_OBJ(value)); }
一些 Lox 值—数字、布尔值和 nil—直接存储在 Value 中,不需要堆分配。垃圾收集器根本不需要担心它们,因此我们首先要确保该值是一个实际的堆对象。如果是,则实际工作将在以下函数中进行
void* reallocate(void* pointer, size_t oldSize, size_t newSize);
在 reallocate() 之后添加
void markObject(Obj* object);
void markValue(Value value);
它在以下位置定义
在 reallocate() 之后添加
void markObject(Obj* object) { if (object == NULL) return; object->isMarked = true; }
当从 markValue() 调用时,NULL 检查是不必要的。作为某种 Obj 类型的 Lox 值将始终具有有效的指针。但稍后我们将直接从其他代码中调用此函数,在其中一些地方,所指向的对象是可选的。
假设我们确实有一个有效的对象,我们将通过设置一个标志来标记它。该新字段位于所有对象共享的 Obj 标头结构体中。
ObjType type;
在结构体 Obj 中
bool isMarked;
struct Obj* next;
每个新对象在创建时都是未标记的,因为我们还没有确定它是否可达。
object->type = type;
在 allocateObject() 中
object->isMarked = false;
object->next = vm.objects;
在我们继续之前,让我们在 markObject() 中添加一些日志记录。
void markObject(Obj* object) {
if (object == NULL) return;
在 markObject() 中
#ifdef DEBUG_LOG_GC printf("%p mark ", (void*)object); printValue(OBJ_VAL(object)); printf("\n"); #endif
object->isMarked = true;
这样,我们可以看到标记阶段在做什么。标记栈会处理局部变量和临时变量。另一个主要的根节点来源是全局变量。
markValue(*slot); }
在 markRoots() 中
markTable(&vm.globals);
}
这些变量驻留在 VM 所拥有的哈希表中,因此我们将为标记表中所有对象声明另一个辅助函数。
ObjString* tableFindString(Table* table, const char* chars,
int length, uint32_t hash);
在 tableFindString() 之后添加
void markTable(Table* table);
#endif
我们在“table”模块中实现它
在 tableFindString() 之后添加
void markTable(Table* table) { for (int i = 0; i < table->capacity; i++) { Entry* entry = &table->entries[i]; markObject((Obj*)entry->key); markValue(entry->value); } }
非常简单。我们遍历条目数组。对于每个条目,我们标记其值。我们还标记每个条目的键字符串,因为 GC 也管理这些字符串。
26 . 3 . 1不太明显的根节点
这些涵盖了我们通常想到的根节点—用户程序可以看见的存储在变量中的值,这些值显然是可达的。但是 VM 还有一些它自己的隐藏的地方,它在那里隐藏对它直接访问的值的引用。
大多数函数调用状态都驻留在值栈中,但 VM 维护一个单独的 CallFrame 栈。每个 CallFrame 都包含一个指向正在调用的闭包的指针。VM 使用这些指针访问常量和向上值,因此这些闭包也需要保留。
}
在 markRoots() 中
for (int i = 0; i < vm.frameCount; i++) { markObject((Obj*)vm.frames[i].closure); }
markTable(&vm.globals);
说到向上值,开放的向上值列表是 VM 可以直接访问的另一组值。
for (int i = 0; i < vm.frameCount; i++) {
markObject((Obj*)vm.frames[i].closure);
}
在 markRoots() 中
for (ObjUpvalue* upvalue = vm.openUpvalues; upvalue != NULL; upvalue = upvalue->next) { markObject((Obj*)upvalue); }
markTable(&vm.globals);
请记住,收集可以在任何分配期间开始。这些分配不仅仅发生在用户程序运行时。编译器本身会定期从堆中获取内存,用于文字和常量表。如果 GC 在我们编译过程中运行,那么编译器直接访问的任何值都需要被视为根节点。
为了使编译器模块与 VM 的其余部分保持清晰分离,我们将在单独的函数中进行此操作。
markTable(&vm.globals);
在 markRoots() 中
markCompilerRoots();
}
它在以下位置声明
ObjFunction* compile(const char* source);
在 compile() 之后添加
void markCompilerRoots();
#endif
这意味着“memory”模块需要包含以下内容。
#include <stdlib.h>
#include "compiler.h"
#include "memory.h"
定义位于“compiler”模块中。
在 compile() 之后添加
void markCompilerRoots() { Compiler* compiler = current; while (compiler != NULL) { markObject((Obj*)compiler->function); compiler = compiler->enclosing; } }
幸运的是,编译器没有太多它坚持的值。它使用的唯一对象是它正在编译到的 ObjFunction。由于函数声明可以嵌套,因此编译器有一个这些对象的链表,我们遍历整个链表。
由于“compiler”模块正在调用 markObject(),因此它还需要包含以下内容。
#include "compiler.h"
#include "memory.h"
#include "scanner.h"
这些是所有根节点。运行完此操作后,VM(运行时和编译器)可以通过不经过其他对象就能访问的每个对象都设置了其标记位。
26 . 4跟踪对象引用
标记过程的下一步是跟踪对象之间引用的图,以查找间接可达的值。我们还没有带字段的实例,因此没有太多包含引用的对象,但我们确实有一些。特别是,ObjClosure 拥有它闭包的 ObjUpvalues 列表,以及对它包装的原始 ObjFunction 的引用。ObjFunction 反过来又有一个常量表,其中包含对在函数体中创建的所有文字的引用。这足以构建一个相当复杂的网络,让我们的收集器可以遍历。
现在是实现遍历的时候了。我们可以进行广度优先、深度优先,或者以其他顺序进行。由于我们只需要找到所有可达对象的集合,因此我们访问它们的顺序大多无关紧要。
26 . 4 . 1三色抽象
当收集器在对象图中漫游时,我们需要确保它不会失去方向或陷入循环中。对于像增量 GC 这样的高级实现,它们会将标记与用户程序的运行部分交织在一起,这尤其令人担忧。收集器需要能够暂停,然后在稍后恢复到它停止的地方。
为了帮助我们这些脑筋简单的凡人理解这个复杂的过程,VM 黑客想出了一个名为三色抽象的比喻。每个对象都有一个概念上的“颜色”,用于跟踪对象处于什么状态以及还有哪些工作要做。
-
 白色:在垃圾收集开始时,每个对象都是白色的。此颜色意味着我们还没有到达或处理该对象。
白色:在垃圾收集开始时,每个对象都是白色的。此颜色意味着我们还没有到达或处理该对象。 -
 灰色:在标记期间,当我们第一次到达某个对象时,我们会将其变为灰色。此颜色意味着我们知道对象本身是可达的,不应该被收集。但我们还没有通过它进行跟踪,以查看它引用了哪些其他对象。用图算法的术语来说,这就是工作列表—我们知道的但尚未处理的对象集。
灰色:在标记期间,当我们第一次到达某个对象时,我们会将其变为灰色。此颜色意味着我们知道对象本身是可达的,不应该被收集。但我们还没有通过它进行跟踪,以查看它引用了哪些其他对象。用图算法的术语来说,这就是工作列表—我们知道的但尚未处理的对象集。 -
 黑色:当我们取一个灰色对象并标记它引用的所有对象时,我们会将该灰色对象变为黑色。此颜色意味着标记阶段已经完成处理该对象。
黑色:当我们取一个灰色对象并标记它引用的所有对象时,我们会将该灰色对象变为黑色。此颜色意味着标记阶段已经完成处理该对象。
根据这个抽象,标记过程现在看起来像这样
-
从所有对象都是白色开始。
-
找到所有根节点并将其标记为灰色。
-
只要还有灰色对象,就重复执行以下操作
-
选择一个灰色对象。将该对象所提及的任何白色对象变为灰色。
-
将原始的灰色对象标记为黑色。
-
我发现可视化它会有所帮助。你有一个带有引用之间的对象网络。最初,它们都是白色的小点。在旁边有一些来自 VM 的传入边指向根节点。这些根节点变为灰色。然后每个灰色对象的兄弟节点都变为灰色,而对象本身变为黑色。整个效果是一波灰色的波前穿过图,在它身后留下一个可达的黑色对象区域。不可达的对象不会被波前触及,并保持白色。

在结束时,你将留下一个由可达的黑色对象组成的海洋,其中散布着可以清除和释放的白色对象岛屿。一旦不可达的对象被释放,剩余的对象(所有黑色对象)将被重置为白色,以便进行下一个垃圾收集周期。
26 . 4 . 2灰色对象的工作列表
在我们的实现中,我们已经标记了根节点。它们都是灰色的。下一步是开始选取它们并遍历它们的引用。但我们没有简单的方法来找到它们。我们在对象上设置了一个字段,但仅此而已。我们不希望必须遍历整个对象列表来寻找设置了该字段的对象。
相反,我们将创建一个单独的工作列表来跟踪所有灰色的对象。当一个对象变成灰色时,除了设置标记字段之外,我们还会将它添加到工作列表中。
object->isMarked = true;
在 markObject() 中
if (vm.grayCapacity < vm.grayCount + 1) { vm.grayCapacity = GROW_CAPACITY(vm.grayCapacity); vm.grayStack = (Obj**)realloc(vm.grayStack, sizeof(Obj*) * vm.grayCapacity); } vm.grayStack[vm.grayCount++] = object;
}
我们可以使用任何类型的数据结构,只要它允许我们轻松地添加和取出项目即可。我选择了一个堆栈,因为这是在 C 中使用动态数组最简单的实现方式。它在很大程度上与我们在 Lox 中构建的其他动态数组类似,除了它调用了系统realloc()函数,而不是我们自己的reallocate()包装器。灰色堆栈本身的内存不由垃圾收集器管理。我们不希望在 GC 期间扩展灰色堆栈会导致 GC 递归地启动新的 GC。这可能会在时空连续体中撕开一个洞。
我们将显式地自己管理它的内存。虚拟机拥有灰色堆栈。
Obj* objects;
在 struct VM 中
int grayCount; int grayCapacity; Obj** grayStack;
} VM;
它最初是空的。
vm.objects = NULL;
在 initVM() 中
vm.grayCount = 0; vm.grayCapacity = 0; vm.grayStack = NULL;
initTable(&vm.globals);
当虚拟机关闭时,我们需要释放它。
object = next; }
在 freeObjects() 中
free(vm.grayStack);
}
我们对这个数组负全部责任。包括分配失败。如果我们无法创建或扩展灰色堆栈,那么我们就无法完成垃圾收集。这对虚拟机来说是个坏消息,但幸运的是,这种情况很少见,因为灰色堆栈往往很小。做一些更优雅的事情会很好,但是为了保持本书中的代码简单,我们只是中止了。
vm.grayStack = (Obj**)realloc(vm.grayStack,
sizeof(Obj*) * vm.grayCapacity);
在 markObject() 中
if (vm.grayStack == NULL) exit(1);
}
26 . 4 . 3处理灰色对象
好的,现在当我们完成根节点的标记后,我们已经设置了许多字段并用要处理的对象填充了我们的工作列表。现在是下一阶段了。
markRoots();
在 collectGarbage() 中
traceReferences();
#ifdef DEBUG_LOG_GC
这是实现
在 markRoots() 之后添加
static void traceReferences() { while (vm.grayCount > 0) { Obj* object = vm.grayStack[--vm.grayCount]; blackenObject(object); } }
它尽可能接近文本算法。直到堆栈为空,我们才会不断取出灰色的对象,遍历它们的引用,然后将它们标记为黑色。遍历对象的引用可能会发现新的白色的对象,这些对象会被标记为灰色并添加到堆栈中。因此,这个函数在将白色的对象变成灰色和将灰色的对象变成黑色之间来回切换,逐渐将整个波前推进。
这是我们遍历单个对象引用的地方
在 markValue() 之后添加
static void blackenObject(Obj* object) { switch (object->type) { case OBJ_NATIVE: case OBJ_STRING: break; } }
每个对象类型都有不同的字段,这些字段可能引用其他对象,因此我们需要为每种类型编写特定的代码块。我们从简单的开始—字符串和原生函数对象不包含任何传出引用,因此不需要遍历。
请注意,我们不会在遍历的对象本身中设置任何状态。对象的 state 中没有对“黑色”的直接编码。黑色对象是任何isMarked字段已设置并且不再位于灰色堆栈中的对象。
现在让我们开始添加其他对象类型。最简单的是 upvalues。
static void blackenObject(Obj* object) {
switch (object->type) {
在 blackenObject() 中
case OBJ_UPVALUE: markValue(((ObjUpvalue*)object)->closed); break;
case OBJ_NATIVE:
当一个 upvalue 被闭包时,它包含对闭包值的引用。由于该值不再位于堆栈上,我们需要确保我们从 upvalue 跟踪对它的引用。
接下来是函数。
switch (object->type) {
在 blackenObject() 中
case OBJ_FUNCTION: { ObjFunction* function = (ObjFunction*)object; markObject((Obj*)function->name); markArray(&function->chunk.constants); break; }
case OBJ_UPVALUE:
每个函数都引用一个包含函数名称的 ObjString。更重要的是,函数有一个常量表,其中包含指向其他对象的引用。我们使用这个辅助函数来跟踪所有这些引用
在 markValue() 之后添加
static void markArray(ValueArray* array) { for (int i = 0; i < array->count; i++) { markValue(array->values[i]); } }
我们现在拥有的最后一个对象类型—我们将在后面的章节中添加更多—是闭包。
switch (object->type) {
在 blackenObject() 中
case OBJ_CLOSURE: { ObjClosure* closure = (ObjClosure*)object; markObject((Obj*)closure->function); for (int i = 0; i < closure->upvalueCount; i++) { markObject((Obj*)closure->upvalues[i]); } break; }
case OBJ_FUNCTION: {
每个闭包都引用它包装的裸函数,以及指向它捕获的 upvalues 的指针数组。我们跟踪所有这些。
这就是处理灰色对象的机制,但还有两个细节需要解决。首先,一些日志记录。
static void blackenObject(Obj* object) {
在 blackenObject() 中
#ifdef DEBUG_LOG_GC printf("%p blacken ", (void*)object); printValue(OBJ_VAL(object)); printf("\n"); #endif
switch (object->type) {
这样,我们可以观察跟踪在对象图中传播。说到对象图,请注意我说的是图。对象之间的引用是有方向的,但这并不意味着它们是无环的!完全有可能存在对象的循环。当这种情况发生时,我们需要确保我们的收集器不会陷入无限循环,因为它会不断地将同一系列对象重新添加到灰色堆栈中。
修复很简单。
if (object == NULL) return;
在 markObject() 中
if (object->isMarked) return;
#ifdef DEBUG_LOG_GC
如果对象已经被标记,我们不再标记它,因此也不会将它添加到灰色堆栈中。这确保了已经灰色的对象不会被冗余地添加,黑色的对象不会被无意间变成灰色。换句话说,它使波前只穿过白色的对象而不断前进。
26 . 5清除未使用的对象
当 traceReferences() 中的循环退出时,我们已经处理了所有我们能够获取的对象。灰色堆栈是空的,堆中的每个对象要么是黑色的,要么是白色的。黑色的对象是可以访问的,我们想要保留它们。任何仍然是白色的对象都没有被跟踪触碰,因此是垃圾。剩下的就是回收它们。
traceReferences();
在 collectGarbage() 中
sweep();
#ifdef DEBUG_LOG_GC
所有逻辑都存在于一个函数中。
在 traceReferences() 之后添加
static void sweep() { Obj* previous = NULL; Obj* object = vm.objects; while (object != NULL) { if (object->isMarked) { previous = object; object = object->next; } else { Obj* unreached = object; object = object->next; if (previous != NULL) { previous->next = object; } else { vm.objects = object; } freeObject(unreached); } } }
我知道这有点代码和指针技巧,但一旦你理清思路,它就没有什么难度了。外部 while 循环遍历堆中每个对象的链表,检查它们的标记位。如果一个对象被标记(黑色),我们就不管它,继续遍历它。如果它没有被标记(白色),我们把它从链表中解除链接并使用我们已经编写的 freeObject() 函数释放它。
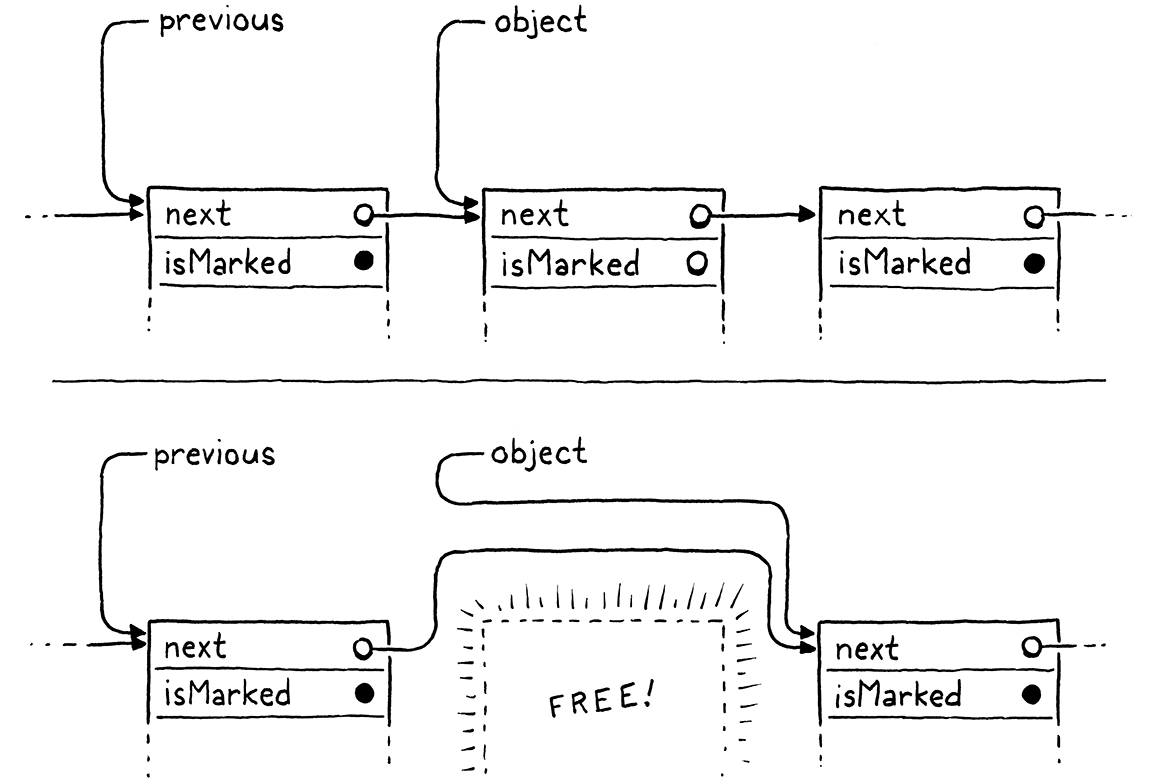
这里的其他代码大多是关于从单链表中删除节点很麻烦的事实。我们必须不断记住上一个节点,以便我们可以解除链接它的下一个指针,并且我们必须处理我们正在释放第一个节点的边缘情况。但是,除此之外,它非常简单—删除链表中没有设置位的每个节点。
这里有一个小补充
if (object->isMarked) {
在 sweep() 中
object->isMarked = false;
previous = object;
sweep() 完成后,唯一剩下的对象就是带有已设置标记位的黑色对象。这是正确的,但当下一个收集周期开始时,我们需要每个对象都是白色的。因此,每当我们遇到一个黑色的对象时,我们都会提前清除该位,以备下次运行。
26 . 5 . 1弱引用和字符串池
我们快完成收集了。虚拟机中还有一个角落对内存有一些特殊的要求。回想一下,当我们将字符串添加到 clox 时,我们让虚拟机将它们全部内部化。这意味着虚拟机有一个哈希表,其中包含指向堆中每个字符串的指针。虚拟机使用它来对字符串进行重复数据删除。
在标记阶段,我们故意不将虚拟机的字符串表视为根节点的来源。如果我们这样做,那么字符串将永远不会被收集。字符串表会越来越大,永远不会将一个字节的内存返回给操作系统。那会很糟糕。
同时,如果我们确实让 GC 释放字符串,那么虚拟机的字符串表将只剩下指向已释放内存的悬空指针。那会更糟。
字符串表是特殊的,我们需要为它提供特殊支持。特别是,它需要一种特殊类型的引用。该表应该能够引用一个字符串,但该链接在确定可访问性时不应该被视为根节点。这意味着引用的对象可以被释放。当这种情况发生时,悬空引用也必须被修复,有点像魔术,自清除指针。这种特殊的语义集出现得足够频繁,因此它有一个名称:弱引用.
我们已经通过我们在标记期间不遍历它而隐式地实现了字符串表独特行为的一半。这意味着它不会强迫字符串变得可访问。剩下的部分是清除对已释放字符串的任何悬空指针。
为了删除对不可访问字符串的引用,我们需要知道哪些字符串是不可访问的。在标记阶段完成之前,我们不知道这一点。但我们不能等到清除阶段完成之后,因为到那时,对象—及其标记位—将不再存在供检查。所以正确的时间就在标记和清除阶段之间。
traceReferences();
在 collectGarbage() 中
tableRemoveWhite(&vm.strings);
sweep();
删除即将被删除的字符串的逻辑存在于“表”模块中的一个新函数中。
ObjString* tableFindString(Table* table, const char* chars,
int length, uint32_t hash);
在 tableFindString() 之后添加
void tableRemoveWhite(Table* table);
void markTable(Table* table);
实现如下
在 tableFindString() 之后添加
void tableRemoveWhite(Table* table) { for (int i = 0; i < table->capacity; i++) { Entry* entry = &table->entries[i]; if (entry->key != NULL && !entry->key->obj.isMarked) { tableDelete(table, entry->key); } } }
我们遍历表中的每个条目。字符串内部化表只使用每个条目的键—它基本上是一个哈希集,而不是哈希映射。如果键字符串对象的标记位没有设置,那么它是一个白色的对象,它将在不久的将来被清除。我们首先从哈希表中删除它,从而确保我们不会看到任何悬空指针。
26 . 6何时收集
我们现在拥有了一个功能完备的标记-清除垃圾收集器。当压力测试标志被启用时,它会一直被调用,并且当日志记录也被启用时,我们可以观察它的行为,并发现它确实正在回收内存。但是,当压力测试标志关闭时,它永远不会运行。现在该决定收集器在正常程序执行期间何时被调用了。
据我所知,文献对这个问题的回答很差。当垃圾回收器刚被发明时,计算机只有很少的固定内存。许多早期的 GC 论文假设你预留了几千个字的内存—换句话说,大部分内存—并在内存不足时调用回收器。很简单。
现代机器拥有千兆字节的物理 RAM,隐藏在操作系统更大的虚拟内存抽象后面,该抽象与其他许多程序共享,这些程序都在争夺自己的内存块。操作系统将允许你的程序请求尽可能多的内存,然后在物理内存不足时从磁盘中分页进出。你永远不会真正“用完”内存,只是越来越慢。
26 . 6 . 1延迟和吞吐量
等待到“必须”时再运行 GC 已经没有意义了,因此我们需要更微妙的计时策略。为了更精确地分析这个问题,现在是时候介绍在衡量内存管理器性能时使用的两个基本数字:吞吐量和延迟。
与显式用户编写的释放相比,每种托管语言都付出了性能代价。实际释放内存所花费的时间是相同的,但 GC 会花费周期来确定要释放哪些内存。那是不用来运行用户代码和做有用工作的时间。在我们的实现中,那是标记阶段的全部内容。一个复杂的垃圾回收器的目标是最小化这种开销。
我们可以使用两个关键指标来更好地理解这种成本
-
吞吐量是运行用户代码所花费的总时间与进行垃圾回收工作所花费的总时间之比。假设你运行一个 clox 程序 10 秒,它在其中的 1 秒内花费在
collectGarbage()中。这意味着吞吐量为 90%—它 90% 的时间用于运行程序,10% 的时间用于 GC 开销。吞吐量是最基本的衡量标准,因为它跟踪收集开销的总成本。在其他条件相同的情况下,你希望最大化吞吐量。在本节之前,clox 根本没有 GC,因此吞吐量为 100%。这很难超越。当然,这会以用户程序运行足够长时间后可能会用完内存并崩溃为代价。你可以将 GC 的目标视为修复这个“故障”,同时尽可能少地牺牲吞吐量。
-
延迟是用户程序完全暂停以进行垃圾回收的最长连续时间段。它衡量回收器是多么“块状”。延迟是一个与吞吐量完全不同的指标。
考虑两次运行 clox 程序,两次都花费 10 秒。在第一次运行中,GC 介入一次,并在一次大规模收集中花费 1 秒钟在
collectGarbage()中。在第二次运行中,GC 被调用了五次,每次都是五分之一秒。花费在收集上的总时间仍然是 1 秒,因此两种情况下吞吐量都是 90%。但在第二次运行中,延迟只有五分之一秒,是第一次运行的五分之一。
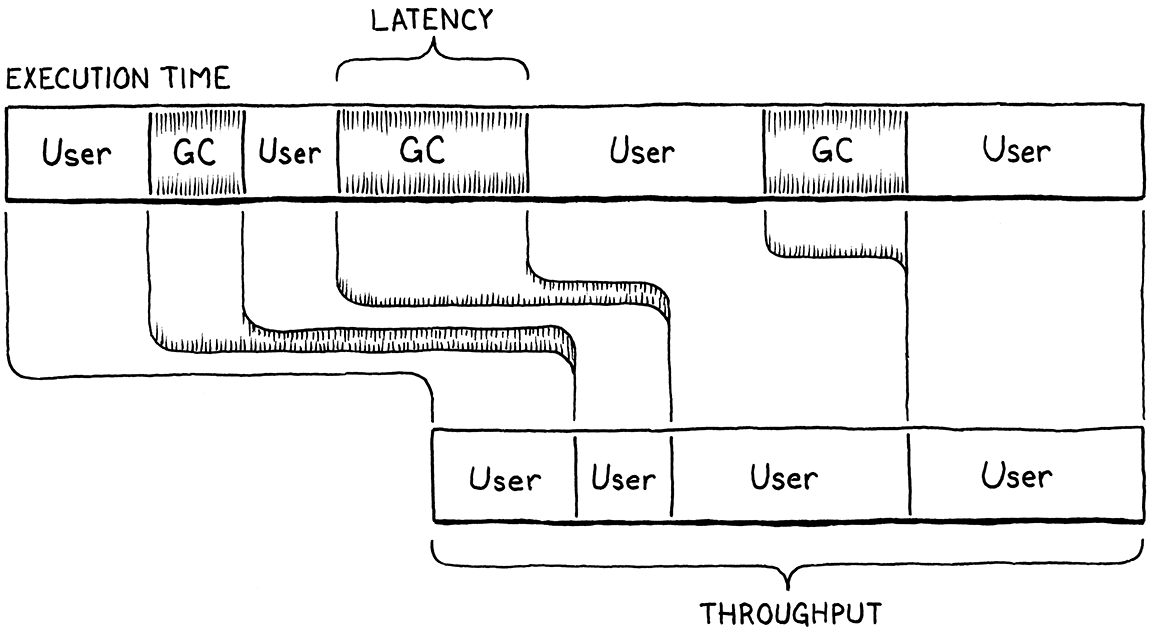
如果你喜欢类比,想象一下你的程序是一家出售新鲜烘焙面包的烘焙店。吞吐量是你一天能向顾客提供的热乎乎、脆皮的长棍面包的总数。延迟是不幸的顾客在被服务之前需要排队的最长时间。
运行垃圾回收器就像暂时关闭烘焙店,把所有的盘子都处理掉,把脏的和干净的分类,然后洗掉用过的盘子。在我们这个类比中,我们没有专门的洗碗工,所以当这种情况发生时,就没有面包在烤。面包师在洗碗。
每天卖出更少的面包是不好的,让任何特定客户坐在那里等你洗完所有盘子也是不好的。目标是最大化吞吐量和最小化延迟,但即使在面包店里,也没有免费的午餐。垃圾回收器在牺牲多少吞吐量和容忍多少延迟之间做出了不同的权衡。
能够进行这些权衡是有用的,因为不同的用户程序有不同的需求。一个从一个太字节的数据中生成报告的隔夜批处理作业只需要尽可能快地完成工作。吞吐量是王道。同时,在用户智能手机上运行的应用程序需要始终立即响应用户输入,以便拖动屏幕的感觉 非常顺畅。应用程序不能在 GC 在堆中乱搞时冻结几秒钟。
作为垃圾回收器作者,你可以通过选择收集算法来控制吞吐量和延迟之间的权衡。但即使在同一个算法中,我们也可以对回收器运行的频率进行很多控制。
我们的回收器是一个 停止世界 GC,这意味着用户程序会暂停,直到整个垃圾回收过程完成。如果我们在运行回收器之前等待很长时间,那么大量的死亡对象就会累积起来。这会导致回收器运行时出现很长的暂停,从而导致高延迟。因此,很明显,我们希望经常运行回收器。
但每次回收器运行时,它都会花费一些时间访问活动对象。这实际上并没有做任何有用的事情(除了确保它们不会被错误地删除)。访问活动对象的时间不是用来释放内存的时间,也不是用来运行用户代码的时间。如果你非常频繁地运行 GC,那么用户程序就没有足够的时间来生成 VM 要收集的新垃圾。VM 会花费所有时间来一遍又一遍地执着地重新访问同一组活动对象,吞吐量会下降。因此,很明显,我们希望不太频繁地运行回收器。
事实上,我们想要的是介于两者之间的东西,回收器运行的频率是我们调整延迟和吞吐量之间权衡的主要旋钮之一。
26 . 6 . 2自调整堆
我们希望我们的 GC 运行得足够频繁以最小化延迟,但运行得足够不频繁以保持良好的吞吐量。但是,当我们不知道用户程序需要多少内存以及它分配内存的频率时,我们如何找到这两者之间的平衡?我们可以将问题推给用户,并通过公开 GC 调整参数来强迫他们选择。许多 VM 都这样做。但如果我们这些 GC 作者都不知道如何很好地调整它,那么很有可能大多数用户也不知道。他们应该得到合理的默认行为。
说实话,这不是我的专业领域。我和很多专业的 GC 黑客谈过—你可以以此为生—并阅读了很多文献,我得到的答案都是 . . . 含糊不清。我最终选择的策略很常见,很简单,而且(我希望!)足够满足大多数用途。
想法是回收器频率会根据堆的活动大小自动调整。我们跟踪 VM 已分配的托管内存的总字节数。当它超过某个阈值时,我们就会触发 GC。之后,我们记录了剩余的字节数—有多少字节没有被释放。然后我们将阈值调整到比该值更大的某个值。
结果是,随着活动内存量的增加,我们收集的频率更低,以避免通过重新遍历越来越多的活动对象集合来牺牲吞吐量。随着活动内存量的减少,我们收集的频率更高,这样我们就不会因为等待太长时间而损失太多延迟。
实现需要在 VM 中添加两个新的簿记字段。
ObjUpvalue* openUpvalues;
在 struct VM 中
size_t bytesAllocated; size_t nextGC;
Obj* objects;
第一个是 VM 已分配的托管内存的字节数的运行总计。第二个是触发下次收集的阈值。我们在 VM 启动时初始化它们。
vm.objects = NULL;
在 initVM() 中
vm.bytesAllocated = 0; vm.nextGC = 1024 * 1024;
vm.grayCount = 0;
这里的起始阈值是任意的。它类似于我们为各种动态数组选择的初始容量。目标是不要太快地触发前几次 GC,但也不要等太久。如果我们有一些真实的 Lox 程序,我们可以分析这些程序来调整它。但由于我们只有玩具程序,所以我只是选择了一个数字。
每次我们分配或释放一些内存时,我们都会根据该增量调整计数器。
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
在 reallocate() 中
vm.bytesAllocated += newSize - oldSize;
if (newSize > oldSize) {
当总计超过限制时,我们就会运行回收器。
collectGarbage(); #endif
在 reallocate() 中
if (vm.bytesAllocated > vm.nextGC) {
collectGarbage();
}
}
现在,最后,我们的垃圾回收器在用户运行没有启用隐藏诊断标志的程序时实际上会执行一些操作。清除阶段通过调用 reallocate() 来释放对象,这会降低 bytesAllocated 的值,因此在收集完成后,我们知道有多少活动字节剩余。我们根据该值调整下次 GC 的阈值。
sweep();
在 collectGarbage() 中
vm.nextGC = vm.bytesAllocated * GC_HEAP_GROW_FACTOR;
#ifdef DEBUG_LOG_GC
阈值是堆大小的倍数。这样,随着程序使用的内存量增加,阈值会向外移动,以限制重新遍历更大的活动集所花费的总时间。与本章中的其他数字一样,缩放因子基本上是任意的。
#endif
#define GC_HEAP_GROW_FACTOR 2
void* reallocate(void* pointer, size_t oldSize, size_t newSize) {
在你有一些真实程序可以用来对其进行基准测试后,你将需要在你的实现中调整它。现在,我们至少可以记录一些我们拥有的统计数据。我们在收集之前捕获堆大小。
printf("-- gc begin\n");
在 collectGarbage() 中
size_t before = vm.bytesAllocated;
#endif
然后在最后打印结果。
printf("-- gc end\n");
在 collectGarbage() 中
printf(" collected %zu bytes (from %zu to %zu) next at %zu\n", before - vm.bytesAllocated, before, vm.bytesAllocated, vm.nextGC);
#endif
这样我们就可以看到垃圾回收器运行时完成了多少工作。
26 . 7垃圾回收错误
理论上,我们现在已经完成了。我们有一个 GC。它会定期启动,收集它能收集的东西,然后留下剩下的东西。如果这是一本典型的教科书,我们会掸掉手上的灰尘,沉浸在我们创造的完美大理石建筑的柔和光芒中。
但我旨在教会你不仅仅是编程语言的理论,还有有时令人痛苦的现实。我要翻过一块腐烂的木头,向你展示生活在它下面的讨厌的虫子,而垃圾回收错误确实是那里最恶心的无脊椎动物。
回收器的任务是释放死亡对象并保留活动对象。在这两个方向上都容易犯错误。如果 VM 无法释放不需要的对象,它会慢慢地泄漏内存。如果它释放了正在使用的对象,用户程序可能会访问无效的内存。这些故障通常不会立即导致崩溃,这使得我们难以回溯时间来查找错误。
由于我们不知道收集器何时运行,这变得更加困难。任何最终分配一些内存的调用都是 VM 中可能发生收集的地方。这就像音乐椅游戏。GC 随时可能停止音乐。我们想要保留的每个堆分配对象都需要快速找到椅子——被标记为根或存储在其他对象的引用中——在清除阶段将它踢出游戏之前。
VM 如何才能在 GC 本身没有看到的情况下使用对象——一个对象?VM 如何找到它?最常见的答案是通过存储在 C 栈上的一些局部变量中的指针。GC 遍历*VM* 的值栈和调用帧栈,但 C 栈对它来说是隐藏的。
在前面的章节中,我们编写了看似无用的代码,将对象推送到 VM 的值栈上,做一些工作,然后将其弹出。大多数情况下,我说这是为了 GC 的利益。现在你明白为什么了。推送和弹出之间的代码可能会分配内存,从而触发 GC。我们必须确保对象在值栈上,以便收集器的标记阶段能够找到它并使其保持活动状态。
我在将 clox 拆分成章节并编写文字之前就写好了整个实现,所以我有足够的时间找到所有这些角落并消除大多数这些错误。我们在本章开头添加的压力测试代码和一个相当不错的测试套件非常有用。
但我只修复了大多数错误。我留下了一些,因为我想让你了解在实际中遇到这些错误是什么感觉。如果你启用压力测试标志并运行一些 Lox 玩具程序,你可能会偶然发现一些错误。试一试,看看你是否可以自己修复任何错误。
26 . 7 . 1添加到常量表
你很有可能遇到第一个错误。每个块拥有的常量表是一个动态数组。当编译器将一个新的常量添加到当前函数的表中时,该数组可能需要增长。常量本身也可能是某些堆分配对象,比如字符串或嵌套函数。
添加到常量表的新对象被传递给 addConstant()。此时,该对象只能在 C 栈上该函数的参数中找到。该函数将该对象追加到常量表。如果表没有足够的容量并且需要增长,它会调用 reallocate()。这反过来会触发 GC,GC 无法标记新的常量对象,因此在我们有机会将其添加到表之前就将其清除。崩溃。
正如你在其他地方看到的,修复方法是将常量临时推送到栈上。
int addConstant(Chunk* chunk, Value value) {
在 addConstant() 中
push(value);
writeValueArray(&chunk->constants, value);
一旦常量表包含该对象,我们就将其从栈上弹出。
writeValueArray(&chunk->constants, value);
在 addConstant() 中
pop();
return chunk->constants.count - 1;
当 GC 标记根时,它会遍历编译器的链并标记每个函数,因此新的常量现在是可访问的。我们需要一个包含文件,以便从“chunk”模块调用 VM。
#include "memory.h"
#include "vm.h"
void initChunk(Chunk* chunk) {
26 . 7 . 2字符串驻留
这是另一个类似的错误。clox 中所有的字符串都驻留,因此每当我们创建一个新字符串时,我们也会将其添加到驻留表中。你可能已经猜到了。由于该字符串是全新的,它在任何地方都无法访问。而调整字符串池的大小可能会触发收集。同样,我们先将字符串存储到栈上。
string->chars = chars; string->hash = hash;
在 allocateString() 中
push(OBJ_VAL(string));
tableSet(&vm.strings, string, NIL_VAL);
然后在字符串安全地嵌套在表中后将其弹出。
tableSet(&vm.strings, string, NIL_VAL);
在 allocateString() 中
pop();
return string; }
这确保了在调整表大小期间字符串是安全的。一旦它熬过了这一步,allocateString() 会将其返回给某个调用者,然后调用者可以负责确保在下次堆分配发生之前字符串仍然是可访问的。
26 . 7 . 3字符串连接
最后一个例子:在解释器中,OP_ADD 指令可以用来连接两个字符串。与数字一样,它从栈中弹出两个操作数,计算结果,并将该新值推回到栈上。对于数字来说,这是完全安全的。
但连接两个字符串需要在堆上分配一个新的字符数组,这反过来会导致 GC。由于此时我们已经弹出了操作数字符串,因此它们可能会被标记阶段忽略并被清除。我们不是急切地将它们从栈上弹出,而是窥视它们。
static void concatenate() {
在 concatenate() 中
替换 2 行
ObjString* b = AS_STRING(peek(0)); ObjString* a = AS_STRING(peek(1));
int length = a->length + b->length;
这样,在创建结果字符串时,它们仍然挂在栈上。一旦完成,我们可以安全地将它们弹出,并将它们替换为结果。
ObjString* result = takeString(chars, length);
在 concatenate() 中
pop(); pop();
push(OBJ_VAL(result));
这些都很容易,尤其是我已经展示了修复方法。在实践中,找到它们才是最难的部分。你只看到一个应该存在但不存在的对象。这不像其他错误,你是在寻找导致问题的代码。你是在寻找没有阻止问题的代码,而这是一个更难的搜索。
但至少现在,你可以安心。据我所知,我们已经找到了 clox 中的所有收集错误,现在我们有一个工作正常、健壮、自调整的标记-清除垃圾收集器。
挑战
-
现在,每个对象顶部的 Obj 头部结构有三个字段:
type、isMarked和next。它们占用多少内存(在你的机器上)?你能想出更紧凑的方法吗?这样做有没有运行时成本? -
当清除阶段遍历一个活动对象时,它会清除
isMarked字段,为下一个收集周期做好准备。你能想出更有效的方法吗? -
标记-清除只是各种垃圾收集算法中的一种。通过用其他算法替换或增强当前收集器来探索这些算法。可以考虑的候选算法有引用计数、Cheney 算法或 Lisp 2 标记-压缩算法。
设计说明:分代收集器
如果收集器花费很长时间重新访问仍然活跃的对象,那么它的吞吐量就会下降。但如果它避免收集并积累大量垃圾来处理,它会增加延迟。如果有一种方法可以判断哪些对象可能长寿,哪些对象不是。那么 GC 可以更少地重新访问长寿对象,更频繁地清理短命对象。
事实证明,这种方法确实存在。很多年前,GC 研究人员收集了现实世界运行程序中对象生命周期的指标。他们跟踪每个对象的分配时间,以及它最终不再需要的时间,然后绘制出对象的生命周期趋势图。
他们发现了一些东西,他们称之为分代假设,或者更不委婉的术语婴儿死亡率。他们的观察结果是,大多数对象的生命周期很短,但一旦它们存活到一定年龄,它们往往会持续很长时间。一个对象存活的时间越长,它可能继续存活的时间就越长。这个观察结果很有力,因为它为他们提供了一种方法,将对象划分为受益于频繁收集和不受益于频繁收集的组。
他们设计了一种叫做分代垃圾收集的技术。它的工作原理是这样的:每次分配一个新对象时,它都会进入一个称为“苗圃”的特殊、相对较小的堆区域。由于对象往往很短命,因此垃圾收集器会频繁地调用该区域中的对象。
每次 GC 运行苗圃都称为“代”。任何不再需要的对象都会被释放。那些存活下来的对象现在被认为比以前大一岁,GC 会跟踪每个对象的年龄。如果一个对象存活了若干代——通常只是一次收集——它就会被“晋升”。此时,它将从苗圃复制到一个更大的堆区域,用于存放长寿对象。GC 也会在该区域运行,但频率要低得多,因为大多数这些对象很可能仍然活着。
分代收集器是经验数据——对象生命周期不均匀分布——和巧妙算法设计的完美结合,利用了这个事实。它们在概念上也很简单。你可以将它看作是两个独立调整的 GC 和一个将对象从一个 GC 移动到另一个 GC 的非常简单的策略。