按需扫描
文学是用二十六个语音符号、十个阿拉伯数字和大约八个标点符号,以水平线形式进行的独特排列。
科特·冯内古特,像与上帝握手:关于写作的对话
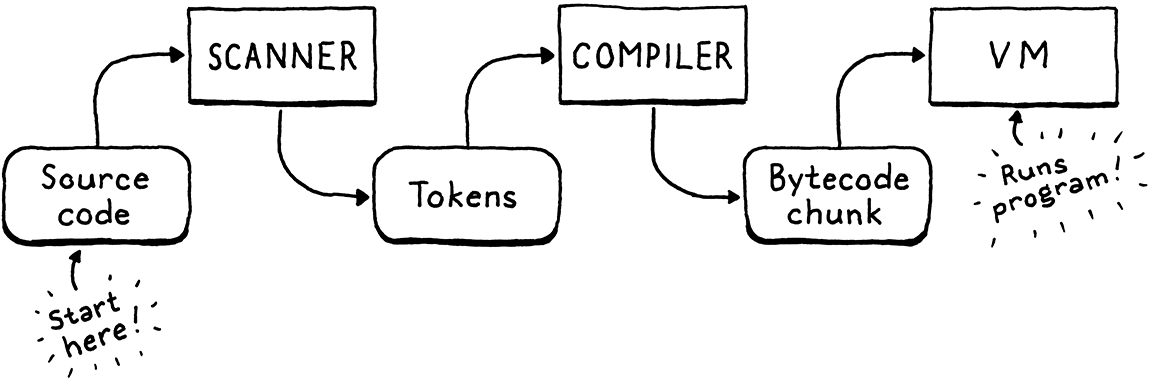
我们的第二个解释器 clox 包含三个阶段—扫描器、编译器和虚拟机。一个数据结构连接了每对阶段。标记从扫描器流向编译器,而字节码块从编译器流向虚拟机。我们从 块 和 虚拟机 开始实现,现在,我们将回到起点,构建一个生成标记的扫描器。在 下一章 中,我们将用我们的字节码编译器将两端连接在一起。
我承认,这不是本书中最激动人心的章节。对同一种语言进行两次实现,肯定会有一些冗余。与 jlox 的扫描器相比,我确实偷偷地加入了一些有趣的差异。继续阅读以了解它们是什么。
16 . 1启动解释器
现在我们正在构建前端,我们可以让 clox 像真正的解释器一样运行。不再需要手工编写的字节码块。现在是 REPL 和脚本加载的时候了。将 main() 中的大部分代码删除,并用以下代码替换。
int main(int argc, const char* argv[]) {
initVM();
在 main() 中
替换 26 行
if (argc == 1) { repl(); } else if (argc == 2) { runFile(argv[1]); } else { fprintf(stderr, "Usage: clox [path]\n"); exit(64); } freeVM();
return 0; }
如果你向可执行文件传递 没有参数,你就会进入 REPL。单个命令行参数被理解为要运行的脚本的路径。
我们需要一些系统头文件,所以让我们先把它们都处理掉。
添加到文件顶部
#include <stdio.h> #include <stdlib.h> #include <string.h>
#include "common.h"
接下来,我们启动 REPL 并让它运行。
#include "vm.h"
static void repl() { char line[1024]; for (;;) { printf("> "); if (!fgets(line, sizeof(line), stdin)) { printf("\n"); break; } interpret(line); } }
一个优质的 REPL 可以优雅地处理跨越多行的输入,并且没有硬编码的行长限制。这里这个 REPL 有点,嗯,简陋,但对于我们的目的来说已经足够了。
真正的工作发生在 interpret() 中。我们很快就会讲到它,但首先让我们处理脚本加载。
在 repl() 后添加
static void runFile(const char* path) { char* source = readFile(path); InterpretResult result = interpret(source); free(source); if (result == INTERPRET_COMPILE_ERROR) exit(65); if (result == INTERPRET_RUNTIME_ERROR) exit(70); }
我们读取文件并执行生成的 Lox 源代码字符串。然后,根据结果,我们适当地设置退出代码,因为我们是谨慎的工具构建者,并且关心像这样的细微细节。
我们还需要释放源代码字符串,因为 readFile() 动态分配了它,并将所有权传递给它的调用者。该函数看起来像这样
在 repl() 后添加
static char* readFile(const char* path) { FILE* file = fopen(path, "rb"); fseek(file, 0L, SEEK_END); size_t fileSize = ftell(file); rewind(file); char* buffer = (char*)malloc(fileSize + 1); size_t bytesRead = fread(buffer, sizeof(char), fileSize, file); buffer[bytesRead] = '\0'; fclose(file); return buffer; }
像很多 C 代码一样,它需要比看起来更复杂,特别是对于专门为操作系统设计的语言来说。困难之处在于,我们希望分配一个足够大的字符串来读取整个文件,但是直到我们读取完文件才知道文件有多大。
这里的代码是解决这个问题的经典技巧。我们打开文件,但在读取之前,我们使用 fseek() 寻找文件的末尾。然后我们调用 ftell(),它告诉我们距离文件开头多少字节。由于我们寻找的是末尾,所以这就是文件的大小。我们重新回到开头,分配一个该 大小 的字符串,并一次性读取整个文件。
所以我们做完了,对吧?还没。这些函数调用,就像 C 标准库中的大多数调用一样,可能会失败。如果这是 Java,这些失败将被抛出为异常,并自动解开堆栈,因此我们实际上不需要处理它们。在 C 中,如果我们不检查它们,它们会静默地被忽略。
这不是一本关于良好的 C 编程实践的书,但我不想鼓励不良风格,所以让我们继续处理错误。这对我们有好处,就像吃蔬菜或用牙线清洁牙齿一样。
幸运的是,如果发生失败,我们不需要做任何特别巧妙的事情。如果我们无法正确读取用户的脚本,我们唯一能做的就是告诉用户,并优雅地退出解释器。首先,我们可能无法打开文件。
FILE* file = fopen(path, "rb");
在 readFile() 中
if (file == NULL) { fprintf(stderr, "Could not open file \"%s\".\n", path); exit(74); }
fseek(file, 0L, SEEK_END);
如果文件不存在,或者用户没有访问权限,就会发生这种情况。这很常见—人们经常拼错路径。
这种失败非常罕见
char* buffer = (char*)malloc(fileSize + 1);
在 readFile() 中
if (buffer == NULL) { fprintf(stderr, "Not enough memory to read \"%s\".\n", path); exit(74); }
size_t bytesRead = fread(buffer, sizeof(char), fileSize, file);
如果我们甚至无法分配足够的内存来读取 Lox 脚本,那么用户可能还有更大的问题要担心,但我们应该尽力至少让他们知道。
最后,读取本身也可能失败。
size_t bytesRead = fread(buffer, sizeof(char), fileSize, file);
在 readFile() 中
if (bytesRead < fileSize) { fprintf(stderr, "Could not read file \"%s\".\n", path); exit(74); }
buffer[bytesRead] = '\0';
这也可能性很低。实际上, 调用 fseek()、ftell() 和 rewind() 理论上也可能失败,但我们不要走得太远,好吗?
16 . 1 . 1打开编译管道
我们已经拥有一个 Lox 源代码字符串,所以现在我们准备建立一个管道来扫描、编译和执行它。它由 interpret() 驱动。现在,该函数运行我们以前硬编码的测试块。让我们将其更改为更接近最终实现的形式。
void freeVM();
函数 interpret()
替换 1 行
InterpretResult interpret(const char* source);
void push(Value value);
之前我们传入了一个 Chunk,现在我们传入源代码字符串。这是新的实现
函数 interpret()
替换 4 行
InterpretResult interpret(const char* source) { compile(source); return INTERPRET_OK;
}
我们不会在本章构建实际的编译器,但我们可以开始规划它的结构。它存在于一个新的模块中。
#include "common.h"
#include "compiler.h"
#include "debug.h"
现在,其中的一个函数声明如下
创建新文件
#ifndef clox_compiler_h #define clox_compiler_h void compile(const char* source); #endif
该签名将会改变,但这让我们开始。
编译的第一个阶段是扫描—我们在本章中做的事情—所以现在编译器所做的只是设置它。
创建新文件
#include <stdio.h> #include "common.h" #include "compiler.h" #include "scanner.h" void compile(const char* source) { initScanner(source); }
在以后的章节中,它也会自然地扩展。
16 . 1 . 2扫描器扫描
在我们可以开始编写有用的代码之前,还需要搭建一些脚手架。首先,一个新的头文件
创建新文件
#ifndef clox_scanner_h #define clox_scanner_h void initScanner(const char* source); #endif
以及相应的实现
创建新文件
#include <stdio.h> #include <string.h> #include "common.h" #include "scanner.h" typedef struct { const char* start; const char* current; int line; } Scanner; Scanner scanner;
当我们的扫描器咀嚼用户的源代码时,它会跟踪已经扫描了多少。就像我们在虚拟机中所做的那样,我们将该状态封装在一个结构体中,然后创建一个该类型的单个顶级模块变量,这样我们就不必将它传递给所有不同的函数。
令人惊讶的是,字段很少。start 指针标记正在扫描的当前词法单元的开头,而 current 指向当前正在查看的字符。

我们有一个 line 字段来跟踪当前词法单元所在的代码行,以便进行错误报告。就这样了!我们甚至没有保存指向源代码字符串开头的指针。扫描器一次性遍历代码,之后就完成了。
由于我们有一些状态,因此我们应该对其进行初始化。
在变量 scanner 后添加
void initScanner(const char* source) { scanner.start = source; scanner.current = source; scanner.line = 1; }
我们从第一行的第一个字符开始,就像一个蹲在起跑线上的跑步者。
16 . 2一次一个标记
在 jlox 中,发令枪响后,扫描器会向前冲刺,并急切地扫描整个程序,返回一个标记列表。这在 clox 中将是一个挑战。我们需要某种可增长的数组或列表来存储标记。我们需要管理标记的分配和释放,以及集合本身。这需要很多代码,以及大量的内存抖动。
在任何时间点,编译器只需要一个或两个标记—记住我们的语法只需要一个标记的超前预测—所以我们不需要将所有标记都保留在内存中。相反,最简单的解决方案是在编译器需要一个标记之前不扫描它。当扫描器提供一个标记时,它会按值返回该标记。它不需要动态分配任何东西—它可以只是在 C 堆栈上传递标记。
不幸的是,我们还没有一个可以向扫描器请求标记的编译器,因此扫描器将只是在那里什么也不做。为了让它开始工作,我们将编写一些临时的代码来驱动它。
initScanner(source);
在 compile() 中
int line = -1; for (;;) { Token token = scanToken(); if (token.line != line) { printf("%4d ", token.line); line = token.line; } else { printf(" | "); } printf("%2d '%.*s'\n", token.type, token.length, token.start); if (token.type == TOKEN_EOF) break; }
}
这会无限循环。循环的每次迭代都会扫描一个标记并将其打印出来。当它到达一个特殊的“文件结尾”标记或错误时,它就会停止。例如,如果我们在该程序上运行解释器
print 1 + 2;
它会打印出来
1 31 'print' | 21 '1' | 7 '+' | 21 '2' | 8 ';' 2 39 ''
第一列是行号,第二列是标记 类型 的数值,最后是词法单元。第 2 行上的最后一个空词法单元是 EOF 标记。
本章剩余部分的目标是通过实现此关键函数使该代码块工作
void initScanner(const char* source);
在 initScanner() 后添加
Token scanToken();
#endif
每次调用都会扫描并返回源代码中的下一个令牌。令牌看起来像这样
#define clox_scanner_h
typedef struct { TokenType type; const char* start; int length; int line; } Token;
void initScanner(const char* source);
它与 jlox 的 Token 类非常相似。我们有一个枚举来标识令牌的类型—数字、标识符、+ 运算符等。枚举与 jlox 中的枚举几乎相同,所以让我们直接完成所有事情。
#ifndef clox_scanner_h #define clox_scanner_h
typedef enum { // Single-character tokens. TOKEN_LEFT_PAREN, TOKEN_RIGHT_PAREN, TOKEN_LEFT_BRACE, TOKEN_RIGHT_BRACE, TOKEN_COMMA, TOKEN_DOT, TOKEN_MINUS, TOKEN_PLUS, TOKEN_SEMICOLON, TOKEN_SLASH, TOKEN_STAR, // One or two character tokens. TOKEN_BANG, TOKEN_BANG_EQUAL, TOKEN_EQUAL, TOKEN_EQUAL_EQUAL, TOKEN_GREATER, TOKEN_GREATER_EQUAL, TOKEN_LESS, TOKEN_LESS_EQUAL, // Literals. TOKEN_IDENTIFIER, TOKEN_STRING, TOKEN_NUMBER, // Keywords. TOKEN_AND, TOKEN_CLASS, TOKEN_ELSE, TOKEN_FALSE, TOKEN_FOR, TOKEN_FUN, TOKEN_IF, TOKEN_NIL, TOKEN_OR, TOKEN_PRINT, TOKEN_RETURN, TOKEN_SUPER, TOKEN_THIS, TOKEN_TRUE, TOKEN_VAR, TOKEN_WHILE, TOKEN_ERROR, TOKEN_EOF } TokenType;
typedef struct {
除了将所有名称加上 TOKEN_ 前缀(因为 C 会将枚举名称放在顶层命名空间中)之外,唯一的区别是额外的 TOKEN_ERROR 类型。这是怎么回事?
扫描过程中只会检测到两种错误:未终止的字符串和无法识别的字符。在 jlox 中,扫描器会自行报告这些错误。在 clox 中,扫描器会为该错误生成一个合成“错误”令牌,并将其传递给编译器。这样,编译器就知道发生了错误,并且可以在报告错误之前启动错误恢复。
clox 的 Token 类型中的新颖之处在于它如何表示词素。在 jlox 中,每个 Token 都将词素存储为它自己独立的小型 Java 字符串。如果我们对 clox 也这样做,我们将不得不弄清楚如何管理这些字符串的内存。这尤其困难,因为我们按值传递令牌—多个令牌可能指向同一个词素字符串。所有权变得很奇怪。
相反,我们使用原始源字符串作为我们的字符存储。我们通过指向其第一个字符的指针和它包含的字符数量来表示词素。这意味着我们根本不需要担心管理词素的内存,并且可以随意复制令牌。只要主源代码字符串 比所有令牌的生存期更长,一切都会正常工作。
16 . 2 . 1扫描令牌
我们已经准备好扫描一些令牌。我们将逐步构建完整的实现,从这里开始
在 initScanner() 后添加
Token scanToken() { scanner.start = scanner.current; if (isAtEnd()) return makeToken(TOKEN_EOF); return errorToken("Unexpected character."); }
由于每次调用此函数都会扫描一个完整的令牌,所以我们知道当我们进入函数时,我们处于新令牌的开头。因此,我们将 scanner.start 设置为指向当前字符,以便我们记住将要扫描的词素从哪里开始。
然后,我们检查是否已到达源代码的末尾。如果是,则返回一个 EOF 令牌并停止。这是一个哨兵值,它向编译器发出信号,停止请求更多令牌。
如果我们没有到达末尾,我们会做一些 . . . 东西 . . . 来扫描下一个令牌。但是我们还没有编写该代码。我们很快就会做到。如果该代码无法成功扫描并返回令牌,那么我们将到达函数的末尾。这意味着我们遇到了扫描器无法识别的字符,因此我们将为该字符返回一个错误令牌。
此函数依赖于几个辅助函数,其中大多数来自 jlox。首先
在 initScanner() 后添加
static bool isAtEnd() { return *scanner.current == '\0'; }
我们要求源字符串是一个良好的以空字符结尾的 C 字符串。如果当前字符为空字节,那么我们已经到达末尾。
要创建一个令牌,我们有这个类似构造函数的函数
在 isAtEnd() 后添加
static Token makeToken(TokenType type) { Token token; token.type = type; token.start = scanner.start; token.length = (int)(scanner.current - scanner.start); token.line = scanner.line; return token; }
它使用扫描器的 start 和 current 指针来捕获令牌的词素。它设置了一些其他明显的字段,然后返回令牌。它有一个用于返回错误令牌的姊妹函数。
在 makeToken() 后添加
static Token errorToken(const char* message) { Token token; token.type = TOKEN_ERROR; token.start = message; token.length = (int)strlen(message); token.line = scanner.line; return token; }
唯一的区别是“词素”指向错误消息字符串,而不是指向用户源代码中的位置。同样,我们需要确保错误消息坚持足够长的时间,以供编译器读取。实际上,我们只使用 C 字符串文字调用此函数。这些是恒定且永恒的,所以我们没事。
我们现在所拥有的基本上是一个适用于具有空词法语法的语言的工作扫描器。由于语法没有产生式,因此每个字符都是错误的。这并不是一种很有趣的编程语言,所以让我们补充一下规则。
16 . 3Lox 的词法语法
最简单的令牌只有一个字符。我们像这样识别它们
if (isAtEnd()) return makeToken(TOKEN_EOF);
在 scanToken() 中
char c = advance(); switch (c) { case '(': return makeToken(TOKEN_LEFT_PAREN); case ')': return makeToken(TOKEN_RIGHT_PAREN); case '{': return makeToken(TOKEN_LEFT_BRACE); case '}': return makeToken(TOKEN_RIGHT_BRACE); case ';': return makeToken(TOKEN_SEMICOLON); case ',': return makeToken(TOKEN_COMMA); case '.': return makeToken(TOKEN_DOT); case '-': return makeToken(TOKEN_MINUS); case '+': return makeToken(TOKEN_PLUS); case '/': return makeToken(TOKEN_SLASH); case '*': return makeToken(TOKEN_STAR); }
return errorToken("Unexpected character.");
我们从源代码中读取下一个字符,然后进行一个简单的 switch 操作,以查看它是否与 Lox 的任何一个字符词素匹配。要读取下一个字符,我们使用一个新的辅助函数,该函数会消耗当前字符并将其返回。
在 isAtEnd() 后添加
static char advance() { scanner.current++; return scanner.current[-1]; }
接下来是 != 和 >= 等两个字符的标点符号令牌。它们中的每一个都有一个相应的单字符令牌。这意味着当我们看到一个像 ! 这样的字符时,我们不知道它是在 ! 令牌中还是在 != 中,直到我们查看下一个字符。我们像这样处理它们
case '*': return makeToken(TOKEN_STAR);
在 scanToken() 中
case '!': return makeToken( match('=') ? TOKEN_BANG_EQUAL : TOKEN_BANG); case '=': return makeToken( match('=') ? TOKEN_EQUAL_EQUAL : TOKEN_EQUAL); case '<': return makeToken( match('=') ? TOKEN_LESS_EQUAL : TOKEN_LESS); case '>': return makeToken( match('=') ? TOKEN_GREATER_EQUAL : TOKEN_GREATER);
}
在消耗第一个字符之后,我们查找 =。如果找到,则消耗它并返回相应的两个字符令牌。否则,我们将当前字符保留原样(以便它可以成为下一个令牌的一部分),并返回相应的单字符令牌。
用于有条件地消耗第二个字符的逻辑存在于这里
在 advance() 后添加
static bool match(char expected) { if (isAtEnd()) return false; if (*scanner.current != expected) return false; scanner.current++; return true; }
如果当前字符是所需的字符,则我们前进并返回 true。否则,我们返回 false 以指示它没有匹配。
现在,我们的扫描器支持所有类似标点符号的令牌。在我们开始使用更长的令牌之前,让我们先进行一个小小的旅行,处理不是令牌一部分的字符。
16 . 3 . 1空白
我们的扫描器需要处理空格、制表符和换行符,但这些字符不会成为任何令牌词素的一部分。我们可以在 scanToken() 中的主要字符 switch 语句中检查这些字符,但要确保该函数在调用后仍然可以正确地找到下一个令牌,这有点棘手。我们将不得不将整个函数体包装在一个循环中或类似的东西。
相反,在开始令牌之前,我们将跳转到一个单独的函数。
Token scanToken() {
在 scanToken() 中
skipWhitespace();
scanner.start = scanner.current;
这会将扫描器向前移动,跳过任何前导空白。此调用返回后,我们知道下一个字符是有意义的(或者我们已经到达源代码的末尾)。
在 errorToken() 后添加
static void skipWhitespace() { for (;;) { char c = peek(); switch (c) { case ' ': case '\r': case '\t': advance(); break; default: return; } } }
它是一种独立的小型扫描器。它循环,消耗它遇到的每个空白字符。我们需要小心,它不要消耗任何非空白字符。为了支持这一点,我们使用这个
在 advance() 后添加
static char peek() { return *scanner.current; }
它只是返回当前字符,但不会消耗它。前面的代码处理除换行符之外的所有空白字符。
break;
在 skipWhitespace() 中
case '\n': scanner.line++; advance(); break;
default:
return;
当我们消耗其中一个时,我们还会增加当前行号。
16 . 3 . 2注释
从严格意义上讲,注释并不是“空白”,如果你想在术语上精确一点,但就 Lox 而言,它们可以是空白,所以我们也跳过它们。
break;
在 skipWhitespace() 中
case '/': if (peekNext() == '/') { // A comment goes until the end of the line. while (peek() != '\n' && !isAtEnd()) advance(); } else { return; } break;
default:
return;
注释以 Lox 中的 // 开头,因此与 != 及其朋友一样,我们需要第二个字符的预读。但是,对于 !=,即使没有找到 =,我们仍然希望消耗 !。注释不同。如果我们没有找到第二个 /,那么 skipWhitespace() 也不需要消耗第一个斜杠。
为了处理这种情况,我们添加了
在 peek() 后添加
static char peekNext() { if (isAtEnd()) return '\0'; return scanner.current[1]; }
这就像 peek() 一样,但对于当前字符之后的第一个字符。如果当前字符和下一个字符都是 /,则我们消耗它们,然后消耗任何其他字符,直到下一个换行符或源代码的末尾。
我们使用 peek() 来检查换行符,但不会消耗它。这样,换行符将成为 skipWhitespace() 中外部循环的下一轮的当前字符,我们将识别它并增加 scanner.line。
16 . 3 . 3文字令牌
数字和字符串令牌很特殊,因为它们具有与之关联的运行时值。我们将从字符串开始,因为它们很容易识别—它们总是以双引号开头。
match('=') ? TOKEN_GREATER_EQUAL : TOKEN_GREATER);
在 scanToken() 中
case '"': return string();
}
它调用一个新的函数。
在 skipWhitespace() 后添加
static Token string() { while (peek() != '"' && !isAtEnd()) { if (peek() == '\n') scanner.line++; advance(); } if (isAtEnd()) return errorToken("Unterminated string."); // The closing quote. advance(); return makeToken(TOKEN_STRING); }
与 jlox 类似,我们消耗字符,直到到达结束引号。我们还跟踪字符串文字中的换行符。(Lox 支持多行字符串。)并且,像往常一样,我们优雅地处理在找到结束引号之前用尽源代码的情况。
clox 中的主要变化是这里没有的东西。同样,它与内存管理有关。在 jlox 中,Token 类有一个类型为 Object 的字段,用于存储从文字令牌的词素转换而来的运行时值。
在 C 中实现这一点需要大量工作。我们需要某种联合和类型标记,以判断令牌是包含字符串还是双精度值。如果是字符串,我们将需要以某种方式管理字符串字符数组的内存。
与其在扫描器中添加这种复杂性,不如将转换文字词素为运行时值的工作推迟到以后。在 clox 中,令牌只存储词素—与用户源代码中显示的字符序列完全相同。稍后在编译器中,当我们准备好将其存储在块的常量表中时,我们将把该词素转换为运行时值。
接下来是数字。与其为每个可以启动数字的十位数字添加一个 switch case,不如我们在这里处理它们
char c = advance();
在 scanToken() 中
if (isDigit(c)) return number();
switch (c) {
它使用这个显而易见的实用程序函数
在 initScanner() 后添加
static bool isDigit(char c) { return c >= '0' && c <= '9'; }
我们使用这个来完成扫描数字的工作
在 skipWhitespace() 后添加
static Token number() { while (isDigit(peek())) advance(); // Look for a fractional part. if (peek() == '.' && isDigit(peekNext())) { // Consume the ".". advance(); while (isDigit(peek())) advance(); } return makeToken(TOKEN_NUMBER); }
它与 jlox 的版本几乎相同,除了再次,我们还没有将词素转换为双精度值。
16 . 4标识符和关键字
最后一批令牌是标识符,既包括用户定义的,也包括保留的。这一部分应该很有趣—我们识别 clox 中关键字的方式与我们在 jlox 中使用的方式完全不同,并涉及一些重要的数据结构。
首先,我们必须扫描词素。名称以字母或下划线开头。
char c = advance();
在 scanToken() 中
if (isAlpha(c)) return identifier();
if (isDigit(c)) return number();
我们使用这个来识别它们
在 initScanner() 后添加
static bool isAlpha(char c) { return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_'; }
找到标识符后,我们在这里扫描它的剩余部分
在 skipWhitespace() 后添加
static Token identifier() { while (isAlpha(peek()) || isDigit(peek())) advance(); return makeToken(identifierType()); }
在第一个字母之后,我们也允许使用数字,并且我们继续消耗字母数字,直到用完它们。然后,我们生成一个类型正确的令牌。确定这个“正确”类型是本章的独特部分。
在 skipWhitespace() 后添加
static TokenType identifierType() { return TOKEN_IDENTIFIER; }
好吧,我猜这还没有什么可激动的。如果我们根本没有保留字,它看起来就是这样。我们应该如何识别关键字?在 jlox 中,我们将它们全部塞进一个 Java Map 中,并按名称查找它们。在 clox 中,我们没有任何类型的哈希表结构,至少现在还没有。
哈希表也是过分了。要在哈希表中查找一个字符串,我们需要遍历该字符串来计算它的哈希码,找到哈希表中相应的桶,然后对它碰巧在那里找到的任何字符串进行逐字符的相等性比较。
假设我们扫描到了标识符“gorgonzola”。我们应该做多少工作才能判断它是否是一个保留字呢?嗯,没有 Lox 关键字以“g”开头,所以只需查看第一个字符就足以确定答案是“否”。这比哈希表查找简单得多。
那“cardigan”呢?Lox 中确实有一个以“c”开头的关键字:“class”。但“cardigan”的第二个字符“a”排除了这种情况。那“forest”呢?由于“for”是关键字,我们需要在字符串中深入一点才能确定它不是保留字。但是,在大多数情况下,只需要一两个字符就能判断出我们遇到了用户定义的名称。我们应该能够识别这一点并快速失败。
这是一个表示这种分枝字符检查逻辑的视觉图。
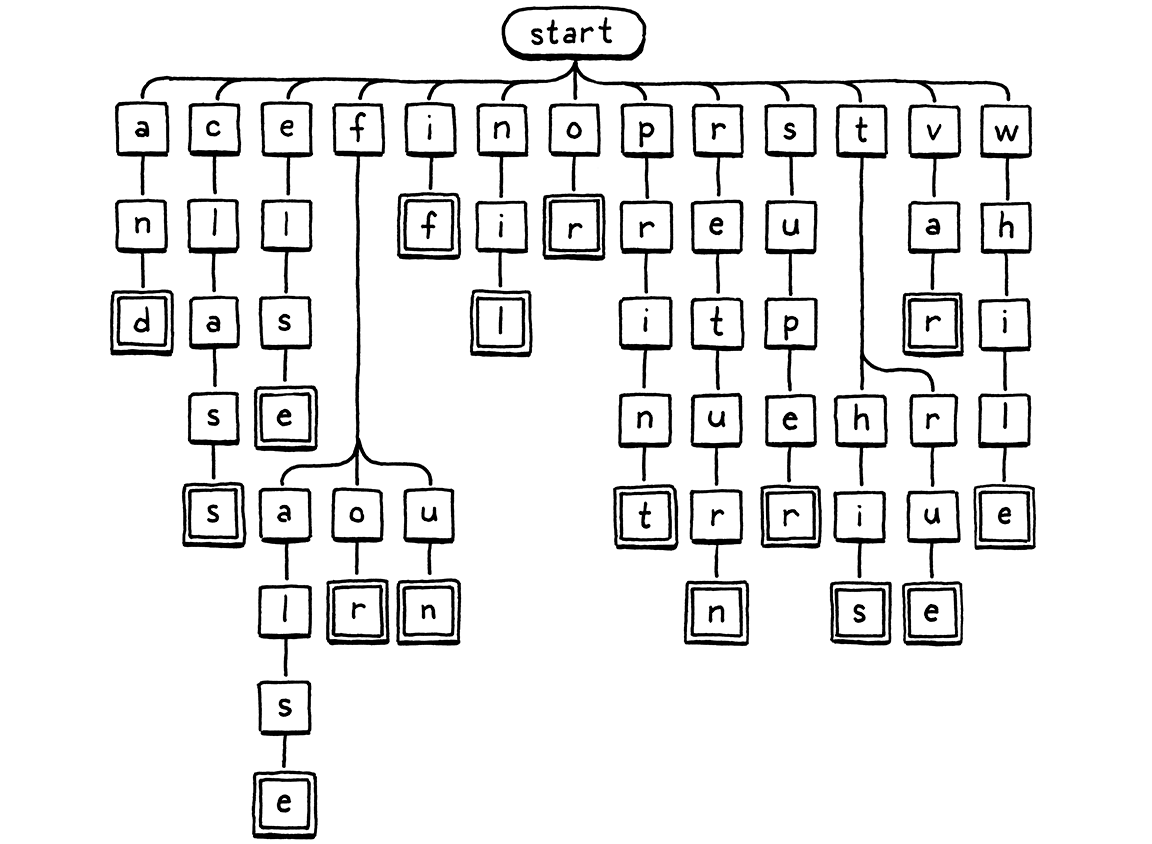
我们从根节点开始。如果有一个子节点的字母与词素的第一个字符匹配,我们就移动到该节点。然后对词素中的下一个字母重复此操作,依此类推。如果在任何时候,词素中的下一个字母与子节点不匹配,则标识符一定不是关键字,我们停止。如果我们到达一个双线框,并且我们已经到达词素的最后一个字符,那么我们找到了一个关键字。
16 . 4 . 1Tries 和状态机
这个树形图是一个名为trie的事物的例子。Trie 存储一组字符串。大多数其他用于存储字符串的数据结构包含原始字符数组,然后将它们包装在一些更大的结构中,以帮助你更快地搜索。Trie 则有所不同。在 trie 中,你不会找到完整的字符串。
相反,trie “包含”的每个字符串都表示为路径,穿过字符节点的树,就像我们在上面的遍历中一样。与字符串中最后一个字符匹配的节点有一个特殊的标记—图示中的双线框。这样,如果你的 trie 包含,比如,“banquet”和“ban”,你就能分辨出它不包含“banque”—“e”节点不会有那个标记,而“n”和“t”节点会有。
Tries 是一个更基本的数据结构的特例:确定性有限自动机 (DFA)。你可能也用其他名字知道它们:有限状态机,或简称为状态机。状态机很酷。它们最终在从游戏编程到实现网络协议的一切事物中都派上了用场。
在 DFA 中,你有一组带有转换的状态,形成一个图。在任何时候,机器都“处于”一个状态。它通过遵循转换到达其他状态。当你在词法分析中使用 DFA 时,每个转换都是从字符串中匹配的字符。每个状态都表示一组允许的字符。
我们的关键字树正好是一个识别 Lox 关键字的 DFA。但 DFA 比简单的树更强大,因为它们可以是任意的图。转换可以在状态之间形成循环。这让你可以识别任意长的字符串。例如,这里有一个识别数字字面量的 DFA
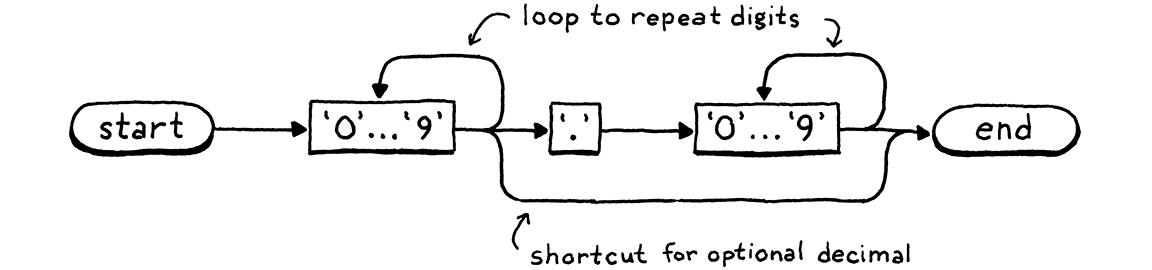
为了保持可读性,我把十位数字的节点合并在一起,但基本过程是一样的—你沿着路径工作,每当你消费词素中的一个对应字符时,就进入节点。如果我们愿意,我们可以构建一个巨大的 DFA 来执行所有 Lox 的词法分析,一个识别并输出我们所需的所有标记的单一状态机。
然而,通过手工制作那个超级 DFA 会很困难。这就是Lex被创建的原因。你给它一个简单的词法语法的文本描述—一堆正则表达式—它会自动为你生成一个 DFA,并生成一堆实现它的 C 代码。
我们不会走这条路。我们已经有一个完全可用的手工制作的扫描器。我们只需要一个小的 trie 来识别关键字。我们应该如何把它映射到代码中呢?
最简单的解决方案是为每个节点使用一个 switch 语句,其中包含每个分支的 case。我们将从根节点开始,处理简单的关键字。
static TokenType identifierType() {
在 identifierType() 中
switch (scanner.start[0]) { case 'a': return checkKeyword(1, 2, "nd", TOKEN_AND); case 'c': return checkKeyword(1, 4, "lass", TOKEN_CLASS); case 'e': return checkKeyword(1, 3, "lse", TOKEN_ELSE); case 'i': return checkKeyword(1, 1, "f", TOKEN_IF); case 'n': return checkKeyword(1, 2, "il", TOKEN_NIL); case 'o': return checkKeyword(1, 1, "r", TOKEN_OR); case 'p': return checkKeyword(1, 4, "rint", TOKEN_PRINT); case 'r': return checkKeyword(1, 5, "eturn", TOKEN_RETURN); case 's': return checkKeyword(1, 4, "uper", TOKEN_SUPER); case 'v': return checkKeyword(1, 2, "ar", TOKEN_VAR); case 'w': return checkKeyword(1, 4, "hile", TOKEN_WHILE); }
return TOKEN_IDENTIFIER;
这些是对应于单个关键字的初始字母。如果我们看到一个“s”,那么标识符唯一可能存在的关键字就是super。虽然它可能不是,但我们仍然需要检查其余的字母。在树形图中,这基本上就是从“s”挂下来的那条直线路径。
我们不会为每个节点都编写一个 switch。相反,我们有一个实用程序函数来测试潜在关键字词素的剩余部分。
在 skipWhitespace() 后添加
static TokenType checkKeyword(int start, int length, const char* rest, TokenType type) { if (scanner.current - scanner.start == start + length && memcmp(scanner.start + start, rest, length) == 0) { return type; } return TOKEN_IDENTIFIER; }
我们对树中所有不分枝的路径使用它。一旦我们找到了一个可能只有一个可能的保留字的前缀,我们就需要验证两件事。词素的长度必须与关键字完全相同。如果第一个字母是“s”,那么词素仍然可能是“sup”或“superb”。而且其余字符必须完全匹配—“supar”不够好。
如果我们有正确的字符数量,而且它们是我们想要的字符,那么它就是一个关键字,我们就返回相关的标记类型。否则,它一定是一个普通的标识符。
我们有一些关键字,它们的树在第一个字母之后又分枝。如果词素以“f”开头,它可能是false、for或fun。所以我们在从“f”节点分枝出来的分支上添加另一个 switch。
case 'e': return checkKeyword(1, 3, "lse", TOKEN_ELSE);
在 identifierType() 中
case 'f': if (scanner.current - scanner.start > 1) { switch (scanner.start[1]) { case 'a': return checkKeyword(2, 3, "lse", TOKEN_FALSE); case 'o': return checkKeyword(2, 1, "r", TOKEN_FOR); case 'u': return checkKeyword(2, 1, "n", TOKEN_FUN); } } break;
case 'i': return checkKeyword(1, 1, "f", TOKEN_IF);
在切换之前,我们需要检查是否存在第二个字母。毕竟,“f”本身也是一个有效的标识符。另一个分枝的字母是“t”。
case 's': return checkKeyword(1, 4, "uper", TOKEN_SUPER);
在 identifierType() 中
case 't': if (scanner.current - scanner.start > 1) { switch (scanner.start[1]) { case 'h': return checkKeyword(2, 2, "is", TOKEN_THIS); case 'r': return checkKeyword(2, 2, "ue", TOKEN_TRUE); } } break;
case 'v': return checkKeyword(1, 2, "ar", TOKEN_VAR);
就是这样。几个嵌套的switch语句。这不仅使代码很短,而且速度非常快。它执行检测关键字所需的最少工作量,并尽快退出,只要它能判断标识符不是保留字。
就这样,我们的扫描器完成了。
挑战
-
许多新语言支持字符串插值。在字符串字面量中,你有一些特殊的定界符—最常见的是
${开头和}结尾。在这些定界符之间,可以出现任何表达式。当字符串字面量被执行时,内部表达式被求值,转换为字符串,然后与周围的字符串字面量合并。例如,如果 Lox 支持字符串插值,那么 . . .
var drink = "Tea"; var steep = 4; var cool = 2; print "${drink} will be ready in ${steep + cool} minutes.";
. . . 将打印
Tea will be ready in 6 minutes.
你会定义哪些标记类型来实现字符串插值的扫描器?你会为上面的字符串字面量发出什么序列的标记?
你会为 . . .
"Nested ${"interpolation?! Are you ${"mad?!"}"}"考虑查看其他支持插值的语言实现,看看它们是如何处理的。
-
一些语言使用尖括号表示泛型,还使用
>>右移运算符。这导致了早期版本的 C++ 中的一个经典问题vector<vector<string>> nestedVectors;
这将产生编译错误,因为
>>被解析为单个右移标记,而不是两个>标记。用户被迫通过在结束尖括号之间添加空格来避免这种情况。更高版本的 C++ 更智能,可以处理上面的代码。Java 和 C# 从未遇到过这个问题。这些语言是如何指定和实现这一点的?
-
许多语言,尤其是在它们的演化后期,定义了“上下文关键字”。这些是充当某些上下文中保留字的标识符,但在其他上下文中可以是普通的用户定义标识符。
例如,
await是 C# 中async方法内部的关键字,但在其他方法中,你可以使用await作为你自己的标识符。列举一些其他语言中的上下文关键字,以及它们有意义的上下文。使用上下文关键字的优缺点是什么?如果你需要在你的语言前端实现它们,你将如何实现?