控制流
逻辑,就像威士忌,一旦过多,其益处就会消失。
爱德华·约翰·莫顿·德拉克斯·普朗克特,邓萨尼勋爵
与 上一章 中的艰苦马拉松相比,今天就像在雏菊草地上轻松嬉戏。虽然工作轻松,但回报却出乎意料地巨大。
现在,我们的解释器只是一个计算器。Lox 程序只能在完成之前执行固定数量的工作。要让它运行两倍的时间,你必须让源代码长度增加两倍。我们即将解决这个问题。在本章中,我们的解释器朝着编程语言的顶级联赛迈出了重要一步:图灵完备。
9 . 1图灵机(简述)
在上个世纪初,数学家们偶然发现了一系列令人困惑的 悖论,这使得他们开始怀疑他们所构建的理论基础的稳定性。为了解决这场 危机,他们回到了原点。从一小部分公理、逻辑和集合论开始,他们希望在坚不可摧的基础上重建数学。
他们希望严格地回答诸如“所有真命题都能证明吗?”、“我们能 计算 所有我们能定义的函数吗?”,或者更普遍的问题,“当我们声称一个函数是‘可计算的’时,我们的意思是?”
他们假设对前两个问题的答案是“是”。剩下的只是证明它。事实证明,两个问题的答案都是“否”,令人惊讶的是,这两个问题有着深刻的联系。这是一个迷人的数学角落,涉及有关大脑能做什么以及宇宙如何运作的基本问题。我在这里无法做到公正的描述。
我想指出的是,在证明前两个问题的答案是“否”的过程中,艾伦·图灵和阿隆佐·丘奇对最后一个问题给出了一个精确的答案——一个关于哪些函数是 可计算 的定义。他们分别设计了一个微小的系统,具有最少的机械装置,但仍然足够强大,可以计算一大类(非常大)函数。
这些现在被认为是“可计算函数”。图灵的系统被称为 图灵机。丘奇的是lambda 演算。两者仍然被广泛用作计算模型的基础,事实上,许多现代函数式编程语言在核心使用 lambda 演算。
图灵机拥有更高的知名度——还没有关于阿隆佐·丘奇的电影——但这两种形式主义在 能力上是等效的。事实上,任何具有最小表达能力的编程语言都足够强大,可以计算任何可计算函数。
你可以通过在你的语言中编写图灵机的模拟器来证明这一点。由于图灵证明了他的机器可以计算任何可计算函数,因此从扩展意义上讲,这意味着你的语言也可以。你所需要做的就是将函数转换为图灵机,然后在你的模拟器上运行它。
如果你的语言足够表达以做到这一点,它就被认为是图灵完备的。图灵机非常简单,所以要做到这一点并不需要太多能力。你基本上需要算术、一些控制流,以及分配和使用(理论上)任意数量的内存的能力。我们已经有了第一个。在本章结束时,我们将拥有 第二个。
9 . 2条件执行
够了历史,让我们让我们的语言更精彩。我们可以粗略地将控制流分为两种
-
条件或分支控制流用于不执行某段代码。在命令式编程中,你可以将其视为跳过一段代码。
-
循环控制流多次执行一段代码。它回跳,这样你就可以再次执行某些操作。由于你通常不想要无限循环,因此它通常有一些条件逻辑,用于判断何时停止循环。
分支更简单,所以我们将从那里开始。C 派生的语言有两个主要的条件执行功能,if 语句和令人明智地命名为“条件”的 运算符 (?:)。if 语句允许你条件执行语句,而条件运算符允许你条件执行表达式。
为了简单起见,Lox 没有条件运算符,所以让我们开始使用 if 语句。我们的语句语法将得到一个新的产生式。
statement → exprStmt | ifStmt | printStmt | block ; ifStmt → "if" "(" expression ")" statement ( "else" statement )? ;
if 语句有一个用于条件的表达式,然后是一个在条件为真时执行的语句。可选地,它还可能有一个 else 关键字和一个在条件为假时执行的语句。 语法树节点 为这三个部分中的每一个都包含字段。
"Expression : Expr expression",
在 main() 中
"If : Expr condition, Stmt thenBranch," + " Stmt elseBranch",
"Print : Expr expression",
与其他语句一样,解析器通过领先的 if 关键字来识别 if 语句。
private Stmt statement() {
在 statement() 中
if (match(IF)) return ifStatement();
if (match(PRINT)) return printStatement();
当它找到一个时,它会调用这个新方法来解析剩余部分
在 statement() 后添加
private Stmt ifStatement() { consume(LEFT_PAREN, "Expect '(' after 'if'."); Expr condition = expression(); consume(RIGHT_PAREN, "Expect ')' after if condition."); Stmt thenBranch = statement(); Stmt elseBranch = null; if (match(ELSE)) { elseBranch = statement(); } return new Stmt.If(condition, thenBranch, elseBranch); }
与往常一样,解析代码严格遵循语法。它通过查找前面的 else 关键字来检测 else 子句。如果没有,则语法树中的 elseBranch 字段为 null。
这个看似不起眼的可选 else 子句实际上在我们语法中引入了一个歧义。考虑
if (first) if (second) whenTrue(); else whenFalse();
谜题是:哪个 if 语句对应这个 else 子句?这不仅仅是关于我们如何表示语法的理论问题。它实际上影响了代码的执行方式
-
如果我们将 else 连接到第一个
if语句,那么如果first为假,则调用whenFalse(),无论second的值是什么。 -
如果我们将它连接到第二个
if语句,那么只有当first为真且second为假时才会调用whenFalse()。
由于 else 子句是可选的,并且没有明确的分隔符标记 if 语句的结尾,因此当你以这种方式嵌套 if 时,语法是模棱两可的。这种经典的语法陷阱称为悬空 else 问题。
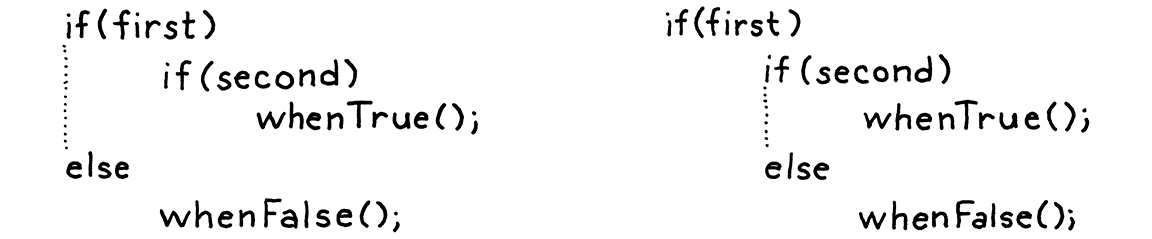
确实可以定义一个避免歧义的上下文无关文法,但它需要将大多数语句规则分成两部分,一部分允许带 else 的 if,另一部分则不允许。这很烦人。
相反,大多数语言和解析器以一种特定于实现的方式来避免这个问题。无论他们使用什么技巧来解决这个问题,他们总是选择相同的解释——else 绑定到它前面最近的 if。
我们的解析器已经方便地做到了这一点。由于 ifStatement() 在返回之前会急切地查找 else,因此嵌套系列中内层对 ifStatement() 的调用会在返回到外层 if 语句之前为自己声明 else 子句。
语法在手,我们准备好解释了。
在 visitExpressionStmt() 后添加
@Override public Void visitIfStmt(Stmt.If stmt) { if (isTruthy(evaluate(stmt.condition))) { execute(stmt.thenBranch); } else if (stmt.elseBranch != null) { execute(stmt.elseBranch); } return null; }
解释器实现是 Java 代码本身的薄包装器。它计算条件。如果为真,则执行 then 分支。否则,如果存在 else 分支,则执行它。
如果你将这段代码与解释器处理我们已实现的其他语法的代码进行比较,使控制流变得特殊的部分是 Java 的 if 语句。大多数其他语法树总是计算它们的子树。在这里,我们可能不会计算 then 或 else 语句。如果这两者中的任何一个有副作用,那么不计算它的选择就会对用户可见。
9 . 3逻辑运算符
由于我们没有条件运算符,你可能认为我们已经完成了分支,但事实并非如此。即使没有三元运算符,也有另外两个运算符在技术上是控制流结构—逻辑运算符and 和or。
它们与其他二元运算符不同,因为它们会短路。如果在评估完左操作数后,我们知道了逻辑表达式结果必须是什么,我们不会评估右操作数。例如
false and sideEffect();
为了使and 表达式评估为真值,两个操作数都必须为真值。我们可以看到,一旦我们评估了左边的false 操作数,就知道结果不会是真值,因此无需评估sideEffect(),它会被跳过。
这就是为什么我们没有将逻辑运算符与其他二元运算符一起实现的原因。现在我们准备好了。这两个新运算符在优先级表中处于较低的位置。与 C 中的|| 和&& 类似,它们各自拥有自己的优先级,其中or 比and 的优先级低。我们将它们放在assignment 和equality 之间。
expression → assignment ; assignment → IDENTIFIER "=" assignment | logic_or ; logic_or → logic_and ( "or" logic_and )* ; logic_and → equality ( "and" equality )* ;
现在,assignment 不再回退到equality,而是级联到logic_or。这两个新规则logic_or 和logic_and 与其他二元运算符类似。然后,logic_and 调用equality 来处理其操作数,我们再回溯到表达式规则的剩余部分。
我们可以重用现有的Expr.Binary 类来表示这两个新表达式,因为它们具有相同的字段。但是,visitBinaryExpr() 必须检查运算符是否为逻辑运算符之一,并使用不同的代码路径来处理短路。我认为为这些运算符定义一个新类会更清晰,这样它们就可以拥有自己的访问方法。
"Literal : Object value",
在 main() 中
"Logical : Expr left, Token operator, Expr right",
"Unary : Token operator, Expr right",
为了将新表达式编入解析器,我们首先更改分配的解析代码以调用or()。
private Expr assignment() {
在assignment() 中
替换 1 行
Expr expr = or();
if (match(EQUAL)) {
解析一系列or 表达式的代码与其他二元运算符类似。
在assignment() 后添加
private Expr or() { Expr expr = and(); while (match(OR)) { Token operator = previous(); Expr right = and(); expr = new Expr.Logical(expr, operator, right); } return expr; }
它的操作数是下一个更高的优先级,新的and 表达式。
在or() 后添加
private Expr and() { Expr expr = equality(); while (match(AND)) { Token operator = previous(); Expr right = equality(); expr = new Expr.Logical(expr, operator, right); } return expr; }
该方法调用equality() 来处理其操作数,至此,表达式解析器又重新连接到了一起。我们准备开始解释了。
在visitLiteralExpr() 后添加
@Override public Object visitLogicalExpr(Expr.Logical expr) { Object left = evaluate(expr.left); if (expr.operator.type == TokenType.OR) { if (isTruthy(left)) return left; } else { if (!isTruthy(left)) return left; } return evaluate(expr.right); }
如果你将此代码与上一章 的visitBinaryExpr() 方法进行比较,你就会发现它们之间的区别。在这里,我们首先评估左操作数。我们查看它的值以确定是否可以短路。如果不是,只有在这种情况下,我们才会评估右操作数。
这里另一个有趣的点是决定要返回的实际值。由于 Lox 是动态类型的,我们允许任何类型的操作数,并使用真值来确定每个操作数代表什么。我们对结果也应用类似的推理。逻辑运算符不会保证它会返回true 或false,而是保证它会返回一个具有适当真值的 value。
幸运的是,我们手边就有具有适当真值的 value—操作数本身的结果。因此,我们使用它们。例如
print "hi" or 2; // "hi". print nil or "yes"; // "yes".
在第一行中,"hi" 是真值,因此or 会短路并返回该值。在第二行中,nil 是假值,因此它会评估并返回第二个操作数"yes"。
这涵盖了 Lox 中的所有分支基本元素。我们准备好跳到循环了。你有没有注意到我说的话?跳。过去。明白了吗?你看,这就像是对 . . . 哦,算了。
9 . 4 While 循环
Lox 包含两个循环控制流语句,while 和for。while 循环比较简单,所以我们先从它开始。它的语法与 C 中相同。
statement → exprStmt | ifStmt | printStmt | whileStmt | block ; whileStmt → "while" "(" expression ")" statement ;
我们向语句规则添加另一个子句,指向 while 的新规则。它包含一个while 关键字,后面跟着一个带括号的条件表达式,然后是一个作为循环体的语句。该新的语法规则得到一个语法树节点。
"Print : Expr expression",
"Var : Token name, Expr initializer",
在 main() 中
在上一行添加“,”
"While : Expr condition, Stmt body"
));
该节点存储条件和循环体。在这里你可以看到将表达式和语句的语法树分开成两个不同的基类的好处。字段声明清楚地表明,条件是一个表达式,而循环体是一个语句。
在解析器中,我们遵循与if 语句相同的过程。首先,我们在statement() 中添加另一个 case 以检测和匹配引导关键字。
if (match(PRINT)) return printStatement();
在 statement() 中
if (match(WHILE)) return whileStatement();
if (match(LEFT_BRACE)) return new Stmt.Block(block());
该方法委托给此方法来完成实际工作
在varDeclaration() 后添加
private Stmt whileStatement() { consume(LEFT_PAREN, "Expect '(' after 'while'."); Expr condition = expression(); consume(RIGHT_PAREN, "Expect ')' after condition."); Stmt body = statement(); return new Stmt.While(condition, body); }
语法非常简单,这是一对一的 Java 代码转换。说到直接转换成 Java 代码,以下是我们执行新语法的代码
在visitVarStmt() 后添加
@Override public Void visitWhileStmt(Stmt.While stmt) { while (isTruthy(evaluate(stmt.condition))) { execute(stmt.body); } return null; }
与if 的访问方法类似,此访问者使用相应的 Java 功能。此方法并不复杂,但它让 Lox 变得更加强大。我们终于可以编写一个运行时间不受源代码长度严格限制的程序了。
9 . 5 For 循环
我们只剩下了最后一个控制流结构,古老的 C 风格for 循环。我可能不需要提醒你,但它看起来像这样
for (var i = 0; i < 10; i = i + 1) print i;
用语法来说,就是
statement → exprStmt | forStmt | ifStmt | printStmt | whileStmt | block ; forStmt → "for" "(" ( varDecl | exprStmt | ";" ) expression? ";" expression? ")" statement ;
在括号内,你用分号分隔了三个子句
-
第一个子句是初始化器。它只执行一次,在其他任何操作之前。它通常是一个表达式,但为了方便起见,我们也允许使用变量声明。在这种情况下,变量的范围限定为
for循环的剩余部分—另外两个子句和循环体。 -
接下来是条件。与
while循环一样,此表达式控制何时退出循环。它在每次迭代的开头都会被评估一次,包括第一次。如果结果为真值,则会执行循环体。否则,它会退出循环。 -
最后一个子句是增量。它是一个任意表达式,在每次循环迭代结束时执行一些操作。表达式的结果会被丢弃,因此它必须具有副作用才能发挥作用。在实践中,它通常会递增一个变量。
这些子句中的任何一个都可以省略。在右括号后是一个作为循环体的语句,它通常是一个代码块。
9 . 5 . 1 语法糖脱糖
这些机制非常多,但请注意,它们并没有做任何你不能用我们已经拥有的语句来完成的事情。如果for 循环不支持初始化器子句,你只需在for 语句之前加上初始化器表达式。如果没有增量子句,你只需将增量表达式放到循环体的末尾即可。
换句话说,Lox 不需要for 循环,它们只是让一些常见的代码模式更容易编写。这些功能被称为语法糖。例如,前面的for 循环可以重写为如下形式
{
var i = 0;
while (i < 10) {
print i;
i = i + 1;
}
}
这段脚本具有与先前脚本完全相同的语义,尽管它不像以前那么容易理解。像 Lox 的for 循环这样的语法糖功能使语言更容易使用和更高效。但是,尤其是在复杂的语言实现中,每个需要后端支持和优化的语言功能都是昂贵的。
我们可以通过脱糖 来两全其美。这个有趣的说法描述了前端将使用语法糖的代码转换为后端已经知道如何执行的更基本形式的过程。
我们将把for 循环脱糖为解释器已经处理过的while 循环和其他语句。在我们的简单解释器中,脱糖实际上并没有为我们省去太多工作,但它确实给了我一个向你介绍这种技术的借口。因此,与之前的语句不同,我们不会添加新的语法树节点。相反,我们直接进行解析。首先,添加我们很快就会用到的导入。
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
与所有语句一样,我们通过匹配关键字来开始解析for 循环。
private Stmt statement() {
在 statement() 中
if (match(FOR)) return forStatement();
if (match(IF)) return ifStatement();
这里变得有趣了。脱糖将在这一步进行,因此我们将逐步构建此方法,从括号开始。
在 statement() 后添加
private Stmt forStatement() { consume(LEFT_PAREN, "Expect '(' after 'for'."); // More here... }
紧随其后的第一个子句是初始化器。
consume(LEFT_PAREN, "Expect '(' after 'for'.");
在forStatement() 中
替换 1 行
Stmt initializer; if (match(SEMICOLON)) { initializer = null; } else if (match(VAR)) { initializer = varDeclaration(); } else { initializer = expressionStatement(); }
}
如果紧随( 后的标记是分号,则表示初始化器已被省略。否则,我们将检查var 关键字,看看它是否是变量 声明。如果两者都不匹配,则它一定是表达式。我们将解析该表达式并将其包装在表达式语句中,这样初始化器始终为 Stmt 类型。
接下来是条件。
initializer = expressionStatement();
}
在forStatement() 中
Expr condition = null;
if (!check(SEMICOLON)) {
condition = expression();
}
consume(SEMICOLON, "Expect ';' after loop condition.");
}
同样,我们查找分号以查看子句是否已被省略。最后一个子句是增量。
consume(SEMICOLON, "Expect ';' after loop condition.");
在forStatement() 中
Expr increment = null;
if (!check(RIGHT_PAREN)) {
increment = expression();
}
consume(RIGHT_PAREN, "Expect ')' after for clauses.");
}
它与条件子句类似,只是这个子句以右括号结束。剩下的就是循环体。
consume(RIGHT_PAREN, "Expect ')' after for clauses.");
在forStatement() 中
Stmt body = statement(); return body;
}
我们已经解析了for循环的各个部分,生成的AST节点都放在了一些Java局部变量中。这就是去糖化发挥作用的地方。我们利用它们来合成语法树节点,表达for循环的语义,就像我之前展示给你的手动去糖化示例一样。
如果我们反向操作,代码会更简单一些,所以我们从增量语句开始。
Stmt body = statement();
在forStatement() 中
if (increment != null) { body = new Stmt.Block( Arrays.asList( body, new Stmt.Expression(increment))); }
return body;
如果存在增量语句,它会在每次循环迭代后执行。我们通过用一个包含原始主体和评估增量语句的表达式语句的小块替换主体来实现这一点。
}
在forStatement() 中
if (condition == null) condition = new Expr.Literal(true); body = new Stmt.While(condition, body);
return body;
接下来,我们获取条件和主体,并使用原始的while循环构建循环。如果条件被省略,我们会插入true来创建一个无限循环。
body = new Stmt.While(condition, body);
在forStatement() 中
if (initializer != null) { body = new Stmt.Block(Arrays.asList(initializer, body)); }
return body;
最后,如果存在初始化器,它会在整个循环之前执行一次。我们同样通过用一个执行初始化器并执行循环的块替换整个语句来实现这一点。
就是这样。我们的解释器现在支持C风格的for循环,我们根本没有碰过Interpreter类。由于我们已经去糖化成解释器已经知道的节点,所以没有更多工作需要做。
最后,Lox的功能强大到足以让我们享受几分钟的乐趣。这里有一个小程序,用于打印斐波那契数列的前21个元素
var a = 0; var temp; for (var b = 1; a < 10000; b = temp + b) { print a; temp = a; a = b; }
挑战
-
在几章之后,当Lox支持一等函数和动态分派时,从技术上讲,我们不需要在语言中内置分支语句。展示如何使用这些语句来实现条件执行。命名一种使用此技术进行控制流的语言。
-
同样,只要我们的解释器支持一项重要的优化,就可以使用相同的工具来实现循环。它是什么,为什么是必要的?命名一种使用此技术进行迭代的语言。
-
与Lox不同,大多数其他C风格的语言也支持循环中的
break和continue语句。添加对break语句的支持。语法是
break关键字后跟一个分号。在任何封闭循环之外出现break语句都是语法错误。在运行时,break语句会使执行跳转到最近的封闭循环的末尾,并从那里继续执行。请注意,break可能嵌套在也需要退出的其他块和if语句中。
设计说明:语法糖的勺子
当你设计自己的语言时,你需要选择在语法中注入多少语法糖。你是要制作一个不含糖分的健康食品,每个语义操作都映射到一个语法单元,还是制作一些精致的甜点,每种行为都可以用十种不同的方式表达?成功的语言在这条连续统一体上占据着所有位置。
在极端的酸味方面,是那些语法非常简洁的语言,比如Lisp、Forth和Smalltalk。Lisper们声称他们的语言“没有语法”,而Smalltalker们则自豪地展示,你可以把整个语法放到一张索引卡上。这个群体秉持的理念是,语言不需要语法糖。相反,它提供的最少的语法和语义足以让库代码像语言本身一样具有表现力。
接近这些语言的是C、Lua和Go。它们的目标是简洁明了,而不是极简主义。有些,比如Go,故意避开语法糖和上一类语言的语法可扩展性。它们希望语法不要妨碍语义,因此它们专注于保持语法和库的简单性。代码应该清晰明了,而不是美丽。
在中间位置,你有像Java、C#和Python这样的语言。最终,你将接触到Ruby、C++、Perl和D—这些语言在语法中塞满了太多语法糖,以至于键盘上的标点符号都不够用了。
在某种程度上,位置在频谱上的位置与年龄相关。在之后的版本中添加语法糖相对容易。新的语法受到大众欢迎,而且与修改语义相比,它不太可能破坏现有的程序。一旦添加了,你就无法再将其删除,所以语言往往会随着时间的推移而变得更甜。从头开始创建一个新语言的主要好处之一是,它给你一个机会刮掉那些积累的糖霜层,重新开始。
语法糖在PL智库中声名狼藉。在那群人中,对极简主义有一种真正的迷恋。这有一定的道理。设计不当、不需要的语法会增加认知负担,而不会增加足够的表达能力来弥补其重量。由于总会有压力将新特性塞进语言中,因此需要自律和对简洁性的关注,才能避免臃肿。一旦添加了一些语法,你就只能使用它,所以最好谨慎使用。
同时,大多数成功的语言的语法都相当复杂,至少在它们被广泛使用之前是如此。程序员在他们选择的语言中花费大量时间,一些小的改进确实可以提高他们的工作舒适度和效率。
找到正确的平衡—为你的语言选择合适的甜度—取决于你自己的品味。