值类型
当你是个脑袋很小的熊,并且你在思考一些事情的时候,你偶尔会发现,在你脑海中看起来非常像“东西”的东西,一旦出现在外界,被其他人看见,就会变得完全不同。
A. A. Milne, 小熊维尼
前几章内容非常庞大,充满了复杂的技巧和大量的代码。而在这一章中,你只需要学习一个新概念,以及一些简单的代码。你应该可以喘口气了。
Lox 是一种动态类型语言。同一个变量可以在不同的时间点存储布尔值、数字或字符串。至少,这个想法是这样的。现在,在 clox 中,所有的值都是数字。到本章结束时,它将支持布尔值和 nil。虽然这些并不特别有趣,但它们迫使我们弄清楚值表示如何动态地处理不同的类型。
18 . 1标记联合
在 C 语言中工作的好处是,我们可以从原始位构建数据结构。不好的地方是,我们必须这样做。C 语言在编译时不会为你提供太多帮助,在运行时更是如此。就 C 语言而言,宇宙是一个没有差异化的字节数组。决定使用多少字节以及它们表示什么,完全取决于我们自己。
为了选择值表示,我们需要回答两个关键问题:
-
如何表示值的类型? 如果你试图,比如,将一个数字乘以
true,我们需要在运行时检测到这个错误并报告它。为了做到这一点,我们需要能够知道值的类型是什么。 -
如何存储值本身? 我们不仅需要能够知道 3 是一个数字,还需要知道它与数字 4 不同。我知道,这似乎很明显,对吧?但我们是在一个需要详细说明这些事情的层面上运作的。
既然我们不仅仅是在设计这种语言,而是要自己构建它,那么在回答这两个问题时,我们还必须牢记实现者永恒的追求:高效地完成它。
多年来,语言黑客们想出了各种巧妙的方法,将上述信息尽可能压缩到最少的比特数。现在,我们将从最简单、最经典的解决方案开始:标记联合。一个值包含两个部分:一个类型“标记”和一个用于实际值的有效载荷。为了存储值的类型,我们为 VM 支持的每种值类型定义一个枚举。
#include "common.h"
typedef enum { VAL_BOOL, VAL_NIL, VAL_NUMBER, } ValueType;
typedef double Value;
目前,我们只有几个案例,但随着我们将字符串、函数和类添加到 clox 中,这个枚举将会不断增长。除了类型之外,我们还需要存储值的 data—数字的 double、布尔值的 true 或 false。我们可以定义一个结构体,其中包含每个可能类型的字段。

但这是一种浪费内存。一个值不可能同时是数字和布尔值。因此,在任何时候,这些字段中只有一个会被使用。C 语言允许你通过定义一个联合来优化这一点。联合看起来像结构体,但它的所有字段在内存中都是重叠的。
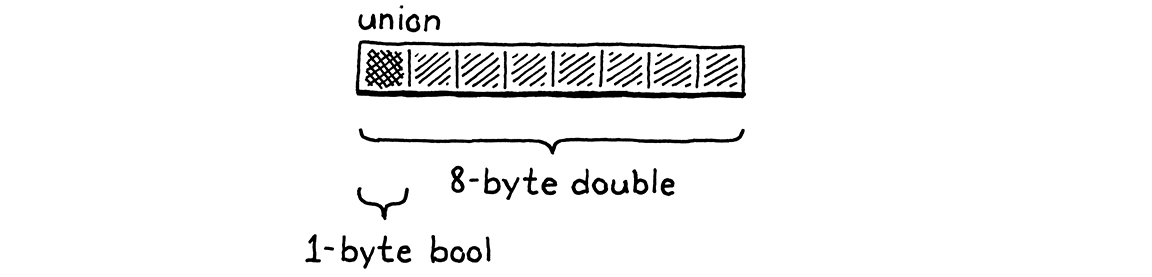
联合的大小是它最大字段的大小。由于所有字段都重用相同的位,因此在使用它们时必须非常小心。如果你使用一个字段存储数据,然后使用另一个字段访问数据,你将重新解释底层位的含义。
正如“标记联合”这个名字所暗示的,我们新的值表示将这两个部分组合成一个结构体。
} ValueType;
在枚举 ValueType 之后添加
替换 1 行
typedef struct { ValueType type; union { bool boolean; double number; } as; } Value;
typedef struct {
有一个字段用于类型标记,然后是一个包含所有底层值的联合的第二个字段。在 64 位机器上,使用典型的 C 编译器,布局看起来像这样:
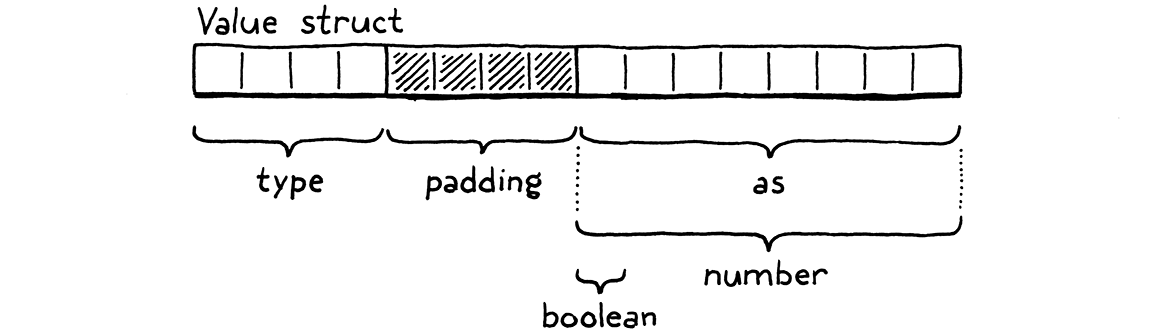
四字节类型标记首先出现,然后是联合。大多数架构都希望值与它们的大小对齐。由于联合字段包含一个八字节 double,因此编译器会在类型字段之后添加四字节的填充,以使该 double 位于最接近的八字节边界上。这意味着我们实际上在类型标记上花费了八字节,而它只需要表示 0 到 3 之间的数字。我们可以将枚举塞入更小的尺寸,但这只会增加填充。
因此,我们的 Values 是 16 字节,这似乎有点大。我们将在以后改进它。同时,它们仍然足够小,可以存储在 C 栈上并通过值传递。Lox 的语义允许这样做,因为我们目前支持的唯一类型是不可变的。如果我们将包含数字 3 的 Value 的副本传递给某个函数,我们不必担心调用者会看到对该值的修改。你不能“修改” 3。它永远是 3。
18 . 2Lox 值和 C 值
这就是我们新的值表示,但我们还没有完成。现在,clox 的其他部分假定 Value 是 double 的别名。我们有一些代码直接将一个类型强制转换为另一个类型。这些代码现在都坏了。太可惜了。
使用我们新的表示方法,Value 可以包含一个 double,但它并不等同于它。从一个类型转换为另一个类型,需要一个强制转换步骤。我们需要遍历代码,插入这些转换,使 clox 再次运行。
我们将这些转换实现为几个宏,每个类型和操作都有一个。首先,将原生 C 值提升为 clox Value:
} Value;
在结构体 Value 之后添加
#define BOOL_VAL(value) ((Value){VAL_BOOL, {.boolean = value}}) #define NIL_VAL ((Value){VAL_NIL, {.number = 0}}) #define NUMBER_VAL(value) ((Value){VAL_NUMBER, {.number = value}})
typedef struct {
这些宏中的每一个都接受适当类型的 C 值,并生成一个具有正确类型标记并包含底层值的 Value。这将静态类型的值提升到 clox 的动态类型宇宙中。然而,为了使用 Value,我们需要解包它,并获取 C 值。
} Value;
在结构体 Value 之后添加
#define AS_BOOL(value) ((value).as.boolean) #define AS_NUMBER(value) ((value).as.number)
#define BOOL_VAL(value) ((Value){VAL_BOOL, {.boolean = value}})
这些宏反向进行。给定一个类型正确的 Value,它们会将其解包并返回相应的原始 C 值。 “类型正确” 部分很重要!这些宏直接访问联合字段。如果我们做类似的事情
Value value = BOOL_VAL(true); double number = AS_NUMBER(value);
那么我们可能会打开通往阴影界的冒烟传送门。除非我们知道 Value 包含适当的类型,否则使用任何 AS_ 宏都不安全。为此,我们定义了最后几个宏来检查 Value 的类型。
} Value;
在结构体 Value 之后添加
#define IS_BOOL(value) ((value).type == VAL_BOOL) #define IS_NIL(value) ((value).type == VAL_NIL) #define IS_NUMBER(value) ((value).type == VAL_NUMBER)
#define AS_BOOL(value) ((value).as.boolean)
这些宏在 Value 具有该类型时返回 true。任何时候我们调用 AS_ 宏,我们都需要先在它前面调用一个这样的宏。有了这八个宏,我们现在可以安全地在 Lox 的动态世界和 C 的静态世界之间传送数据。
18 . 3动态类型数字
我们已经得到了值表示和转换到和从它转换的工具。剩下的就是遍历代码,修复每个数据跨越边界移动的地方。这是本书中那些不太令人兴奋的部分之一,但我承诺我会向你展示每一行代码,所以我们来做吧。
我们创建的第一个值是编译数字字面量时生成的常量。在将词素转换为 C double 之后,我们在将其存储到常量表之前,只需将其包装在 Value 中即可。
double value = strtod(parser.previous.start, NULL);
在 number() 中
替换 1 行
emitConstant(NUMBER_VAL(value));
}
在运行时,我们有一个用于打印值的函数。
void printValue(Value value) {
在 printValue() 中
替换 1 行
printf("%g", AS_NUMBER(value));
}
在我们向 printf() 发送 Value 之前,我们将其解包并提取 double 值。我们很快会重新讨论这个函数以添加其他类型,但我们先让现有代码运行起来。
18 . 3 . 1 一元否定和运行时错误
下一个最简单的操作是一元否定。它从栈中弹出值,否定它,然后将结果压入栈中。现在我们有了其他类型的值,我们不能再假设操作数是一个数字了。用户也可以这样做
print -false; // Uh...
我们需要优雅地处理这种情况,这意味着是时候使用运行时错误了。在执行需要特定类型的操作之前,我们需要确保 Value 的类型是该类型。
对于一元否定,检查如下所示:
case OP_DIVIDE: BINARY_OP(/); break;
在 run() 中
替换 1 行
case OP_NEGATE: if (!IS_NUMBER(peek(0))) { runtimeError("Operand must be a number."); return INTERPRET_RUNTIME_ERROR; } push(NUMBER_VAL(-AS_NUMBER(pop()))); break;
case OP_RETURN: {
首先,我们检查栈顶的 Value 是否是数字。如果不是,我们报告运行时错误并停止解释器。否则,我们将继续执行。只有在验证之后,我们才会解包操作数,否定它,包装结果并将其压入栈中。
为了访问 Value,我们使用一个新的函数。
在 pop() 之后添加
static Value peek(int distance) { return vm.stackTop[-1 - distance]; }
它从堆栈中返回一个值,但不会 弹出 它。distance 参数表示从堆栈顶部向下查看多少个位置:零表示顶部,一表示向下查看一个位置,以此类推。
我们使用一个新函数报告运行时错误,在本书的其余部分,我们将经常使用这个函数。
在 resetStack() 后添加
static void runtimeError(const char* format, ...) { va_list args; va_start(args, format); vfprintf(stderr, format, args); va_end(args); fputs("\n", stderr); size_t instruction = vm.ip - vm.chunk->code - 1; int line = vm.chunk->lines[instruction]; fprintf(stderr, "[line %d] in script\n", line); resetStack(); }
你肯定之前在 C 中调用过可变参数函数 — 接受可变数量参数的函数 —:printf() 就是其中之一。但你可能没有定义过自己的可变参数函数。本书不是 C 教程,因此我会简单介绍一下,但基本上,... 和 va_list 允许我们向 runtimeError() 传递任意数量的参数。它将这些参数转发给 vfprintf(),它是接受显式 va_list 的 printf() 的变体。
调用者可以向 runtimeError() 传递一个格式字符串,后面跟着若干个参数,就像直接调用 printf() 时一样。然后 runtimeError() 会格式化并打印这些参数。在本节中我们不会利用这一点,但在后面的章节中,我们将生成包含其他数据的格式化运行时错误消息。
显示了有帮助的错误消息后,我们会告诉用户在发生错误时正在执行代码的哪一行 代码。由于我们在编译器中留下了令牌,因此我们会在编译到代码块中的调试信息中查找该行。如果我们的编译器按预期工作,则对应于编译字节码的源代码行。
我们使用当前字节码指令索引减去一,查看代码块的调试行数组。这是因为解释器在执行每个指令之前会前进到下一个指令。因此,在调用 runtimeError() 时,失败的指令是前一个指令。
为了使用 va_list 和用于操作它的宏,我们需要引入一个标准头文件。
添加到文件顶部
#include <stdarg.h>
#include <stdio.h>
有了它,我们的虚拟机不仅可以在我们对数字进行取反时执行正确操作(就像我们在破坏它之前一样),而且还可以优雅地处理对其他类型的错误取反尝试(我们还没有这些类型,但仍然可以处理)。
18 . 3 . 2二元算术运算符
现在我们已经有了运行时错误机制,因此修复二元运算符更容易,即使它们更复杂。我们目前支持四个二元运算符:+、-、* 和 /。它们之间的唯一区别在于它们使用的底层 C 运算符。为了最大限度地减少四个运算符之间重复代码,我们将共性封装在一个大型预处理宏中,该宏将运算符令牌作为参数。
几章前,这个宏看起来像是在过度使用,但今天我们从中受益。它允许我们在一个地方添加必要的类型检查和转换。
#define READ_CONSTANT() (vm.chunk->constants.values[READ_BYTE()])
在 run() 中
替换 6 行
#define BINARY_OP(valueType, op) \ do { \ if (!IS_NUMBER(peek(0)) || !IS_NUMBER(peek(1))) { \ runtimeError("Operands must be numbers."); \ return INTERPRET_RUNTIME_ERROR; \ } \ double b = AS_NUMBER(pop()); \ double a = AS_NUMBER(pop()); \ push(valueType(a op b)); \ } while (false)
for (;;) {
是的,我意识到这是一个很大的宏。这并不是我通常认为的好的 C 编程实践,但让我们继续使用它。更改与我们对一元取反所做的更改类似。首先,我们检查两个操作数是否都是数字。如果其中任何一个不是数字,则报告运行时错误并拉动弹射座椅拉杆。
如果操作数没问题,我们弹出它们,然后展开它们。然后,我们应用给定的运算符,封装结果,并将其推回堆栈。注意,我们不是通过直接使用 NUMBER_VAL() 来封装结果的。相反,要使用的包装器作为宏 参数 传入。对于我们现有的算术运算符,结果是一个数字,因此我们将 NUMBER_VAL 宏传入。
}
在 run() 中
替换 4 行
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break; case OP_SUBTRACT: BINARY_OP(NUMBER_VAL, -); break; case OP_MULTIPLY: BINARY_OP(NUMBER_VAL, *); break; case OP_DIVIDE: BINARY_OP(NUMBER_VAL, /); break;
case OP_NEGATE:
很快,我将向你展示为什么我们将包装宏作为参数传递。
18 . 4两种新类型
我们现有的所有 clox 代码都恢复了工作状态。最后,是时候添加一些新类型了。我们已经有了运行的数字计算器,它现在执行了许多无用的、偏执的运行时类型检查。我们可以内部表示其他类型,但用户程序无法创建这些类型的值。
直到现在才有可能。我们将从添加对三种新字面量的编译器支持开始:true、false 和 nil。它们都很简单,所以我们将一次性完成这三种字面量。
对于数字字面量,我们必须处理存在数十亿个可能的数值这一事实。我们通过将字面量的值存储在代码块的常量表中,并发出一个字节码指令来加载该常量,从而解决了这个问题。我们可以对新类型执行相同的操作。我们可以将 true 存储在常量表中,并使用 OP_CONSTANT 来读取它。
但是,鉴于对于这些新类型,我们实际上只需要处理三个可能的值,因此将一个两字节指令和一个常量表条目浪费在它们身上是毫无意义的 — 而且很 慢! —。相反,我们将定义三个专门的指令,以将这些字面量中的每一个推送到堆栈上。
OP_CONSTANT,
在 enum OpCode 中
OP_NIL, OP_TRUE, OP_FALSE,
OP_ADD,
我们的扫描器已经将 true、false 和 nil 视为关键字,因此可以直接跳到解析器。使用基于表的 Pratt 解析器,我们只需要将解析器函数插入与这些关键字令牌类型关联的行中。我们将在所有三个插槽中使用相同的函数。这里
[TOKEN_ELSE] = {NULL, NULL, PREC_NONE},
替换 1 行
[TOKEN_FALSE] = {literal, NULL, PREC_NONE},
[TOKEN_FOR] = {NULL, NULL, PREC_NONE},
这里
[TOKEN_THIS] = {NULL, NULL, PREC_NONE},
替换 1 行
[TOKEN_TRUE] = {literal, NULL, PREC_NONE},
[TOKEN_VAR] = {NULL, NULL, PREC_NONE},
这里
[TOKEN_IF] = {NULL, NULL, PREC_NONE},
替换 1 行
[TOKEN_NIL] = {literal, NULL, PREC_NONE},
[TOKEN_OR] = {NULL, NULL, PREC_NONE},
当解析器在前缀位置遇到 false、nil 或 true 时,它会调用这个新的解析器函数
在 binary() 后添加
static void literal() { switch (parser.previous.type) { case TOKEN_FALSE: emitByte(OP_FALSE); break; case TOKEN_NIL: emitByte(OP_NIL); break; case TOKEN_TRUE: emitByte(OP_TRUE); break; default: return; // Unreachable. } }
由于 parsePrecedence() 已经消耗了关键字令牌,因此我们只需要输出正确的指令。我们根据解析的令牌类型来 确定 指令。我们的前端现在可以将布尔值和 nil 字面量编译为字节码。向下移动执行管道,我们到达解释器。
case OP_CONSTANT: {
Value constant = READ_CONSTANT();
push(constant);
break;
}
在 run() 中
case OP_NIL: push(NIL_VAL); break; case OP_TRUE: push(BOOL_VAL(true)); break; case OP_FALSE: push(BOOL_VAL(false)); break;
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
这很容易理解。每条指令都会调用适当的值,并将其推送到堆栈上。我们也不应该忘记我们的反汇编器。
case OP_CONSTANT:
return constantInstruction("OP_CONSTANT", chunk, offset);
在 disassembleInstruction() 中
case OP_NIL: return simpleInstruction("OP_NIL", offset); case OP_TRUE: return simpleInstruction("OP_TRUE", offset); case OP_FALSE: return simpleInstruction("OP_FALSE", offset);
case OP_ADD:
有了它,我们就可以运行这个惊天动地的程序
true
但是,当解释器尝试打印结果时,它崩溃了。我们需要扩展 printValue() 来处理新类型。
void printValue(Value value) {
在 printValue() 中
替换 1 行
switch (value.type) { case VAL_BOOL: printf(AS_BOOL(value) ? "true" : "false"); break; case VAL_NIL: printf("nil"); break; case VAL_NUMBER: printf("%g", AS_NUMBER(value)); break; }
}
好了!现在我们有了新的类型。只是它们目前不太有用。除了字面量之外,你无法真正使用它们。nil 要过一段时间才会派上用场,但我们可以开始在逻辑运算符中使用布尔值。
18 . 4 . 1逻辑非和假值
最简单的逻辑运算符是我们熟悉的感叹号朋友一元非。
print !true; // "false"
这个新的操作获得了新的指令。
OP_DIVIDE,
在 enum OpCode 中
OP_NOT,
OP_NEGATE,
我们可以重用为一元取反编写的一元 unary() 解析器函数,来编译非表达式。我们只需要将其插入解析表即可。
[TOKEN_STAR] = {NULL, binary, PREC_FACTOR},
替换 1 行
[TOKEN_BANG] = {unary, NULL, PREC_NONE},
[TOKEN_BANG_EQUAL] = {NULL, NULL, PREC_NONE},
因为我知道我们要这样做,所以 unary() 函数已经包含一个根据令牌类型来确定要输出哪个字节码指令的 switch。我们只需添加另一个 case 即可。
switch (operatorType) {
在 unary() 中
case TOKEN_BANG: emitByte(OP_NOT); break;
case TOKEN_MINUS: emitByte(OP_NEGATE); break;
default: return; // Unreachable.
}
前端部分就这些了。让我们转到虚拟机,并将这条指令变为现实。
case OP_DIVIDE: BINARY_OP(NUMBER_VAL, /); break;
在 run() 中
case OP_NOT: push(BOOL_VAL(isFalsey(pop()))); break;
case OP_NEGATE:
就像我们之前的一元运算符一样,它弹出唯一操作数,执行运算,然后压入结果。而且,就像我们在那里所做的那样,我们必须担心动态类型。对 true 进行逻辑非运算很容易,但没有任何东西可以阻止一个不守规矩的程序员编写这样的代码
print !nil;
对于一元减,我们将对任何不是 数字 的值进行取反都定义为错误。但是,Lox 与大多数脚本语言一样,在 ! 和其他需要布尔值的上下文中,会更加宽容。其他类型的处理规则称为“假值”,我们在这里实现了它
在 peek() 后添加
static bool isFalsey(Value value) { return IS_NIL(value) || (IS_BOOL(value) && !AS_BOOL(value)); }
Lox 遵循 Ruby 的原则,即 nil 和 false 是假值,其他所有值都表现得像 true。我们有了可以生成的新的指令,因此我们也需要能够在反汇编器中取消生成它。
case OP_DIVIDE:
return simpleInstruction("OP_DIVIDE", offset);
在 disassembleInstruction() 中
case OP_NOT: return simpleInstruction("OP_NOT", offset);
case OP_NEGATE:
18 . 4 . 2相等运算符和比较运算符
这还不错。让我们保持这种势头,继续完成相等运算符和比较运算符:==、!=、<、>、<= 和 >=。这涵盖了除了逻辑运算符 and 和 or 之外的所有返回布尔值结果的运算符。由于它们需要短路(基本上是执行一些控制流),因此我们还没准备好处理它们。
以下是这些运算符的新的指令
OP_FALSE,
在 enum OpCode 中
OP_EQUAL, OP_GREATER, OP_LESS,
OP_ADD,
等等,只有三个?!=、<= 和 >= 呢?我们可以为它们创建指令。说实话,如果目标是性能,那么我们应该这样做,这样虚拟机执行速度会更快。
我的主要目标是教你关于字节码编译器。我希望你开始将这个概念内化,即字节码指令不需要紧密地遵循用户的源代码。虚拟机可以自由地使用它想要的任何指令集和代码序列,只要它们具有正确的用户可见行为。
表达式 a != b 与 !(a == b) 具有相同的语义,因此编译器可以自由地将前者编译为后者。它可以输出一个 OP_EQUAL 然后是一个 OP_NOT,而不是一个专门的 OP_NOT_EQUAL 指令。同样,a <= b 与 !(a > b) 相同,而 a >= b 与 !(a < b) 相同。因此,我们只需要三个新的指令。
不过,在解析器中,我们确实有六个新的运算符要放到解析表中。我们使用之前相同的 binary() 解析器函数。这是 != 的行
[TOKEN_BANG] = {unary, NULL, PREC_NONE},
替换 1 行
[TOKEN_BANG_EQUAL] = {NULL, binary, PREC_EQUALITY},
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
其余五个运算符在表中稍远一些。
[TOKEN_EQUAL] = {NULL, NULL, PREC_NONE},
替换 5 行
[TOKEN_EQUAL_EQUAL] = {NULL, binary, PREC_EQUALITY}, [TOKEN_GREATER] = {NULL, binary, PREC_COMPARISON}, [TOKEN_GREATER_EQUAL] = {NULL, binary, PREC_COMPARISON}, [TOKEN_LESS] = {NULL, binary, PREC_COMPARISON}, [TOKEN_LESS_EQUAL] = {NULL, binary, PREC_COMPARISON},
[TOKEN_IDENTIFIER] = {NULL, NULL, PREC_NONE},
在 binary() 中,我们已经有一个 switch 来为每个标记类型生成正确的字节码。我们为六个新的运算符添加了 cases。
switch (operatorType) {
在 binary() 中
case TOKEN_BANG_EQUAL: emitBytes(OP_EQUAL, OP_NOT); break; case TOKEN_EQUAL_EQUAL: emitByte(OP_EQUAL); break; case TOKEN_GREATER: emitByte(OP_GREATER); break; case TOKEN_GREATER_EQUAL: emitBytes(OP_LESS, OP_NOT); break; case TOKEN_LESS: emitByte(OP_LESS); break; case TOKEN_LESS_EQUAL: emitBytes(OP_GREATER, OP_NOT); break;
case TOKEN_PLUS: emitByte(OP_ADD); break;
==、< 和 > 运算符输出单个指令。其他运算符输出一对指令,一个用于评估逆运算,然后一个 OP_NOT 用于翻转结果。六个运算符,三个指令的价格!
这意味着在 VM 中,我们的工作更简单。相等是最通用的运算。
case OP_FALSE: push(BOOL_VAL(false)); break;
在 run() 中
case OP_EQUAL: { Value b = pop(); Value a = pop(); push(BOOL_VAL(valuesEqual(a, b))); break; }
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
你可以对任何一对对象评估 ==,即使是不同类型的对象。复杂性足够多,将该逻辑转移到一个单独的函数是有意义的。该函数始终返回一个 C bool,因此我们可以安全地将结果包装在一个 BOOL_VAL 中。该函数与值相关,因此它存在于“值”模块中。
} ValueArray;
在结构 ValueArray 后添加
bool valuesEqual(Value a, Value b);
void initValueArray(ValueArray* array);
这是实现
在 printValue() 后添加
bool valuesEqual(Value a, Value b) { if (a.type != b.type) return false; switch (a.type) { case VAL_BOOL: return AS_BOOL(a) == AS_BOOL(b); case VAL_NIL: return true; case VAL_NUMBER: return AS_NUMBER(a) == AS_NUMBER(b); default: return false; // Unreachable. } }
首先,我们检查类型。如果 Value 的类型不同,它们肯定不相等。否则,我们解开这两个 Value 并直接比较它们。
对于每种值类型,我们都有一个单独的 case 来处理值的比较。鉴于 cases 之间的相似性,你可能会想知道为什么我们不能简单地 memcmp() 两个 Value 结构并完成它。问题在于,由于填充和不同大小的联合字段,Value 包含未使用的位。C 不保证这些位中有什么,因此两个相等的 Value 实际上可能在内存中有所不同,而这些内存没有被使用。
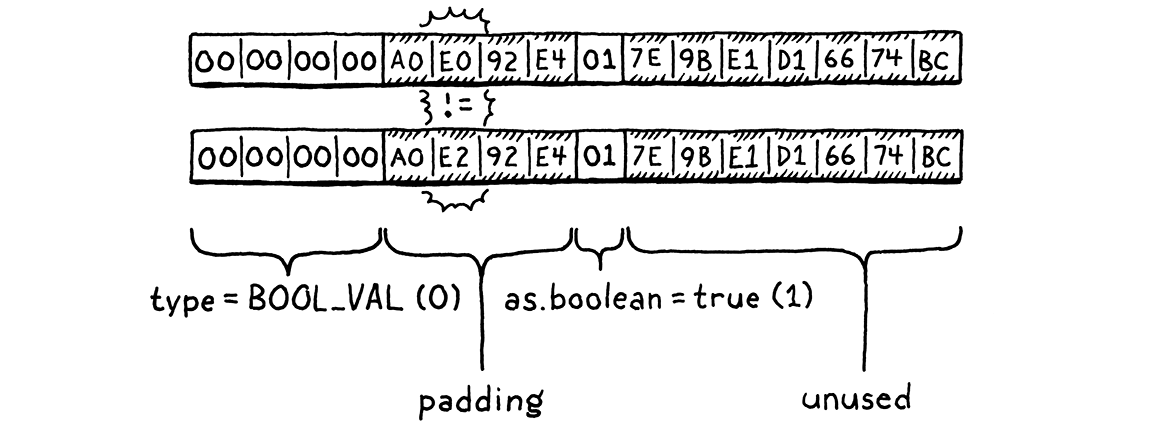
(你不会相信我在学会这个事实之前经历了多少痛苦。)
无论如何,随着我们在 clox 中添加更多类型,这个函数将增加新的 cases。目前,这三个就足够了。其他比较运算符更容易,因为它们只对数字起作用。
push(BOOL_VAL(valuesEqual(a, b)));
break;
}
在 run() 中
case OP_GREATER: BINARY_OP(BOOL_VAL, >); break; case OP_LESS: BINARY_OP(BOOL_VAL, <); break;
case OP_ADD: BINARY_OP(NUMBER_VAL, +); break;
我们已经扩展了 BINARY_OP 宏来处理返回非数值类型的运算符。现在我们可以使用它了。我们传入 BOOL_VAL,因为结果值类型是布尔值。否则,它与加号或减号没有区别。
与往常一样,今天咏叹调的尾声是反汇编新指令。
case OP_FALSE:
return simpleInstruction("OP_FALSE", offset);
在 disassembleInstruction() 中
case OP_EQUAL: return simpleInstruction("OP_EQUAL", offset); case OP_GREATER: return simpleInstruction("OP_GREATER", offset); case OP_LESS: return simpleInstruction("OP_LESS", offset);
case OP_ADD:
有了这些,我们的数值计算器已经变成了更接近通用表达式求值器的东西。启动 clox 并输入
!(5 - 4 > 3 * 2 == !nil)
好吧,我承认这可能不是最有用的表达式,但我们正在取得进展。我们缺少一种内置类型及其自己的字面形式:字符串。这些更复杂,因为字符串的大小可能不同。这种微小的差异会产生巨大的影响,以至于我们给字符串专门 开辟了一章。
挑战
-
我们可以将我们的二元运算符减少到比我们在这里做的更少。你还可以消除哪些其他指令,以及编译器如何应对它们的缺失?
-
相反,我们可以通过添加更多特定指令来提高字节码 VM 的速度,这些指令对应于更高级别的运算。你会定义哪些指令来加快我们本章中添加支持的用户代码的执行速度?