领域地图
无论地图多么粗糙,你都必须有一张地图。否则你就会漫无目的地四处游荡。在《指环王》中,我从不让人走得比他们一天能走的更远。
J. R. R. 托尔金
我们不想漫无目的地四处游荡,所以在我们出发之前,让我们先扫描一下之前语言实现者绘制的领域地图。这将有助于我们了解我们要到哪里,以及其他人采取的备用路线。
首先,让我建立一个速记。本书的大部分内容都是关于语言的实现,它与语言本身在某种柏拉图式的理想形式上是截然不同的。诸如“堆栈”、“字节码”和“递归下降”之类的术语,是特定实现可能使用的螺母和螺栓。从用户的角度来看,只要最终的装置忠实地遵循了语言的规范,它就是实现细节。
我们将花费大量时间讨论这些细节,所以如果我每次提到它们时都必须写“语言实现”,我会磨损我的手指。相反,我将使用“语言”来指代语言或其实现,或者两者兼而有之,除非区别很重要。
2 . 1语言的组成部分
工程师们从计算机的黑暗时代就开始构建编程语言。一旦我们能够与计算机对话,我们就发现这样做太难了,于是我们借助了它们的帮助。我发现,尽管今天的机器速度快了整整一百万倍,存储空间也大了几个数量级,但我们构建编程语言的方式几乎没有改变,这让我感到着迷。
虽然语言设计者探索的领域广阔,但他们开辟的路线却很少。并非每种语言都走完全一样的路径—有些语言会走一两个捷径—但在其他方面,它们令人欣慰地相似,从格蕾丝·霍珀海军少将的第一个 COBOL 编译器一直到某些流行的、新式的、转译到 JavaScript 的语言,其“文档”只包含一个存储在某个 Git 仓库中的、编辑得很差的 README 文件。
我将实现可能选择的路径网络可视化为攀登一座山。你从山脚开始,将程序作为原始的源代码文本,实际上只是一串字符。每个阶段都会分析程序,并将其转换为更高级别的表示形式,在这些表示形式中,语义—作者希望计算机执行的操作—变得更加清晰。
最终我们将到达山顶。我们对用户的程序有了鸟瞰的视角,可以看到他们的代码含义。我们开始从山的另一边向下走。我们将这种最高级别的表示形式转换为逐级降低级别的形式,以便越来越接近我们知道如何让 CPU 实际执行的内容。
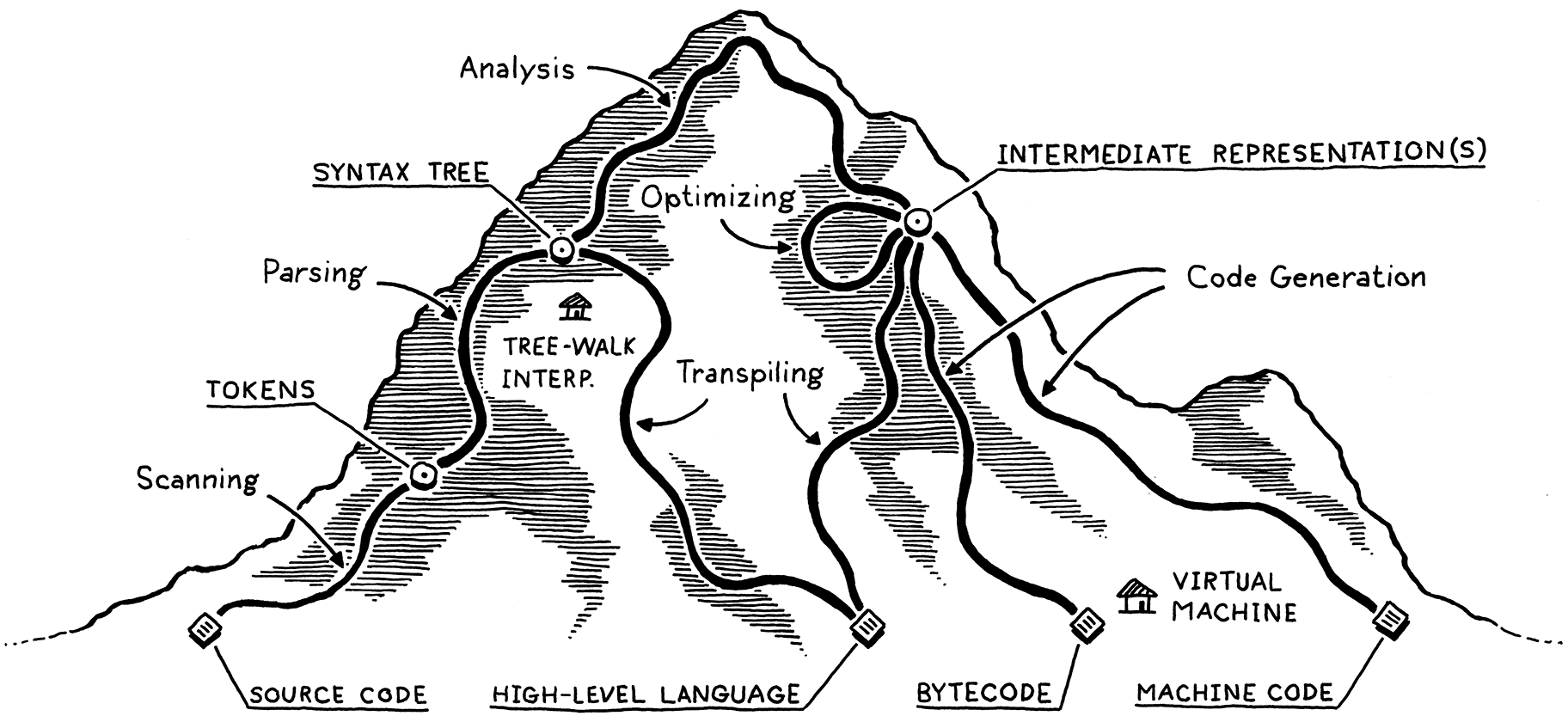
让我们追踪这些路线和兴趣点中的每一个。我们的旅程从左侧的用户源代码的裸文本开始

2 . 1 . 1扫描
第一步是扫描,也称为词法分析,或者(如果你想给别人留下深刻印象)词法分析。它们都意味着几乎相同的事情。我喜欢“词法分析”,因为它听起来像是邪恶的超级反派会做的事情,但我将使用“扫描”,因为它似乎更常见一些。
扫描器(或词法分析器)接收线性字符流,并将它们组合成一系列更类似于“单词”的东西。在编程语言中,这些单词中的每一个都称为标记。有些标记是单个字符,例如(和,。其他标记可能包含多个字符,例如数字(123)、字符串字面量("hi!")和标识符(min)。
源文件中的某些字符实际上没有任何意义。空白通常无关紧要,注释根据定义会被语言忽略。扫描器通常会丢弃这些字符,留下一个干净的有意义的标记序列。
![[var] [average] [=] [(] [min] [+] [max] [)] [/] [2] [;]](image/a-map-of-the-territory/tokens.png)
2 . 1 . 2解析
下一步是解析。在这里,我们的语法获得了语法—将更大的表达式和语句从更小的部分组合起来的能力。你是否曾在英语课上画过句子图?如果是这样,你做了解析器所做的事情,只是英语有成千上万的“关键字”和一个泛滥成灾的歧义性。编程语言要简单得多。
解析器接收标记的扁平序列,并构建一个树结构,该结构反映了语法的嵌套性质。这些树有几个不同的名称—解析树或抽象语法树—具体取决于它们与源语言的裸语法结构的接近程度。在实践中,语言黑客通常称它们为语法树、AST,或者通常只称为树。
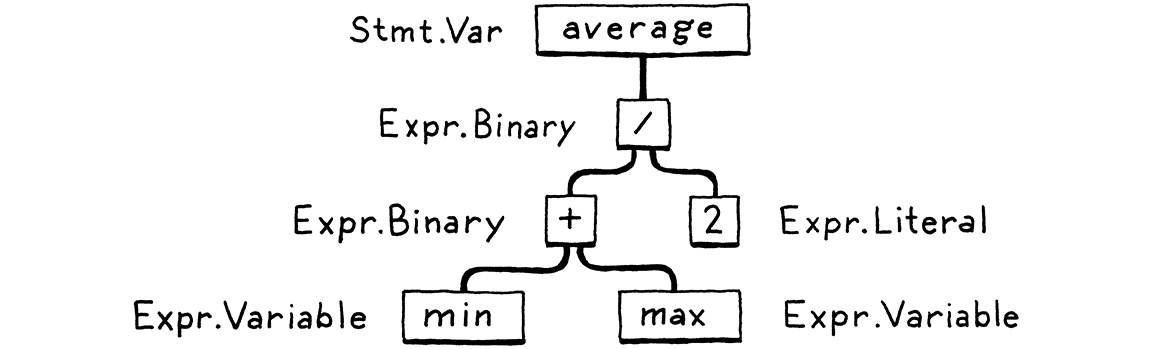
解析在计算机科学中有着悠久而丰富的历史,它与人工智能社区密切相关。今天用于解析编程语言的许多技术最初是为了解析人类语言而由试图让计算机与我们交流的人工智能研究人员提出的。
事实证明,人类语言对于那些解析器能够处理的严格语法来说太混乱了,但它们非常适合编程语言更简单的人工语法。唉,我们有缺陷的人类仍然设法使用这些简单的语法不正确,因此解析器的任务还包括在我们这样做时通过报告语法错误让我们知道。
2 . 1 . 3静态分析
前两个阶段在所有实现中都非常相似。现在,每种语言的个别特征开始发挥作用。此时,我们知道了代码的语法结构—比如哪些表达式嵌套在哪些表达式中—但我们对此知之甚少。
在类似于a + b的表达式中,我们知道我们要添加a和b,但我们不知道这些名称指的是什么。它们是局部变量吗?全局变量吗?它们在哪里定义?
大多数语言执行的第一个分析部分称为绑定或解析。对于每个标识符,我们找出该名称是在哪里定义的,并将两者连接起来。这就是作用域发挥作用的地方—可以使用特定名称来引用特定声明的源代码区域。
如果该语言是静态类型的,那么这就是我们进行类型检查的地方。一旦我们知道a和b是在哪里声明的,我们也可以确定它们的类型。然后,如果这些类型不支持相互加在一起,我们就会报告一个类型错误。
深呼吸。我们已经登上了山顶,可以俯瞰用户的程序。所有这些我们从分析中获得的语义洞察需要存储在某个地方。我们可以将它们存储在几个地方
-
通常,它直接作为属性存储在语法树本身—节点中的额外字段,这些字段在解析过程中没有初始化,而是在以后填充。
-
其他时候,我们可能会将数据存储在一个独立的查找表中。通常情况下,该表的键是标识符—变量和声明的名称。在这种情况下,我们称之为符号表,它与每个键关联的值告诉我们该标识符指的是什么。
-
最强大的簿记工具是将树转换为一个完全不同的数据结构,该结构更直接地表达了代码的语义。这就是下一节的内容。
到目前为止,所有这些都被认为是实现的前端。你可能会猜到,之后的一切都是后端,但事实并非如此。在“前端”和“后端”这些词语诞生之时,编译器要简单得多。后来的研究人员发明了新的阶段,将这些阶段塞入这两个部分之间。与其丢弃旧术语,威廉·沃尔夫及其同事将这些新阶段归类到一个迷人但空间上自相矛盾的名称中间端中。
2 . 1 . 4中间表示
你可以将编译器视为一个管道,每个阶段的任务都是以一种使下一阶段更容易实现的方式组织表示用户代码的数据。管道的前端特定于程序所编写的源语言。后端关注程序将要运行的最终架构。
在中间,代码可能存储在某种中间表示(IR)中,该表示与源形式或目标形式(因此称为“中间”)没有紧密联系。相反,IR充当这两种语言之间的接口。
这让你可以用更少的努力来支持多种源语言和目标平台。假设你想要实现 Pascal、C 和 Fortran 编译器,并且你想要定位 x86、ARM 和(我不知道)SPARC。通常,这意味着你要注册编写九个完整的编译器:Pascal→x86、C→ARM,以及所有其他组合。
一个共享中间表示可以显著减少这些工作量。你为每种源语言编写一个前端,该前端生成 IR。然后为每个目标架构编写一个后端。现在,你可以将它们混合搭配,以获得所有组合。
我们可能想要将代码转换为更清晰地表达语义的形式的另一个重要原因是 . . .
2 . 1 . 5优化
一旦我们了解了用户的程序的含义,我们就可以自由地用另一个具有相同语义但以更高效的方式实现它们的程序来替换它—我们可以对其进行优化。
一个简单的例子是常量折叠:如果某个表达式始终计算结果为完全相同的值,我们可以在编译时进行计算,并用其结果替换表达式的代码。如果用户输入了以下内容
pennyArea = 3.14159 * (0.75 / 2) * (0.75 / 2);
我们可以将所有这些算术运算在编译器中进行,并将代码更改为
pennyArea = 0.4417860938;
优化是编程语言行业的重要组成部分。许多语言黑客将他们的一生都投入到这个领域,从他们的编译器中榨取每一滴性能,让他们的基准测试速度提高几分之一百分点。这可能会成为一种痴迷。
在这本书中,我们基本上会跳过那个老鼠洞。许多成功的语言出乎意料地只有很少的编译时优化。例如,Lua 和 CPython 生成的代码相对没有优化,它们将大部分性能工作集中在运行时。
2 . 1 . 6代码生成
我们已经对用户的程序应用了所有我们能想到的优化。最后一步是将它转换为机器实际可以运行的格式。换句话说,**生成代码**(或**代码生成**),“代码”在这里通常指的是 CPU 运行的那种原始的类似汇编的指令,而不是人类可能想要阅读的“源代码”。
最后,我们来到了**后端**,从山的那一边往下走。从这里开始,我们对代码的表示变得越来越原始,就像逆向运行的进化一样,因为我们越来越接近我们头脑简单的机器所能理解的东西。
我们有一个决定要做出。我们是要为一个真正的 CPU 生成指令,还是为一个虚拟的 CPU 生成指令?如果我们生成真正的机器代码,我们会得到一个操作系统可以直接加载到芯片上的可执行文件。原生代码速度极快,但生成它需要大量工作。今天的架构拥有大量的指令,复杂的流水线,以及足以装满一架 747 飞机行李舱的历史包袱。
说芯片的语言也意味着你的编译器绑定到特定的架构。如果你的编译器针对x86机器代码,它将无法在ARM设备上运行。早在 60 年代,在计算机架构的寒武纪大爆发期间,这种缺乏可移植性就是一个真正的障碍。
为了解决这个问题,像 Martin Richards 和 Niklaus Wirth 这样的黑客(分别是 BCPL 和 Pascal 的创始人)让他们的编译器生成虚拟机器代码。他们不是为某个真正的芯片生成指令,而是为一个假设的、理想化的机器生成代码。Wirth 将其称为p-code,代表portable,但今天,我们通常称之为字节码,因为每条指令通常只有一个字节长。
这些合成指令被设计成更接近于语言的语义,而不是与任何一种计算机架构及其积累的历史糟粕的特性密切相关。你可以把它想象成一种密集的、二进制编码的语言低级操作。
2 . 1 . 7虚拟机
如果你的编译器生成字节码,那么完成这项工作后,你的工作还没有结束。由于没有芯片能够说这种字节码,所以你必须进行翻译。同样,你有两个选择。你可以为每个目标架构编写一个小型编译器,将字节码转换为该机器的原生代码。你仍然需要为每个你支持的芯片做工作,但这个最后阶段非常简单,你可以在你支持的所有机器上重用编译器管道中的其他部分。你基本上是使用字节码作为中间表示。
或者,你可以编写一个虚拟机(VM),一个程序,它在运行时模拟支持你的虚拟架构的假设芯片。在 VM 中运行字节码比提前将其转换为原生代码更慢,因为每条指令在每次执行时都必须在运行时进行模拟。作为回报,你获得了简单性和可移植性。用 C 语言实现你的 VM,你就可以在任何拥有 C 编译器的平台上运行你的语言。这就是我们在本书中构建的第二个解释器的工作方式。
2 . 1 . 8运行时
我们终于将用户的程序锤炼成一种可以执行的格式。最后一步是运行它。如果我们将其编译成机器代码,我们只需告诉操作系统加载可执行文件,然后它就会运行。如果我们将其编译成字节码,我们需要启动 VM 并将程序加载到 VM 中。
在这两种情况下,除了最基本的低级语言外,我们通常需要一些语言在程序运行时提供的服务。例如,如果语言自动管理内存,我们需要一个垃圾收集器来回收未使用的内存。如果我们的语言支持“instance of”测试,这样你就可以看到你拥有什么样的对象,那么我们需要一些表示来跟踪每个对象的类型,以便在执行过程中跟踪它们。
所有这些都在运行时进行,因此它被恰当地称为运行时。在完全编译的语言中,实现运行时的代码直接插入到生成的执行文件中。例如,在Go中,每个编译后的应用程序都包含自己的 Go 运行时副本,直接嵌入到其中。如果语言在解释器或 VM 中运行,那么运行时就位于其中。这就是大多数 Java、Python 和 JavaScript 等语言的实现方式。
2 . 2捷径和备用路线
这就是涵盖你可能实现的每个可能阶段的漫长路径。许多语言确实走遍了整条路线,但也有一些捷径和备用路线。
2 . 2 . 1单遍编译器
一些简单的编译器将解析、分析和代码生成交织在一起,以便它们直接在解析器中生成输出代码,而无需分配任何语法树或其他 IR。这些单遍编译器限制了语言的设计。你没有中间数据结构来存储关于程序的全局信息,你也不重新访问任何先前解析的代码部分。这意味着,只要你看到某个表达式,你都需要知道足够的信息来正确地编译它。
Pascal 和 C 是围绕这个限制设计的。当时,内存非常宝贵,以至于一个编译器甚至可能无法将整个源文件存储在内存中,更不用说整个程序了。这就是 Pascal 的语法要求类型声明出现在块中的首位的原因。这就是在 C 中,你不能在定义函数的代码上方调用函数的原因,除非你有一个显式的向前声明,告诉编译器它需要知道什么才能为对以后函数的调用生成代码。
2 . 2 . 2树遍历解释器
一些编程语言在将代码解析到 AST 后(可能应用了一些静态分析)就开始执行代码。为了运行程序,解释器一次遍历语法树的一个分支和一个叶子,在它遍历时评估每个节点。
这种实现方式在学生项目和小语言中很常见,但在通用语言中并不常见,因为它往往很慢。有些人将“解释器”仅指代这类实现,而另一些人则更一般地定义这个词,所以我将使用不可争辩的明确术语树遍历解释器来指代这些解释器。我们的第一个解释器就是以这种方式工作的。
2 . 2 . 3转译器
编写一个完整的语言后端可能需要大量工作。如果你有一些现有的通用 IR 作为目标,你可以将你的前端连接到它。否则,你似乎陷入了困境。但如果将某个其他源语言视为中间表示会怎样?
你为你的语言编写一个前端。然后,在后端,你没有做所有工作来将语义降低到某个原始的目标语言,而是生成另一个语言的有效源代码字符串,该语言与你的语言一样高级。然后,你使用该语言的现有编译工具作为你的逃生路线,从山顶往下走,直到可以执行的东西。
他们过去称之为源到源编译器或转译器。在将代码编译到 JavaScript 以便在浏览器中运行的语言兴起之后,它们影响了时髦的昵称转译器。
虽然第一个转译器将一种汇编语言转换为另一种,但今天,大多数转译器都针对更高级的语言。在 UNIX 病毒式传播到各种机器之后,就出现了将 C 语言作为输出语言的编译器的悠久传统。C 编译器在任何运行 UNIX 的地方都可以使用,并生成高效的代码,因此以 C 为目标是让你的语言在许多架构上运行的一种好方法。
网页浏览器是当今的“机器”,而它们的“机器码”是 JavaScript,因此如今似乎几乎所有语言都有一个针对 JS 的编译器,因为这是让代码在浏览器中运行的主要方式。
转译器的前端—扫描器和解析器—与其他编译器类似。然后,如果源语言只是目标语言上的一个简单的语法外壳,它可能会完全跳过分析,直接输出目标语言中的类似语法。
如果两种语言在语义上差异更大,您将看到更多完整编译器的典型阶段,包括分析,甚至可能包括优化。然后,在代码生成方面,您不是输出像机器代码这样的二进制语言,而是生成目标语言中语法正确的源代码(实际上是目标代码)字符串。
无论哪种方式,您都将运行生成的代码通过输出语言的现有编译管道,然后您就可以开始了。
2 . 2 . 4即时编译
最后一个不是捷径,而是一种危险的高山攀登,最好留给专家。执行代码的最快方法是将其编译为机器代码,但您可能不知道最终用户的机器支持哪些架构。该怎么办呢?
您可以做 HotSpot Java 虚拟机 (JVM)、Microsoft 的公共语言运行时 (CLR) 和大多数 JavaScript 解释器所做的事情。在最终用户的机器上,当程序加载—无论是从源代码中加载(JS 的情况),还是从 JVM 和 CLR 的平台无关的字节码中加载—您将它编译为其计算机支持的架构的本机代码。自然地,这被称为即时编译。大多数黑客只是说“JIT”,发音与“fit”押韵。
最复杂的 JIT 会在生成的代码中插入性能分析钩子,以查看哪些区域在性能方面最关键以及哪些类型的数据正在流经它们。然后,随着时间的推移,它们将自动使用更高级的优化重新编译这些热点。
2 . 3编译器和解释器
现在我已经用字典里的一堆编程语言术语塞满了你的脑袋,我们终于可以解决一个困扰着程序员自古以来的问题:编译器和解释器的区别是什么?
事实证明,这就像问水果和蔬菜的区别。这似乎是一个二元的非此即彼的选择,但实际上,“水果”是一个植物学术语,“蔬菜”是一个烹饪术语。一个不严格地意味着另一个的否定。有些水果不是蔬菜(苹果),有些蔬菜不是水果(胡萝卜),但也有一些可食用的植物既是水果又是蔬菜,比如西红柿。
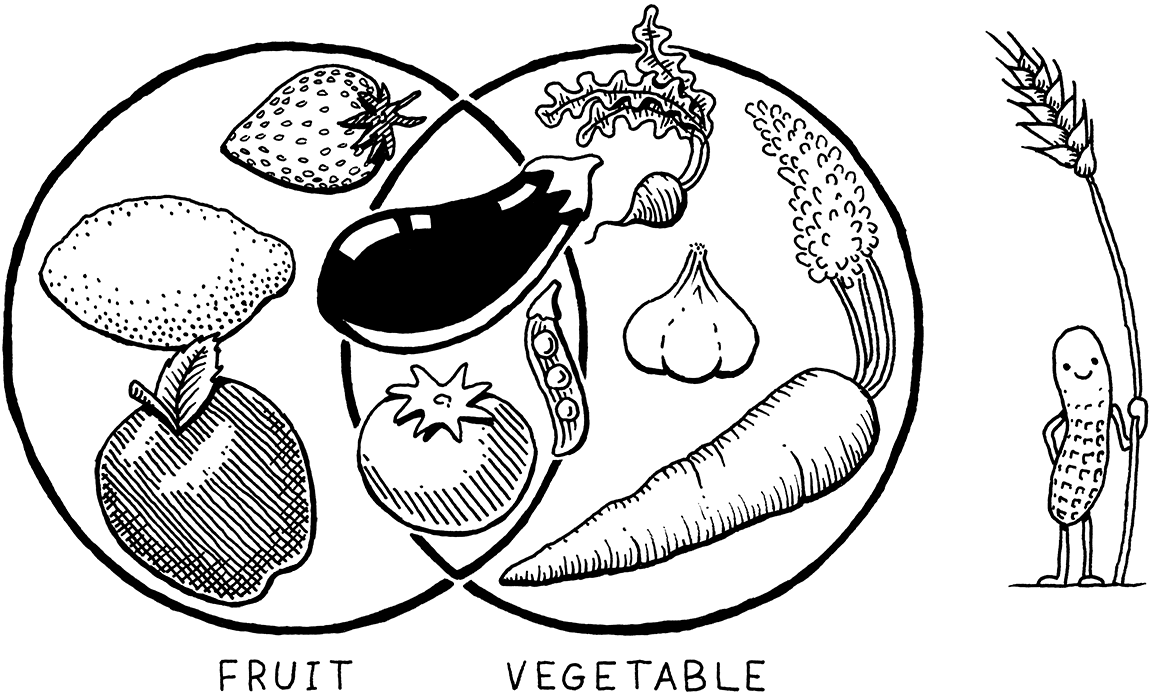
所以,回到语言
-
编译是一种实现技术,它涉及将源语言转换为另一种—通常是更低级别的—形式。当您生成字节码或机器代码时,您正在编译。当您将代码转换为另一种高级语言时,您也在编译。
-
当我们说一种语言实现“是编译器”时,我们的意思是它将源代码转换为另一种形式,但不执行它。用户必须获取生成的输出并自己运行它。
-
相反,当我们说一种实现“是解释器”时,我们的意思是它接受源代码并立即执行它。它从源代码运行程序。
就像苹果和橘子一样,有些实现显然是编译器,而不是解释器。GCC 和 Clang 获取您的 C 代码并将其编译为机器代码。最终用户直接运行该可执行文件,甚至可能不知道使用哪个工具进行编译。因此,它们是 C 的编译器。
在 Matz 的 Ruby 的早期版本中,用户从源代码运行 Ruby。实现会解析它并通过遍历语法树直接执行它。没有进行其他翻译,无论是内部还是对用户可见的形式。因此,这绝对是 Ruby 的解释器。
但是 CPython 呢?当您使用它运行 Python 程序时,代码会被解析并转换为内部字节码格式,然后在 VM 内部执行。从用户的角度来看,这显然是一个解释器—他们从源代码运行他们的程序。但是,如果您查看 CPython 的鳞状皮肤,您会发现确实有一些编译正在进行。
答案是它既是两者。CPython是一个解释器,它也有一个编译器。实际上,大多数脚本语言都是这样工作的,正如您所看到的
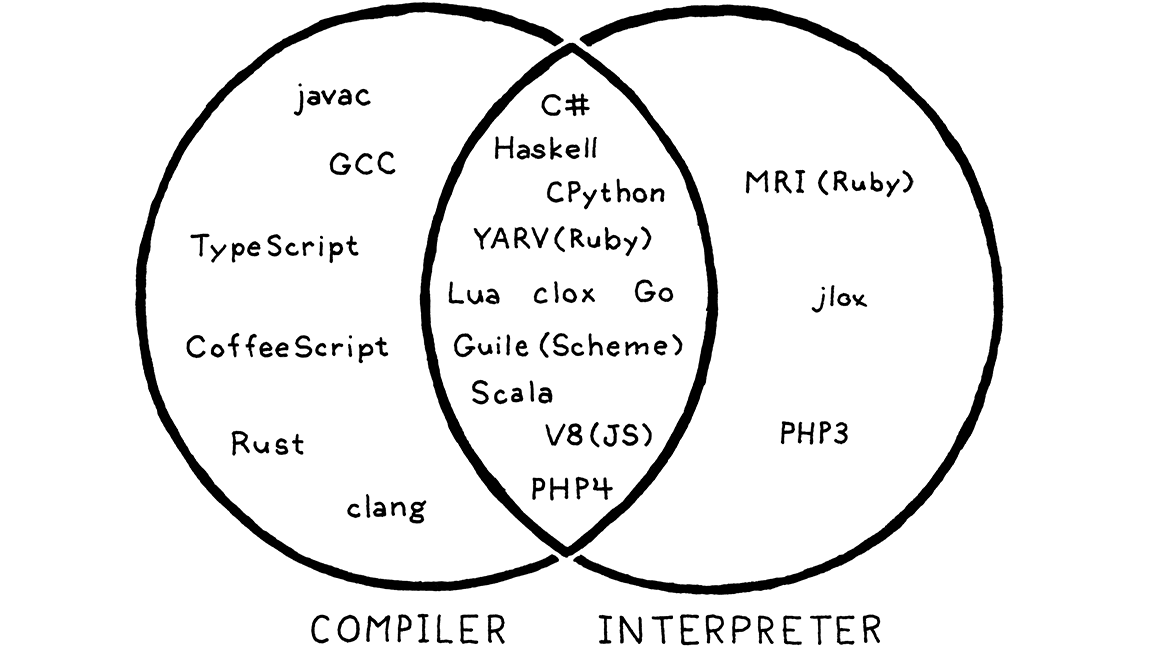
中心的重叠区域也是我们的第二个解释器所在的区域,因为它在内部编译为字节码。因此,虽然本书名义上是关于解释器的,但我们也会涵盖一些编译内容。
2 . 4我们的旅程
一次性接受这么多信息真的很难。别担心。这不是您应该理解所有这些部分的章节。我只是想让您知道它们在那里,以及它们是如何大致组合在一起的。
当您探索本书中引导路径之外的领地时,这张地图应该对您有很大帮助。我希望您渴望独自踏上旅程,在整个山区漫游。
但是,现在,是时候开始我们自己的旅程了。系紧鞋带,背好背包,跟着我走吧。从这里开始,您只需专注于眼前的道路。
挑战
-
选择您喜欢的语言的开源实现。下载源代码并浏览它。尝试找到实现扫描器和解析器的代码。它们是手写的,还是使用 Lex 和 Yacc 等工具生成的?(
.l或.y文件通常表示后者。) -
即时编译往往是实现动态类型语言的最快方法,但并非所有动态类型语言都使用它。不使用 JIT 的原因有哪些?
-
大多数编译为 C 的 Lisp 实现也包含一个解释器,使其能够动态执行 Lisp 代码。为什么?